CronJob控制器的工作是定期在Kubernetes集群上运行定时任务。它是以Job控制器为基础实现的,而Job控制器的任务是运行一次性的任务,确保它们完成。下面介绍如何使用Kubebuilder重写。
构建CronJob
创建项目
使用域名wgh.io,api group是wgh.io/project。
kubebuilder init --domain wgh.io --repo wgh.io/project
# 项目名称默认为当前工作目录的名称。可以使用 --project-name=<dns1123-label-string> 以设置不同的项目名称。
# 如果项目目录在GOPATH,则隐式调用go mod init填充模块路径。否则 --repo=<module path> 必须设置。执行后报错:FATA failed to initialize project: unable to run post-scaffold tasks of "base.go.kubebuilder.io/v4": exit status 1
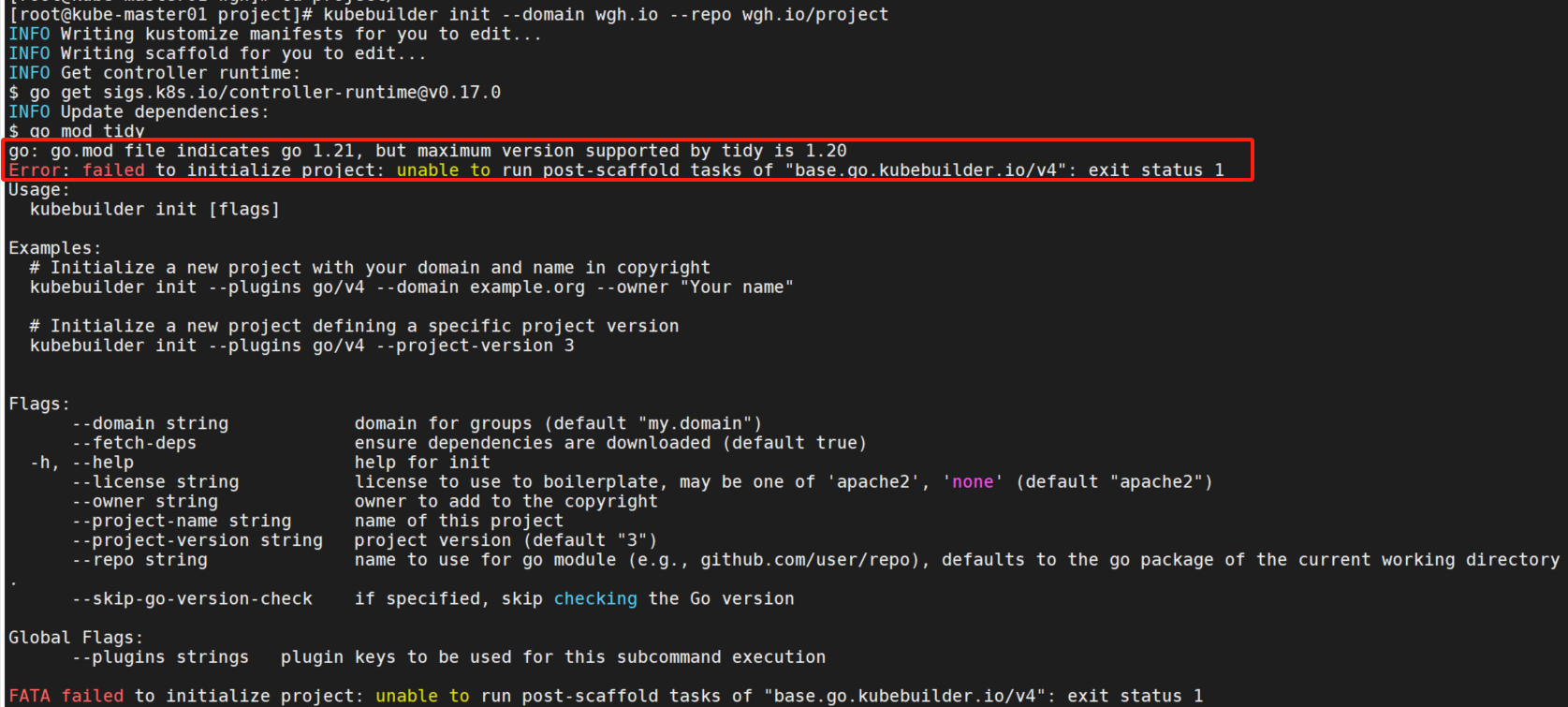
