环境
k8s
两套k8s集群,vip采用的是kube-vip。
第一套:
- master1:192.168.1.1
- master2:192.168.1.2
- master3:192.168.1.3
- vip:192.168.1.4
第二套:
- master1:192.168.1.5
- master2:192.168.1.6
- master3:192.168.1.7
- vip:192.168.1.8
haproxy,keepalived
- 主从模式:一个vip,vip在master机器上,当master机器出现故障后,vip漂移到slave机器上,slave变为master提供服务。
- 主主模式:两个vip,两台机器都设置vip,当其中一台机器出现故障后,它的vip就漂移到另一台机器上(即另一台机器有两个vip),当故障机器恢复后,再将vip重新漂移过来。
所以整体访问链路就是:
外部访问–>keepalived vip–>haproxy–>kube-vip–>master–>ingress–>node–>pod
主主模式
这里先介绍主主模式。
- master:192.168.1.9
- vip1: 192.168.1.10
- backup: 192.168.1.11
- vip2:192.168.1.12
k8s部署略。haproxy
安装
yum -y install haproxy systemctl enable haproxy修改配置
两台haproxy都需要修改。
vim /etc/haproxy/haproxy.cfg global log 127.0.0.1 local2 # 定义haproxy日志输出设置 log 127.0.0.1 local1 notice ulimit-n 65535 # 设置每个进程的可用的最大文件描述符 maxconn 20480 # 默认最大连接数 chroot /var/lib/haproxy # chroot运行路径 user haproxy # 运行haproxy 用户 group haproxy # 运行haproxy 用户组 daemon # 以后台形式运行harpoxy nbproc 1 # 设置进程数量 pidfile /var/run/haproxy.pid # haproxy 进程PID文件 defaults mode http # 所处理的类别(7层代理http,4层代理tcp) log global # 引入global定义的日志格式 maxconn 10240 # 最大连接数 option httplog # 日志类别为http日志格式 option http-server-close #每次请求完毕后主动关闭http通道 option dontlognull # 不记录健康检查日志信息 option forwardfor # 如果后端服务器需要获得客户端的真实ip,需要配置的参数,可以从http header 中获取客户端的IP retries 3 # 3次连接失败就认为服务器不可用,也可以通过后面设置 option redispatch # serverID对应的服务器挂掉后,强制定向到其他健康的服务器, 当使用了cookie时,haproxy将会将其请求的后端服务器的serverID插入到cookie中,以保证会话的SESSION持久性;而此时,如果后端的服务器宕掉了,但是客户端的cookie是不会刷新的,如果设置此参数,将会将客户的请求强制定向到另外一个后端server上,以保证服务的正常 stats refresh 30 #设置统计页面刷新时间间隔 option abortonclose #当服务器负载很高的时候,自动结束掉当前队列处理比较久的连接 balance roundrobin #设置默认负载均衡方式,轮询方式 #balance source #设置默认负载均衡方式,类似于nginx的ip_hash #contimeout 5000 #设置连接超时时间 #clitimeout 50000 #设置客户端超时时间 #srvtimeout 50000 #设置服务器超时时间 timeout http-request 10s #默认http请求超时时间 timeout queue 1m #默认队列超时时间 timeout connect 10s #默认连接超时时间 timeout client 1m #默认客户端超时时间 timeout server 1m #默认服务器超时时间 timeout http-keep-alive 10s #默认持久连接超时时间 timeout check 10s #设置心跳检查超时时间 listen admin_status #Frontend和Backend的组合体,监控组的名称,按需自定义名称 bind 0.0.0.0:8888 #监听服务端口-HAproxy后台管理页面,这个端口可自定义设置,不可用已占用端口 mode http #http的7层模式 log 127.0.0.1 local3 err #错误日志记录 stats refresh 5s #每隔5秒自动刷新监控页面 stats uri /proxy #监控页面的url访问路径,自定义访问路径 stats realm Haproxy\ welcome #监控页面的提示信息 stats auth admin:admin #监控页面的用户和密码admin,可以设置多个用户名 stats hide-version #隐藏统计页面上的HAproxy版本信息 stats admin if TRUE #手工启用/禁用,后端服务器(haproxy-1.4.9以后版本) listen k8s443 bind 0.0.0.0:443 # ingress 443端口 balance roundrobin server vip443-1 172.16.251.250:443 weight 1 cookie 3 check inter 2000 rise 2 fall 5 server vip443-2 172.16.251.251:443 weight 1 cookie 3 check inter 2000 rise 2 fall 5 listen k8s80 bind 0.0.0.0:80 # ingress 80端口 balance roundrobin server vip80-1 172.16.251.250:80 weight 1 cookie 3 check inter 2000 rise 2 fall 5 server vip80-2 172.16.251.251:80 weight 1 cookie 3 check inter 2000 rise 2 fall 5
检查配置文件是否有效:
haproxy -c -f /etc/haproxy/haproxy.cfg
启动
systemctl restart haproxy
systemctl status haproxy访问admin页面
访问:http://192.168.1.9:8888/proxy ,输入用户名密码。
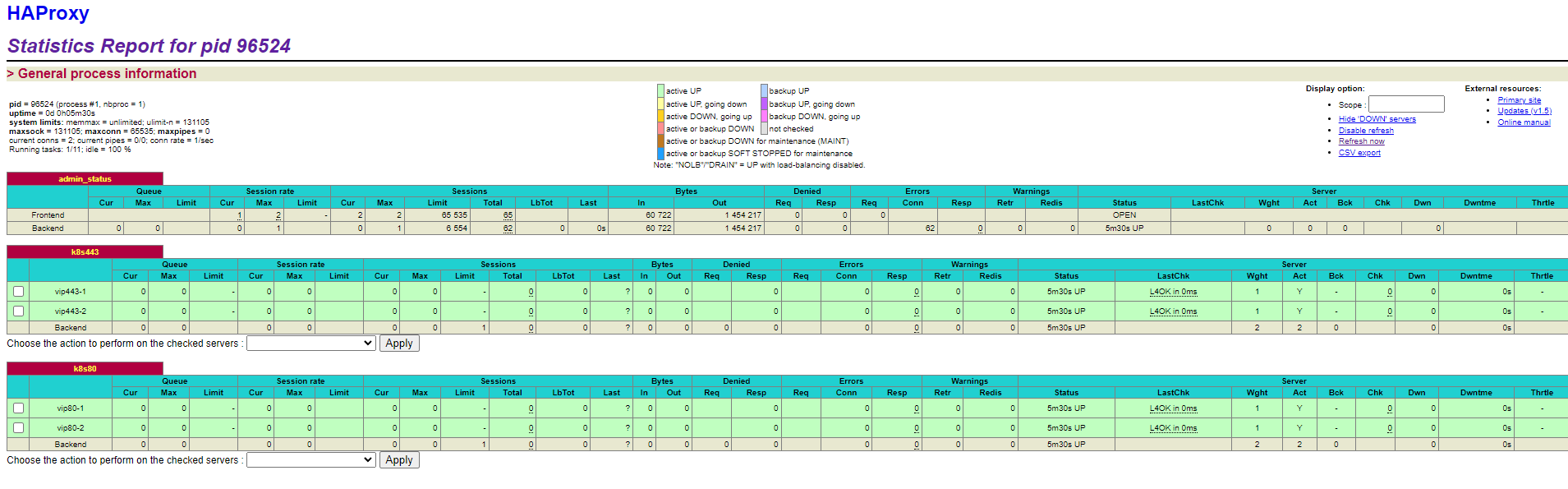
状态都为绿色,即在线。离线显示红色。
haproxy日志配置
安装rsyslog
yum install -y rsyslog修改rsyslog配置
vim /etc/rsyslog.conf
# Provides UDP syslog reception #由于haproxy的日志是用udp传输的,所以要启用rsyslog的udp监听
$ModLoad imudp
$UDPServerRun 514
找到 #### RULES #### 下面添加
local2.* /var/log/haproxy.log重启rsyslog
systemctl restart rsyslog重启haproxy
systemctl restart haproxy查看日志
tail -f /var/log/haproxy.log
keepalived
安装
yum -y install keepalived
systemctl enable keepalived修改master配置
! Configuration File for keepalived
global_defs {
router_id proxy-master # 自定义id不能重复
}
# 定义脚本名字和脚本执行的间隔和脚本执行的优先级变更
vrrp_script chk_haproxy {
script "/etc/keepalived/check_haproxy.sh"
interval 10 # 每10秒执行一次检查脚本
# weight 2
}
# 实例1 是MASTER服务
vrrp_instance VI_1 { # 实例名称也可以自定义,主从必须一致
state MASTER # 配置 HA1 为 Master
interface eth0 # 网卡名称根据自己的改
virtual_router_id 51 # 虚拟路由id,主从必须一致 配置同一个 VRID,范围在 [0-255] 之间
priority 100 # 优先级,MASTER比BACKUP高即可,数字差距尽量大一些
advert_int 1
authentication {
auth_type PASS # 主从保持一致
auth_pass 1111 # 主从保持一致
}
track_script { # 引用脚本
chk_haproxy # 脚本名称与上面定义的名称必须一致
}
virtual_ipaddress { # 虚拟ip地址
192.168.1.10 # 根据自己的修改
}
}
# 实例2 是BACKUP服务器
vrrp_instance VI_2 { # 实例名称也可以自定义,主从必须一致
state BACKUP # 置 HA1 为BACKUP
interface eth0 # 网卡名称根据自己的改
virtual_router_id 61 # 虚拟路由id,主从必须一致
priority 50 # 优先级,MASTER比BACKUP高即可,数字差距尽量大一些
advert_int 1
authentication {
auth_type PASS # 主从保持一致
auth_pass 1111 # 主从保持一致
}
virtual_ipaddress { # 虚拟ip地址
192.168.1.12 # 根据自己的修改
}
}修改backup配置
! Configuration File for keepalived
global_defs {
router_id proxy-backup # 自定义id不能重复
}
# 定义脚本名字和脚本执行的间隔和脚本执行的优先级变更
vrrp_script chk_haproxy {
script "/etc/keepalived/check_haproxy.sh"
# 每5秒执行一次检查脚本
interval 10
# weight 2
}
# 实例1 是BACUP服务
vrrp_instance VI_1 { # 实例名称也可以自定义,主从必须一致
state BACKUP # 设置 HA2 为 Backup
