使用prometheus监控
整体概览:

上图中有 2 个未提及的组件:
-
Longhorn 后端服务是指向 Longhorn manager pods 的服务。Longhorn在 http://LONGHORN_MANAGER_IP:PORT/metrics 的endpoint上暴露了metrics指标。
-
Prometheus operator watch 3个CRD:ServiceMonitor、Prometheus 和 AlertManager。当用户创建这些CRD时,Prometheus Operator会使用用户指定的配置部署和管理Prometheus server, AlerManager。
添加监控
由于使用的是rancher上的监控,所以不用再手动部署Prometheus Operator。直接部署ServiceMonitor即可。创建ServiceMonitor后,Rancher将自动发现所有Longhorn指标。
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: longhorn-prometheus-servicemonitor
namespace: longhorn-system
labels:
name: longhorn-prometheus-servicemonitor
spec:
selector:
matchLabels:
app: longhorn-manager
namespaceSelector:
matchNames:
- longhorn-system
endpoints:
- port: manager注意
使用rancher部署的prometheus,添加了labels,默认只能识别cattle-prometheus,cattle-system的namespace中的serviceMonitor。
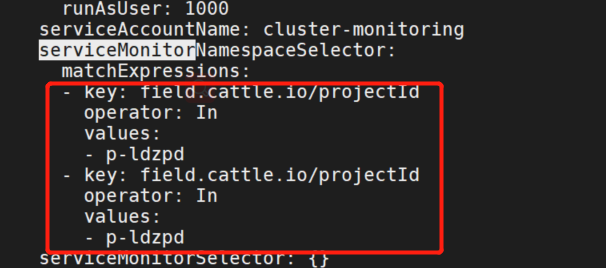

所以上面部署的longhorn-prometheus-servicemonitor 部署在longhorn-system会识别不到。
最简单的是修改namespace到cattle-prometheus。

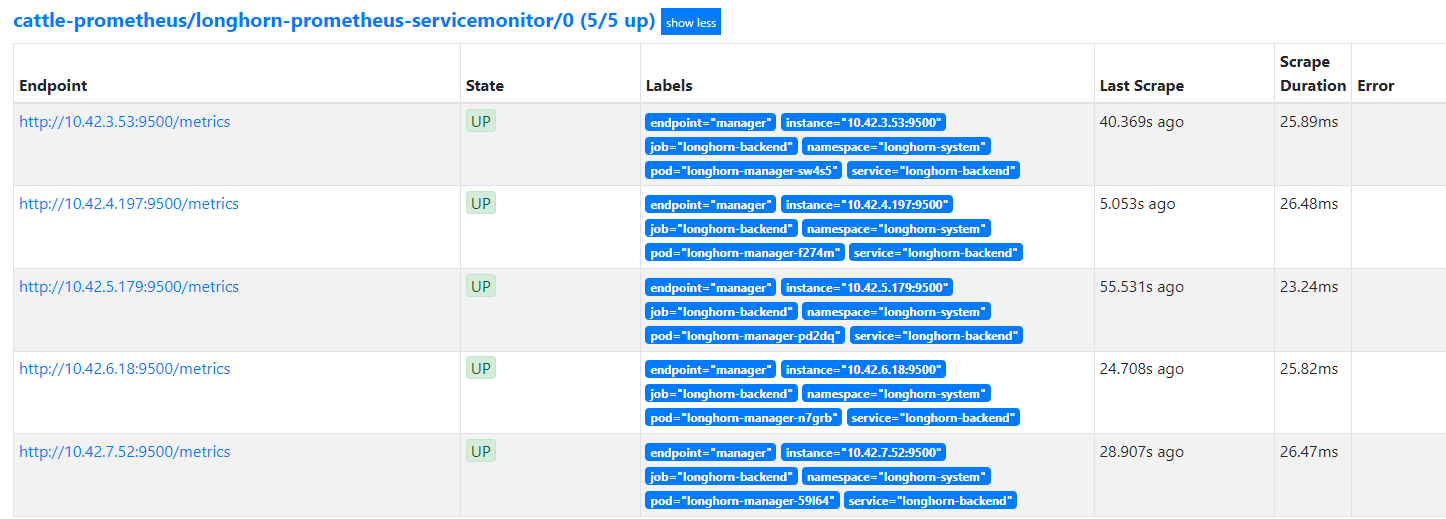
查看target
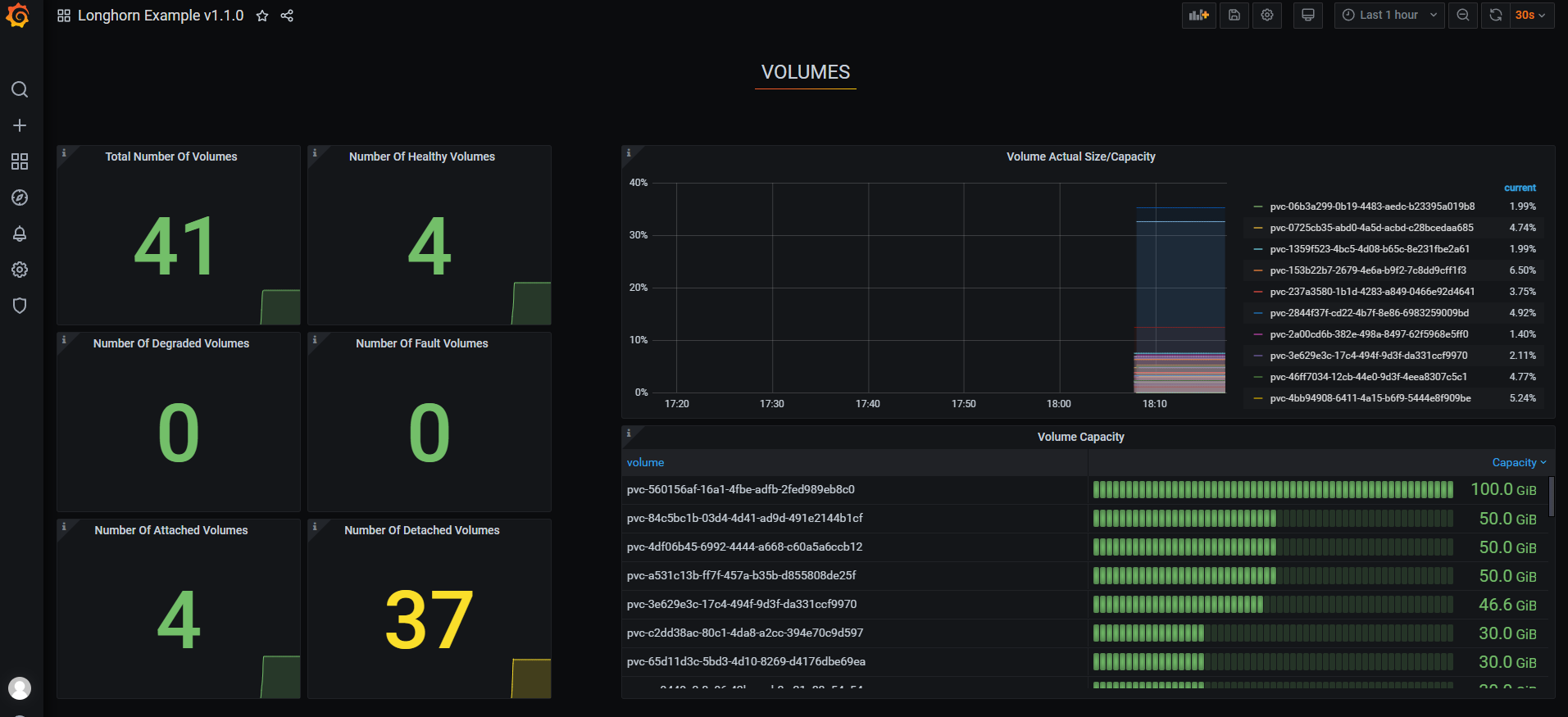
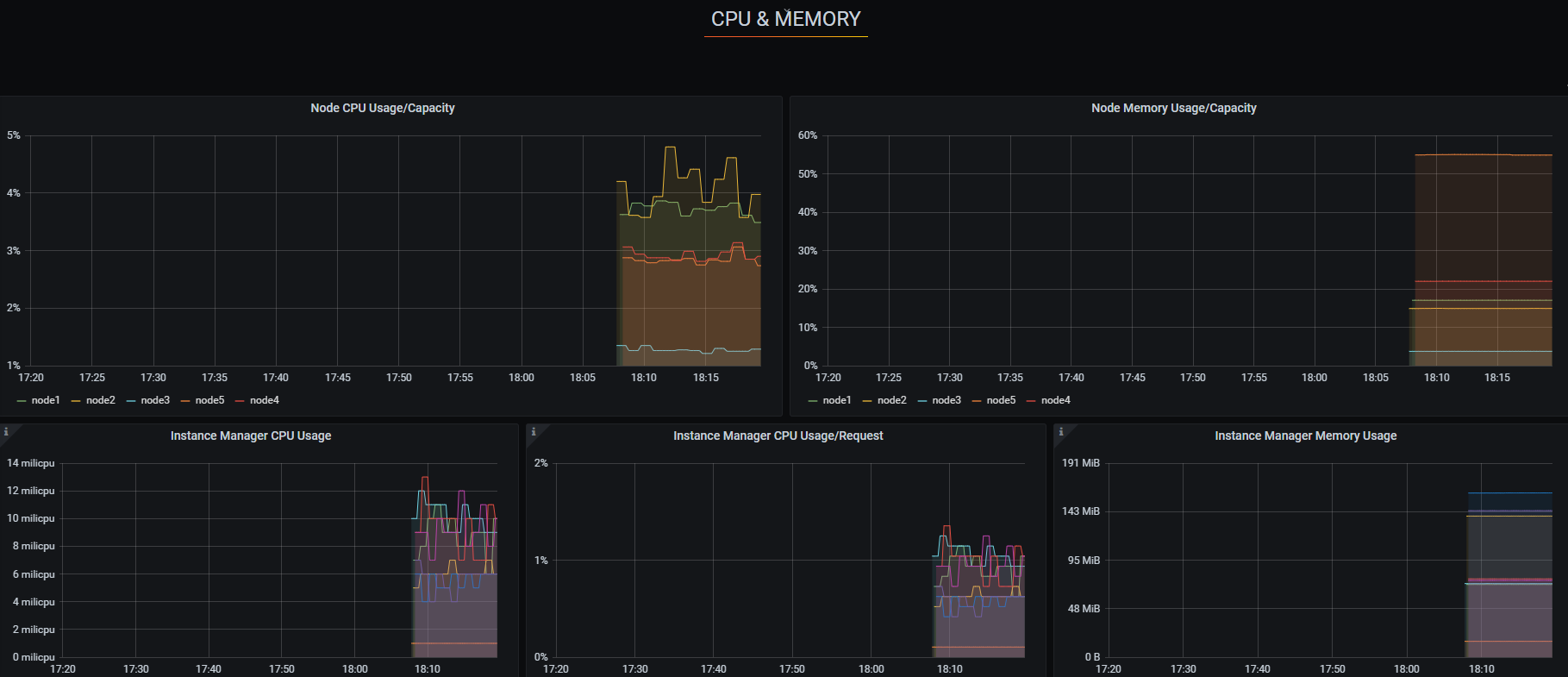
导入grafana模板
13032
volumes
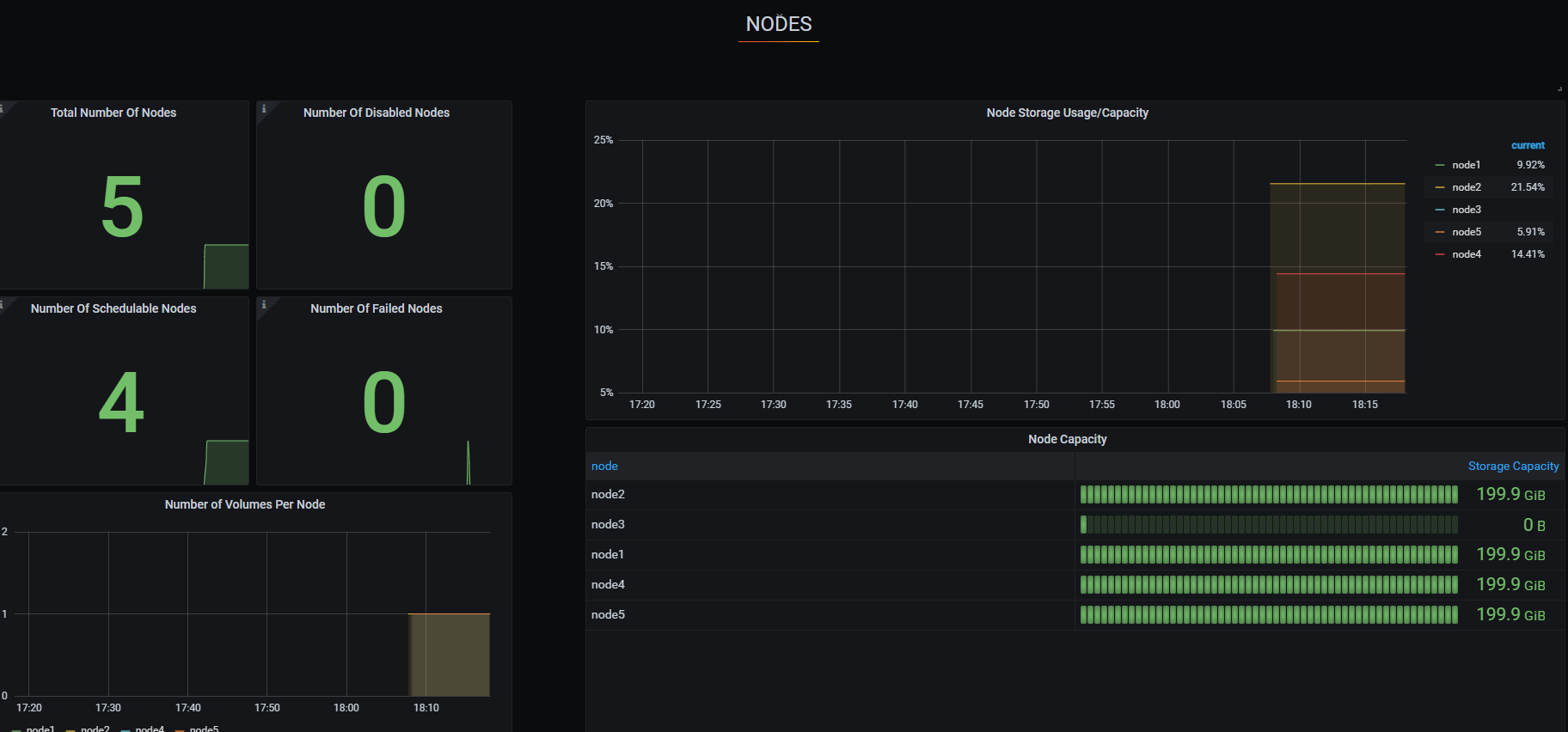
nodes
disks

cpu,mem

告警配置