日志显示是在执行go mod tidy后报错的,手动执行go mod tidy同样报错,查看go.mod发现版本是go 1.21,而我的环境是go 1.20.14。

查看kubebuilder的版本信息,发现最新的3.14.0版本支持了go 1.21。
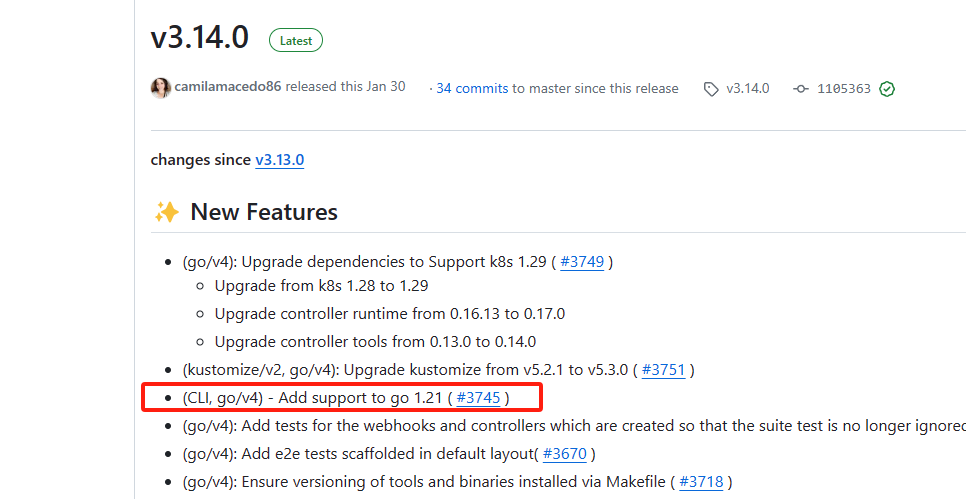
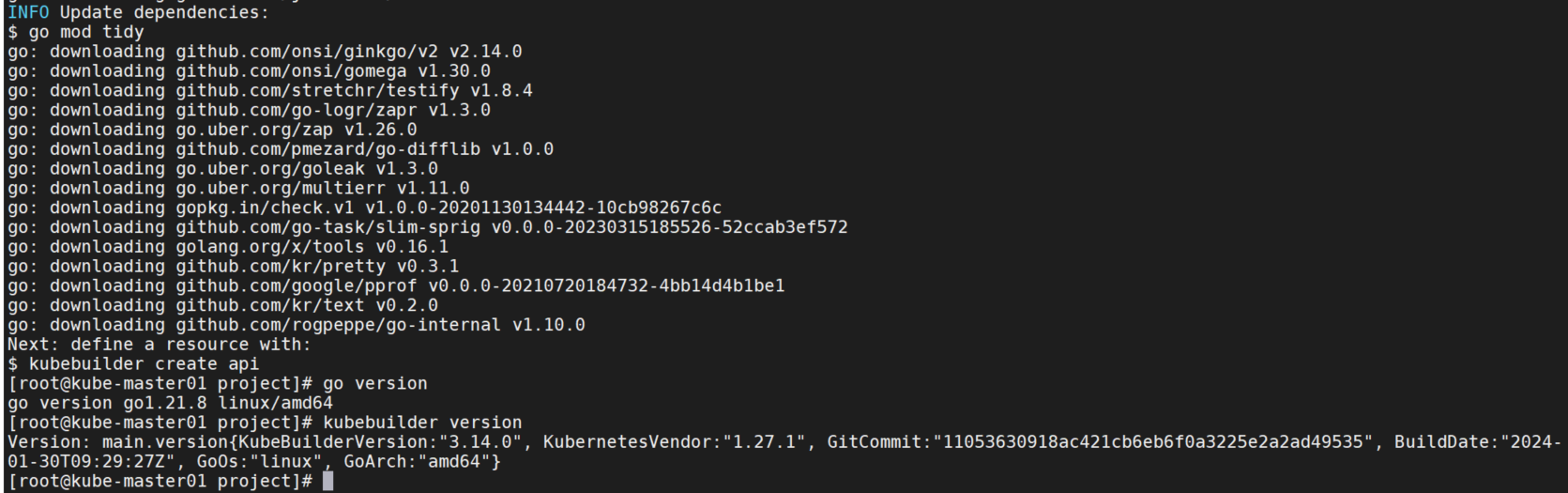
解决:升级go版本到1.21,或者使用低版本的kubebuilder。我这里是升级了go版本。重新创建初始化后成功。
目录结构
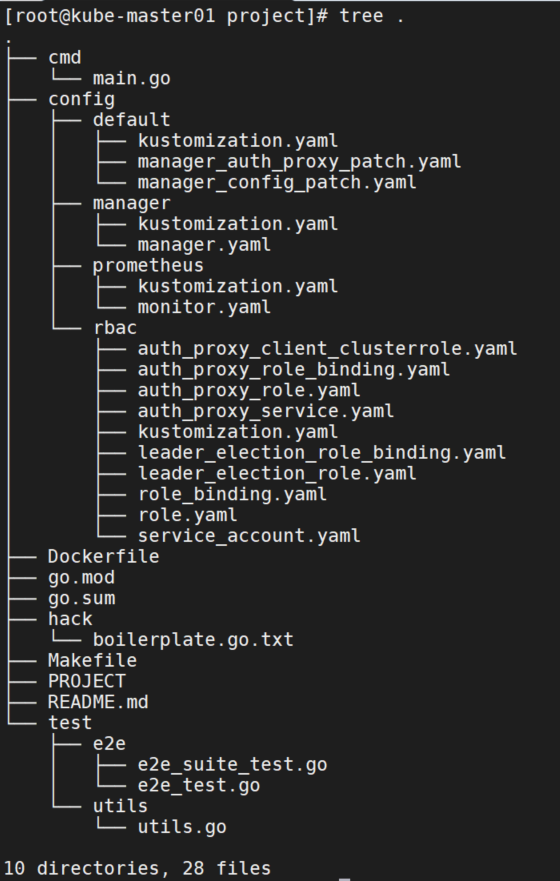
- go.mod: 项目的go模块依赖信息。
- Makefile: 用于控制器构建和部署的Makefile文件
- PROJECT: 用于搭建新组件的Kubebuilder元数据
- config目录:包含启动配置。它只包含了在集群上启动控制器所需的
Kustomize YAML定义,但一旦我们开始编写控制器,它还将包含我们的CustomResourceDefinitions(CRD) 、RBAC 配置和 WebhookConfigurations。 - config/default:包含用于在标准配置中启动控制器的 Kustomize 基础。
- config/manager: 在集群中以pod的形式启动控制器。
- config/rbac: 在控制器自己的服务帐户下运行控制器所需的权限。
main.go
下面解释一下代码。
模块
首先导入了一些库,包括核心的控制器运行时库,默认的控制器运行时日志库Zap等。
import (
"crypto/tls"
"flag"
"os"
// Import all Kubernetes client auth plugins (e.g. Azure, GCP, OIDC, etc.)
// to ensure that exec-entrypoint and run can make use of them.