interface eth0 # 网卡名称根据自己的改
virtual_router_id 51 # 虚拟路由id,主从必须一致
priority 50 # 优先级地于master
advert_int 1
authentication {
auth_type PASS # 主从保持一致
auth_pass 1111 # 主从保持一致
}
virtual_ipaddress { # 虚拟ip地址
192.168.1.12 # 根据自己的修改
}
}
# 实例2 是 MASTER 服务器
vrrp_instance VI_2 { # 实例名称也可以自定义,主从必须一致
state MASTER # 设置 HA2 为 MASTER
interface eth0 # 网卡名称根据自己的改
virtual_router_id 61 # 虚拟路由id,主从必须一致
priority 100 # 优先级,MASTER比BACKUP高即可,数字差距尽量大一些
advert_int 1
authentication {
auth_type PASS # 主从保持一致
auth_pass 1111 # 主从保持一致
}
track_script { # 引用脚本
chk_haproxy # # 脚本名称与上面定义的名称必须一致
}
virtual_ipaddress { # 虚拟ip地址
192.168.1.10 # 根据自己的修改
}
}检测haproxy脚本check_haproxy.sh
cat check_haproxy.sh
#!/bin/bash
A=`ps -C haproxy --no-header |wc -l`
if [ $A -eq 0 ];then
systemctl restart haproxy
sleep 3
if [ `ps -C haproxy --no-header |wc -l` -eq 0 ];then
systemctl stop keepalived
fi
fi添加执行权限
chmod a+x /etc/keepalived/chk_haproxy.sh启动keepalived
systemctl start keepalived
systemctl enable keepalived查看ip地址
master:
ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: ens192: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000
link/ether 00:50:56:86:6e:f6 brd ff:ff:ff:ff:ff:ff
inet 192.168.1.9/24 brd 172.16.251.255 scope global noprefixroute ens192
valid_lft forever preferred_lft forever
inet 192.168.1.10/32 scope global ens192
valid_lft forever preferred_lft foreverbackup:
ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: ens192: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000
link/ether 00:50:56:86:6e:f6 brd ff:ff:ff:ff:ff:ff
inet 192.168.1.11/24 brd 172.16.251.255 scope global noprefixroute ens192
valid_lft forever preferred_lft forever
inet 192.168.1.12/32 scope global ens192
valid_lft forever preferred_lft forever测试访问
访问:http://192.168.1.10:8888/proxy ,访问:http://192.168.1.12:8888/proxy
输入用户名密码都可以正常访问。
测试haproxy+keepalived是否正常运行
部署nginx服务,添加域名
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:stable-alpine
---
apiVersion: v1
kind: Service
metadata:
name: nginx
labels:
app: nginx
spec:
type: ClusterIP
ports:
- port: 80
protocol: TCP
name: http
selector:
app: nginx
---
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: nginx-ingress
spec:
ingressClassName: nginx
rules:
- host: nginx.test.com
http:
paths:
- backend:
service:
name: nginx
port:
number: 80
path: /
pathType: Prefix
本地添加解析
将nginx.test.com域名解析添加到两个vip的地址,可以正常访问
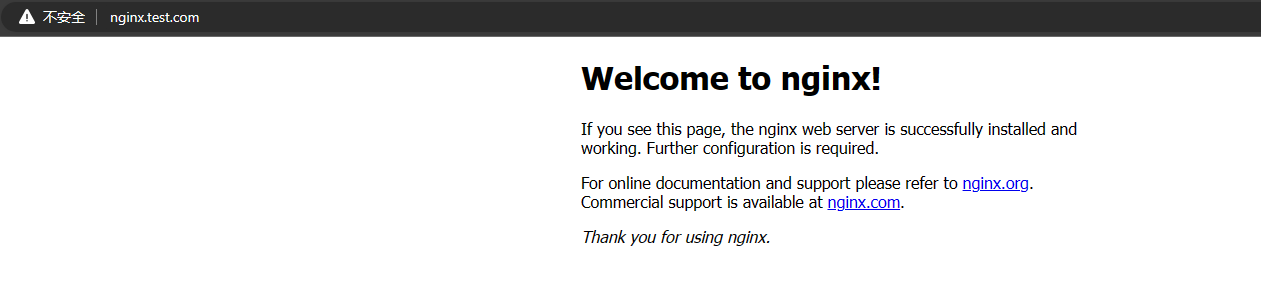