- 创建PrometheusRule,注意修改labels为你的环境中的监控labels。我这里是rancher的rancher-monitoring。
- 还有prometheus也和上面的serviceMonitor一样配置了selector。可以修改prometheus也可以将PrometheusRule部署在cattle-prometheus ns中。
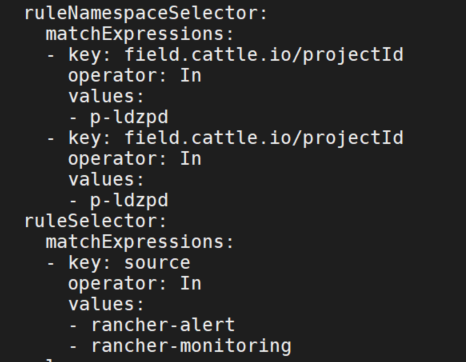
cat prometheus-rule.yaml
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
labels:
app: exporter-kube-controller-manager
chart: exporter-kube-controller-manager-0.0.1
heritage: Tiller
io.cattle.field/appId: cluster-monitoring
release: cluster-monitoring
source: rancher-monitoring
name: prometheus-longhorn-rules
spec:
groups:
- name: longhorn.rules
rules:
- alert: LonghornVolumeActualSpaceUsedWarning
annotations:
description: The actual space used by Longhorn volume {{$labels.volume}} on {{$labels.node}} is at {{$value}}% capacity for
more than 5 minutes.
summary: The actual used space of Longhorn volume is over 90% of the capacity.
expr: (longhorn_volume_actual_size_bytes / longhorn_volume_capacity_bytes) * 100 > 90
for: 5m
labels:
issue: The actual used space of Longhorn volume {{$labels.volume}} on {{$labels.node}} is high.
severity: warning
- alert: LonghornVolumeStatusCritical
annotations:
description: Longhorn volume {{$labels.volume}} on {{$labels.node}} is Fault for
more than 2 minutes.