_ "k8s.io/client-go/plugin/pkg/client/auth"
"k8s.io/apimachinery/pkg/runtime"
utilruntime "k8s.io/apimachinery/pkg/util/runtime"
clientgoscheme "k8s.io/client-go/kubernetes/scheme"
ctrl "sigs.k8s.io/controller-runtime"
"sigs.k8s.io/controller-runtime/pkg/healthz"
"sigs.k8s.io/controller-runtime/pkg/log/zap"
metricsserver "sigs.k8s.io/controller-runtime/pkg/metrics/server"
"sigs.k8s.io/controller-runtime/pkg/webhook"
//+kubebuilder:scaffold:imports
)变量及初始化
- 创建了一个Scheme,用于定义和管理不同API版本的资源对象(如Pods, Deployments等)之间的关系和转换。
- 创建一个新的日志记录器实例,这个日志记录器会带有一个"setup"的名称前缀,用于在初始化过程中记录相关日志。
- init函数是Go语言中的一个特殊函数,它会在程序启动时自动执行,通常用于执行初始化任务。
- 在init函数内部,调用
utilruntime.Must(clientgoscheme.AddToScheme(scheme))将客户端Go库(client-go)默认支持的资源类型添加到之前创建的Scheme中。utilruntime.Must是一个辅助函数,它会在传入的函数返回错误时触发panic,这样可以确保如果资源类型添加失败,程序会立即停止运行。
var (
scheme = runtime.NewScheme()
setupLog = ctrl.Log.WithName("setup")
)
func init() {
utilruntime.Must(clientgoscheme.AddToScheme(scheme))
//+kubebuilder:scaffold:scheme
}主函数
- 使用flag包来解析命令行参数。这包括指标绑定地址、健康探针绑定地址、是否启用领导者选举、是否安全提供指标、是否启用HTTP/2等选项。
- 使用zap日志库来设置日志记录器,其中包括一个开发模式的选项。
- 如果
enableHTTP2标志被设置为false(默认值),则会禁用HTTP/2。这是出于安全考虑,以防止HTTP/2的一些已知漏洞,如HTTP/2流取消和快速重置CVEs。通过修改TLS配置来实现禁用HTTP/2,确保只使用HTTP/1.1协议。 - 创建一个Webhook服务器实例,其中包括TLS配置选项。如果
enableHTTP2为false,则会应用之前定义的禁用HTTP/2的配置。 - 通过ctrl.NewManager函数创建一个新的管理器实例。
ctrl.Options结构体中包含了多个配置选项。 //+kubebuilder:scaffold:builder是一个特殊的注释,用于指示kubebuilder工具在这里添加生成的控制器代码。- 执行健康检查,就绪检查。
- 记录管理器启动中的日志。
- 启动管理器,并传入一个信号处理器。这个信号处理器用于捕获系统信号(如SIGTERM),以便在接收到停止信号时优雅地关闭管理器。
func main() {
var metricsAddr string
var enableLeaderElection bool
var probeAddr string
var secureMetrics bool
var enableHTTP2 bool
flag.StringVar(&metricsAddr, "metrics-bind-address", ":8080", "The address the metric endpoint binds to.")
flag.StringVar(&probeAddr, "health-probe-bind-address", ":8081", "The address the probe endpoint binds to.")
flag.BoolVar(&enableLeaderElection, "leader-elect", false,
"Enable leader election for controller manager. "+
"Enabling this will ensure there is only one active controller manager.")
flag.BoolVar(&secureMetrics, "metrics-secure", false,
"If set the metrics endpoint is served securely")
flag.BoolVar(&enableHTTP2, "enable-http2", false,
"If set, HTTP/2 will be enabled for the metrics and webhook servers")
opts := zap.Options{
Development: true,
}
opts.BindFlags(flag.CommandLine)
flag.Parse()
ctrl.SetLogger(zap.New(zap.UseFlagOptions(&opts)))
// if the enable-http2 flag is false (the default), http/2 should be disabled
// due to its vulnerabilities. More specifically, disabling http/2 will
// prevent from being vulnerable to the HTTP/2 Stream Cancelation and
// Rapid Reset CVEs. For more information see:
// - https://github.com/advisories/GHSA-qppj-fm5r-hxr3
// - https://github.com/advisories/GHSA-4374-p667-p6c8
disableHTTP2 := func(c *tls.Config) {
setupLog.Info("disabling http/2")
c.NextProtos = []string{"http/1.1"}
}
tlsOpts := []func(*tls.Config){}
if !enableHTTP2 {
tlsOpts = append(tlsOpts, disableHTTP2)
}
webhookServer := webhook.NewServer(webhook.Options{
TLSOpts: tlsOpts,
})
mgr, err := ctrl.NewManager(ctrl.GetConfigOrDie(), ctrl.Options{
Scheme: scheme,
Metrics: metricsserver.Options{
BindAddress: metricsAddr,
SecureServing: secureMetrics,
TLSOpts: tlsOpts,
},
WebhookServer: webhookServer,
HealthProbeBindAddress: probeAddr,
LeaderElection: enableLeaderElection,
LeaderElectionID: "eb629c23.wgh.io",
// LeaderElectionReleaseOnCancel defines if the leader should step down voluntarily
// when the Manager ends. This requires the binary to immediately end when the
// Manager is stopped, otherwise, this setting is unsafe. Setting this significantly
// speeds up voluntary leader transitions as the new leader don't have to wait
// LeaseDuration time first.