可以看到两个集群的ingress-80都被访问到了。

测试keepalived高可用
关闭master的keepalived服务
systemctl stop keepalived查看日志:

查看master和backup的ip地址,可以看到vip发生了漂移。
master:
ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: ens192: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000
link/ether 00:50:56:86:6e:f6 brd ff:ff:ff:ff:ff:ff
inet 192.168.1.9/24 brd 172.16.251.255 scope global noprefixroute ens192
valid_lft forever preferred_lft foreverbackup:
ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: ens192: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000
link/ether 00:50:56:86:6e:f6 brd ff:ff:ff:ff:ff:ff
inet 192.168.1.9/24 brd 172.16.251.255 scope global noprefixroute ens192
valid_lft forever preferred_lft forever
inet 192.168.1.10/32 scope global eth0
valid_lft forever preferred_lft forever
inet 192.168.1.12/32 scope global eth0测试访问haproxy和nginx服务,都可以正常访问。
重启master的keepalived
可以看到master的vip已经漂移回来了。
master:
ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: ens192: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000
link/ether 00:50:56:86:6e:f6 brd ff:ff:ff:ff:ff:ff
inet 192.168.1.9/24 brd 172.16.251.255 scope global noprefixroute ens192
valid_lft forever preferred_lft forever
inet 192.168.1.10/32 scope global eth0
valid_lft forever preferred_lft foreverbackup同理。
测试停止haproxy
关闭master的haproxy服务。
ps aux | grep haproxy
systemctl stop haproxy
过一会可以看到haproxy重新启动了。

主从模式
主从环境相比于主主环境,区别只在于keepalived.conf的配置不同,其他的配置都和主主模式下的一样,并且主从环境下只有一个VIP(默认在Master端配置)
master:
! Configuration File for keepalived
global_defs {
router_id proxy-master # 自定义id不能重复
}
# 定义脚本名字和脚本执行的间隔和脚本执行的优先级变更
vrrp_script chk_haproxy {
script "/etc/keepalived/check_haproxy.sh"
interval 10 # 每10秒执行一次检查脚本
# weight 2
}
# 实例1 是MASTER服务
vrrp_instance VI_1 { # 实例名称也可以自定义,主从必须一致
state MASTER # 配置 HA1 为 Master
interface ens192 # 网卡名称根据自己的改
virtual_router_id 51 # 虚拟路由id,主从必须一致 配置同一个 VRID,范围在 [0-255] 之间
priority 100 # 优先级,MASTER比BACKUP高即可,数字差距尽量大一些
advert_int 1
authentication {
auth_type PASS # 主从保持一致
auth_pass 1111 # 主从保持一致
}
track_script { # 引用脚本
chk_haproxy # 脚本名称与上面定义的名称必须一致
}
virtual_ipaddress { # 虚拟ip地址
192.168.1.10 # 根据自己的修改
}
}backup:
! Configuration File for keepalived
global_defs {
router_id proxy-backup # 自定义id不能重复
}
# 定义脚本名字和脚本执行的间隔和脚本执行的优先级变更
vrrp_script chk_haproxy {
script "/etc/keepalived/check_haproxy.sh"
# 每5秒执行一次检查脚本
interval 10
# weight 2
}
# 实例1 是BACUP服务
vrrp_instance VI_1 { # 实例名称也可以自定义,主从必须一致