summary: Longhorn volume {{$labels.volume}} is Fault
expr: longhorn_volume_robustness == 3
for: 5m
labels:
issue: Longhorn volume {{$labels.volume}} is Fault.
severity: critical
- alert: LonghornVolumeStatusWarning
annotations:
description: Longhorn volume {{$labels.volume}} on {{$labels.node}} is Degraded for
more than 5 minutes.
summary: Longhorn volume {{$labels.volume}} is Degraded
expr: longhorn_volume_robustness == 2
for: 5m
labels:
issue: Longhorn volume {{$labels.volume}} is Degraded.
severity: warning
- alert: LonghornNodeStorageWarning
annotations:
description: The used storage of node {{$labels.node}} is at {{$value}}% capacity for
more than 5 minutes.
summary: The used storage of node is over 70% of the capacity.
expr: (longhorn_node_storage_usage_bytes / longhorn_node_storage_capacity_bytes) * 100 > 70
for: 5m
labels:
issue: The used storage of node {{$labels.node}} is high.
severity: warning
- alert: LonghornDiskStorageWarning
annotations:
description: The used storage of disk {{$labels.disk}} on node {{$labels.node}} is at {{$value}}% capacity for
more than 5 minutes.
summary: The used storage of disk is over 70% of the capacity.
expr: (longhorn_disk_usage_bytes / longhorn_disk_capacity_bytes) * 100 > 70
for: 5m
labels:
issue: The used storage of disk {{$labels.disk}} on node {{$labels.node}} is high.
severity: warning
- alert: LonghornNodeDown
annotations:
description: There are {{$value}} Longhorn nodes which have been offline for more than 5 minutes.
summary: Longhorn nodes is offline
expr: (avg(longhorn_node_count_total) or on() vector(0)) - (count(longhorn_node_status{condition="ready"} == 1) or on() vector(0)) > 0
for: 5m
labels:
issue: There are {{$value}} Longhorn nodes are offline
severity: critical
- alert: LonghornIntanceManagerCPUUsageWarning
annotations:
description: Longhorn instance manager {{$labels.instance_manager}} on {{$labels.node}} has CPU Usage / CPU request is {{$value}}% for
more than 5 minutes.
summary: Longhorn instance manager {{$labels.instance_manager}} on {{$labels.node}} has CPU Usage / CPU request is over 300%.
expr: (longhorn_instance_manager_cpu_usage_millicpu/longhorn_instance_manager_cpu_requests_millicpu) * 100 > 300
for: 5m
labels:
issue: Longhorn instance manager {{$labels.instance_manager}} on {{$labels.node}} consumes 3 times the CPU request.
severity: warning
- alert: LonghornNodeCPUUsageWarning
annotations:
description: Longhorn node {{$labels.node}} has CPU Usage / CPU capacity is {{$value}}% for
more than 5 minutes.
summary: Longhorn node {{$labels.node}} experiences high CPU pressure for more than 5m.
expr: (longhorn_node_cpu_usage_millicpu / longhorn_node_cpu_capacity_millicpu) * 100 > 90
for: 5m
labels:
issue: Longhorn node {{$labels.node}} experiences high CPU pressure.
severity: warning
k apply -f prometheus-rule.yaml -n cattle-prometheus
更多监控项参考:
https://longhorn.io/docs/1.3.2/monitoring/metrics/
关于Kubelet Volume Metrics
kubelet暴露了以下volume相关指标:
- kubelet_volume_stats_capacity_bytes
- kubelet_volume_stats_available_bytes
- kubelet_volume_stats_used_bytes
- kubelet_volume_stats_inodes
- kubelet_volume_stats_inodes_free
- kubelet_volume_stats_inodes_used
这些指标表示Longhorn块设备内的PVC文件系统相关信息。它与longhorn_volume_*指标不同,longhorn_volume_*表示Longhorn块设备(block device)的信息。
可以使用kubelet_volume_stats_*metrics 来告警PVC存储空间即将耗尽。
Longhorn CSI 插件支持
在longhorn v1.1.0以上中,Longhorn CSI插件根据CSI spec支持NodeGetVolumeStats RPC调用。
这允许kubelet调用Longhorn CSI插件以获取PVC的状态。
然后 kubelet 在 kubelet_volumestats* 指标中公开该信息。