//
// In the default scaffold provided, the program ends immediately after
// the manager stops, so would be fine to enable this option. However,
// if you are doing or is intended to do any operation such as perform cleanups
// after the manager stops then its usage might be unsafe.
// LeaderElectionReleaseOnCancel: true,
})
if err != nil {
setupLog.Error(err, "unable to start manager")
os.Exit(1)
}
//+kubebuilder:scaffold:builder
if err := mgr.AddHealthzCheck("healthz", healthz.Ping); err != nil {
setupLog.Error(err, "unable to set up health check")
os.Exit(1)
}
if err := mgr.AddReadyzCheck("readyz", healthz.Ping); err != nil {
setupLog.Error(err, "unable to set up ready check")
os.Exit(1)
}
setupLog.Info("starting manager")
if err := mgr.Start(ctrl.SetupSignalHandler()); err != nil {
setupLog.Error(err, "problem running manager")
os.Exit(1)
}
}可以通过Manager以下方式限制所有控制器将监视资源的命名空间:
mgr, err := ctrl.NewManager(ctrl.GetConfigOrDie(), ctrl.Options{
Scheme: scheme,
Cache: cache.Options{
DefaultNamespaces: map[string]cache.Config{
namespace: {},
},
},
Metrics: server.Options{
BindAddress: metricsAddr,
},
WebhookServer: webhook.NewServer(webhook.Options{Port: 9443}),
HealthProbeBindAddress: probeAddr,
LeaderElection: enableLeaderElection,
LeaderElectionID: "eb629c23.wgh.io",
})或者只监听部分namespace:
var namespaces []string // List of Namespaces
defaultNamespaces := make(map[string]cache.Config)
for _, ns := range namespaces {
defaultNamespaces[ns] = cache.Config{}
}
mgr, err := ctrl.NewManager(ctrl.GetConfigOrDie(), ctrl.Options{
Scheme: scheme,
Cache: cache.Options{
DefaultNamespaces: defaultNamespaces,
},GVK/GVR
GVK = Group Version Kind
GVR = Group Version Resources
- group组简单来说就是相关功能的集合。每个组都有一个或多个版本version。
- 每个version包含一个或多个API类型,即为Kinds。
- resources资源只是API中的一个Kind的使用方式。通常情况下,Kind和resources之间有一个一对一的映射。 例如,pods资源对应于Pod种类。但是有时,同一类型可能由多个资源返回。例如, Scale Kind由所有scale子资源返回,例如
deployments/scale或replicasets/scale。但是,对于CRD,每个Kind将对应于单个资源。 - resources总是用小写,按照惯例是Kind的小写形式。
Scheme是什么?
Scheme是一种追踪Go Type的方法,它对应于给定的GVK。
例如,假设我们将wgh.io/api/v1".CronJob{}类型放置在batch.wgh.io/v1API 组中(也就是说它有 CronJob Kind)。
然后,我们便可以在API server给定的json数据构造一个新的&CronJob{}。
{
"kind": "CronJob",
"apiVersion": "batch.wgh.io/v1",
...