state BACKUP # 设置 HA2 为 Backup
interface eth0 # 网卡名称根据自己的改
virtual_router_id 51 # 虚拟路由id,主从必须一致
priority 50 # 优先级地于master
advert_int 1
authentication {
auth_type PASS # 主从保持一致
auth_pass 1111 # 主从保持一致
}
virtual_ipaddress { # 虚拟ip地址
192.168.1.10 # 根据自己的修改
}
}
这样只有一个vip:192.168.1.10。在master上查看ip地址:
ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: ens192: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000
link/ether 00:50:56:86:6e:f6 brd ff:ff:ff:ff:ff:ff
inet 192.168.1.9/24 brd 172.16.251.255 scope global noprefixroute ens192
valid_lft forever preferred_lft forever
inet 192.168.1.10/32 scope global eth0
valid_lft forever preferred_lft forever参数优化
haproxy
- maxconn 最大连接数,根据应用实际情况进行调整,推荐使用10240,也可以65535。
- daemon 守护进程模式,Haproxy可以使用非守护进程模式启动,建议使用守护进程模式启动。
- nbproc 负载均衡的并发进程数,建议与当前服务器CPU核数相等或为其2倍。
- retries 重试次数,主要用于对集群节点的检查,如果节点多,且并发量大,设置为2次或3次。
- option http-server-close 主动关闭http请求选项,建议在生产环境中使用此选项。
- timeout http-keep-alive 长连接超时时间,设置长连接超时时间,可以设置为10s。
- timeout http-request http请求超时时间,建议将此时间设置为5~10s,增加http连接释放速度。
- timeout client 客户端超时时间,如果访问量过大,节点响应慢,可以将此时间设置短一些,建议设置为1min左右就可以了。
内核
# 设置本地端口范围,默认是从32768到60999。
echo 1024 60999 > /proc/sys/net/ipv4/ip_local_port_range
# 设置TCP连接的关闭超时时间,默认是60s。它表示在接收到连接关闭请求后,内核将等待多长时间来确认关闭请求的对方是否确认了关闭。如果在指定的超时时间内没有收到对方的确认,内核将重新发送关闭请求。
echo 30 > /proc/sys/net/ipv4/tcp_fin_timeout
# 设置TCP SYN(同步)队列的最大长度,默认是256。当客户端向服务器发送连接请求时,服务器会将请求放入SYN队列中等待处理。当SYN队列已满时,服务器将无法接受新的连接请求,导致客户端的连接请求被丢弃或被延迟处理。linux 是没有办法修改MSL的,tcp_fin_timeout 不是2MSL 而是Fin-WAIT-2状态.
echo 4096 > /proc/sys/net/ipv4/tcp_max_syn_backlog
# 设置TCP TIME-WAIT(等待)状态的最大桶(bucket)数量。该参数定义了内核可以同时处理的TIME-WAIT状态的最大数量。每个TIME-WAIT状态的连接都会占用一个桶,而超过设定的最大桶数后,新的TIME-WAIT连接将被丢弃或不再进入TIME-WAIT状态。默认是32768。
echo 262144 > /proc/sys/net/ipv4/tcp_max_tw_buckets
# 设置内核允许存在的最大孤立的TCP连接数量。当客户端或服务器端异常终止时,连接可能会变为孤立状态,即没有与之关联的进程或应用程序。当达到这个阈值时,新的孤立连接将被丢弃。这是为了防止系统资源被无限制地占用。默认是32768。
echo 262144 > /proc/sys/net/ipv4/tcp_max_orphans
# 设置TCP空闲连接在没有数据传输的情况下的超时时间。TCP Keep-Alive是一种机制,用于检测处于空闲状态的TCP连接是否仍然有效。当一段时间内没有数据在连接上进行传输时,Keep-Alive 机制会发送特殊的探测数据包给对端,以验证连接是否仍然保持活动状态。默认是7200s。
echo 300 > /proc/sys/net/ipv4/tcp_keepalive_time
# 用于启用或禁用TCP TIME-WAIT状态的快速回收(Fast Recovery)机制。如果该参数被启用,内核将尝试重用处于TIME-WAIT状态的连接资源,以便更快地处理新的连接请求。默认是0禁用的。
# echo 1 > /proc/sys/net/ipv4/tcp_tw_recycle
# 用于启用或禁用TCP时间戳(Timestamp)选项。TCP时间戳选项是一种用于增强TCP协议性能和安全性的机制。当启用TCP时间戳选项时,TCP报文头部会包含一个时间戳字段,用于记录报文的发送和接收时间。时间戳可以改善TCP流量控制和拥塞控制,抵御TCP序列号预测攻击。默认是1启用的。