}或当我们在一次变更中去更新或提交&CronJob{}时,查找正确的组版本。
创建API
使用kubebuilder create api命令,使用方法如下:
创建CronJob API,按 y 创建资源和控制器。
kubebuilder create api --group batch --version v1 --kind CronJob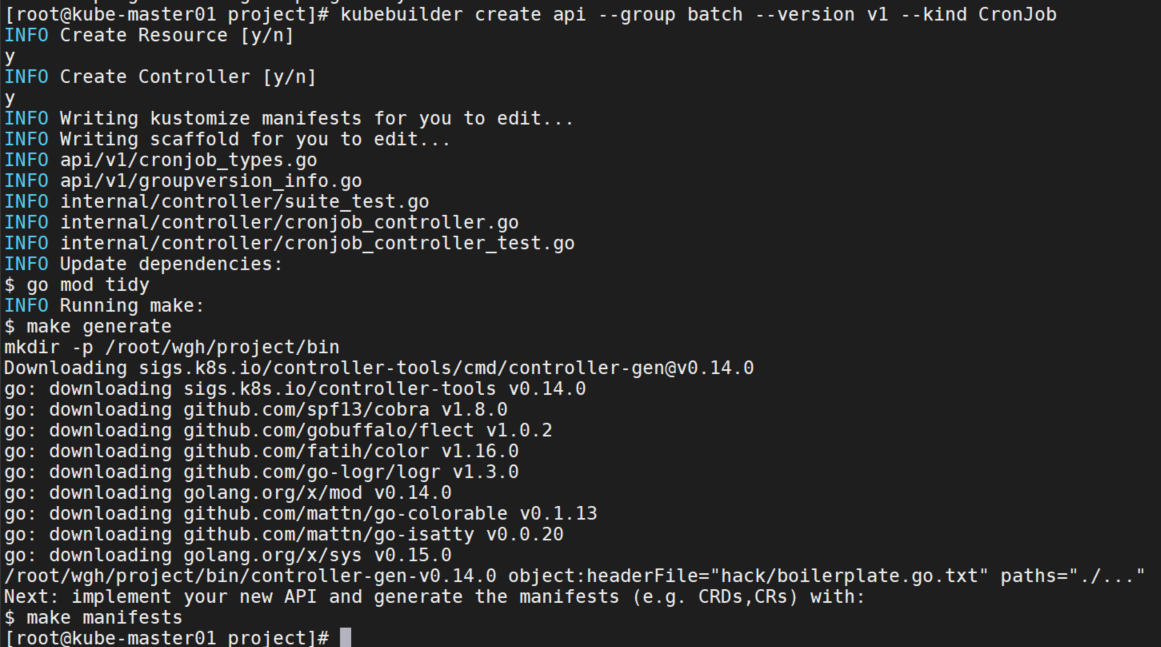
因为前面创建的域名是wgh.io/v1,所以这里会自动创建一个api/v1/目录。它还为CronJob Kind添加了一个api/v1/cronjob_types.go文件,每次我们用不同的类型调用命令时,它都会添加一个相应的新文件。下面分析一下这个文件:
首先一段License,这个略过。下面导入几个包,它包含所有Kubernetes类型通用的元数据。
package v1
import (
batchv1 "k8s.io/api/batch/v1"
corev1 "k8s.io/api/core/v1"
metav1 "k8s.io/apimachinery/pkg/apis/meta/v1"
)下一步,定义了Spec和Status类型。Kubernetes将期待的状态(Spec)与实际集群状态(其他对象的 Status)和外部状态相协调,然后记录观察到的状态(Status)。 因此,每个functional对象包括Spec和Status。很少的类型,像ConfigMap不需要遵从这个模式,因为它们没有期待的状态,但是大部分类型需要做这一步。
一般来说,只需要修改Spec和Status。
// 编辑这个文件!这是你拥有的脚手架!
// 注意: json 标签是必需的。为了能够序列化字段,任何你添加的新的字段必须有json标签。
// CronJobSpec 定义了 CronJob 期待的状态
type CronJobSpec struct {
// INSERT ADDITIONAL SPEC FIELDS - desired state of cluster
// Important: Run "make" to regenerate code after modifying this file
// Foo is an example field of CronJob. Edit cronjob_types.go to remove/update
Foo string `json:"foo,omitempty"`
}
// CronJobStatus 定义了 CronJob 观察的的状态
type CronJobStatus struct {
// INSERT ADDITIONAL STATUS FIELD - define observed state of cluster
// Important: Run "make" to regenerate code after modifying this file
}下一步,我们定义与实际Kinds相对应的类型,CronJob和CronJobList。CronJob 是一个根类型, 它描述了CronJob类型。像所有 Kubernetes 对象,它包含TypeMeta (描述了API版本和种类),也包含其中拥有像名称,命名空间和标签等的ObjectMeta。
//+kubebuilder:object:root=true
# 标记。这个特定的类型告诉object生成器,此类型代表Kind。然后,object生成器生成` runtime.Object`接口的实现。这是所有表示该类型都必须实现的标准接口。
//+kubebuilder:subresource:status
// CronJob 是 cronjobs API 的 Schema
type CronJob struct {
metav1.TypeMeta `json:",inline"`
metav1.ObjectMeta `json:"metadata,omitempty"`
Spec CronJobSpec `json:"spec,omitempty"`
Status CronJobStatus `json:"status,omitempty"`
}
//+kubebuilder:object:root=true
// CronJobList 包含了一个 CronJob 的列表
type CronJobList struct {
metav1.TypeMeta `json:",inline"`
metav1.ListMeta `json:"metadata,omitempty"`
Items []CronJob `json:"items"`
}最后,我们将这个Go类型添加到API组中。我们可以将这个API组中的类型添加到任何Scheme。
func init() {
SchemeBuilder.Register(&CronJob{}, &CronJobList{})
}设计API
设计规则:
- 首先所有序列化的字段必须是驼峰式,使用
omitemptystruct标记来表示当字段为空时省略该字段。 - 字段可以使用大多数的基本类型。数字是个例外:出于API兼容性的目的,只允许三种数字类型。对于整数,需要使用
int32和int64类型;对于小数,使用resource.Quantity类型。Quantity是十进制数的一种特殊符号,它有一个明确固定的表示方式,使它们在不同的机器上更具可移植性。 - 还有一个特殊类型
metav1.Time。它有一个稳定的、可移植的序列化格式的功能,其他与time.Time相同。
设计思想:
CronJob 由以下几部分组成:
- 一个时间表( CronJob 中的 cron )
- 要运行的 Job 模板( CronJob 中的 Job )
- 一个已经启动的 Job 的超时时间(如果该 Job 执行超时,那么我们会将在下次调度的时候重新执行该 Job)。
- 如果多个 Job 同时运行,该怎么办(我们要等待吗?还是停止旧的 Job ?)
- 暂停 CronJob 运行的方法,以防出现问题。
- 对旧 Job 历史的限制
首先修改cronjob_types.go文件中的CronJobSpec:
// CronJobSpec defines the desired state of CronJob
type CronJobSpec struct {
// +kubebuilder:validation:MinLength=0
// 定时任务的Cron表达式
Schedule string `json:"schedule"`
# +kubebuilder:validation:Minimum=0 告诉Kubebuilder为这个字段添加规格验证,验证字段值必须大于或等于0
// +kubebuilder:validation:Minimum=0
// 任务开始后的最长等待时间。
// +optional
StartingDeadlineSeconds *int64 `json:"startingDeadlineSeconds,omitempty"`
// 并发策略,指定如何处理作业的并发执行。
// "Allow"(默认):允许CronJobs并发运行;
// "Forbid":禁止并发运行,如果上一个运行尚未完成,则跳过下一个运行;
// "Replace":取消当前正在运行的Job,并用新的Job替换它。
// +optional
ConcurrencyPolicy ConcurrencyPolicy `json:"concurrencyPolicy,omitempty"`
// 是否暂停后续任务的执行,它不适用于已经开始的执行。默认为false。
// +optional
Suspend *bool `json:"suspend,omitempty"`
// 定时任务每次触发将创建的Job object模板
JobTemplate batchv1.JobTemplateSpec `json:"jobTemplate"`
// +kubebuilder:validation:Minimum=0
// Job成功执行的数量
// 这是一个指针,用于区分显式指定的零和未指定的情况。
// +optional
SuccessfulJobsHistoryLimit *int32 `json:"successfulJobsHistoryLimit,omitempty"`
// +kubebuilder:validation:Minimum=0
// Job失败的数量
// 这是一个指针,用于区分显式指定的零和未指定的情况。
// +optional
FailedJobsHistoryLimit *int32 `json:"failedJobsHistoryLimit,omitempty"`
}接下来,定义了一个自定义类型来表示并发策略。它的底层类型是string,但该类型给出了额外的文档,并允许我们在类型上附加验证,而不是在字段上验证,使验证逻辑更容易复用。
// ConcurrencyPolicy describes how the job will be handled.
// Only one of the following concurrent policies may be specified.
// If none of the following policies is specified, the default one
// is AllowConcurrent.
// +kubebuilder:validation:Enum=Allow;Forbid;Replace
type ConcurrencyPolicy string
const (
// AllowConcurrent allows CronJobs to run concurrently.
AllowConcurrent ConcurrencyPolicy = "Allow"
// ForbidConcurrent forbids concurrent runs, skipping next run if previous
// hasn't finished yet.
ForbidConcurrent ConcurrencyPolicy = "Forbid"
// ReplaceConcurrent cancels currently running job and replaces it with a new one.
ReplaceConcurrent ConcurrencyPolicy = "Replace"
)然后修改CronJobStatus,它表示实际看到的状态。它包含了我们希望用户或其他控制器能够轻松获得的任何信息。我们将保存一个正在运行的Jobs,以及我们最后一次成功运行Job的时间。
// CronJobStatus defines the observed state of CronJob
type CronJobStatus struct {
// INSERT ADDITIONAL STATUS FIELD - define observed state of cluster
// Important: Run "make" to regenerate code after modifying this file
// A list of pointers to currently running jobs.
// +optional
Active []corev1.ObjectReference `json:"active,omitempty"`
// Information when was the last time the job was successfully scheduled.
// +optional
LastScheduleTime *metav1.Time `json:"lastScheduleTime,omitempty"`
}接下来就可以编写控制器来实现这个CronJob。
groupversion_info.go
该文件是自动生成的。无需修改。
// 包 v1 包含了 batch v1 API 这个组的 API Schema 定义。
# +kubebuilder:object:generate=true 作用是为该类型自动生成CRD文件。
// +kubebuilder:object:generate=true
// +groupName=batch.wgh.io
package v1
import (
"k8s.io/apimachinery/pkg/runtime/schema"
"sigs.k8s.io/controller-runtime/pkg/scheme"
)
var (
// GroupVersion是用来注册这些对象的group version。
GroupVersion = schema.GroupVersion{Group: "batch.wgh.io", Version: "v1"}
// SchemeBuilder被用来给GroupVersionKind scheme添加go类型。
SchemeBuilder = &scheme.Builder{GroupVersion: GroupVersion}
// AddToScheme将group-version 中的类型添加到指定的scheme中。
AddToScheme = SchemeBuilder.AddToScheme
)zz_generated.deepcopy.go
该文件是自动生成的。无需修改。
zz_generated.deepcopy.go 包含了前述runtime.Object接口的自动实现,这些实现标记了代表Kinds的所有根类型。
runtime.Object接口的核心是一个深拷贝方法,即DeepCopyObject。
controller-tools中的object生成器也能够为每一个根类型以及其子类型生成另外两个易用的方法DeepCopy和DeepCopyInto。
controller
控制器是Kubernetes的核心,也是任何operator的核心。
控制器的工作是对于任何给定的对象,保证它的实际状态与对象中的期望状态相匹配。每个控制器专注于一个根Kind,但可能会与其他Kind交互。我们把这个过程称为reconciling调和。
在controller-runtime中,为特定种类实现reconciling的逻辑被称为Reconciler协调器。 Reconciler接受一个对象的名称,并返回我们是否需要重试。
controller的示例代码位于project/internal/controller目录中。
cronjob_controller.go
首先导入了一些基本包。
package controllers
import (
"context"
"k8s.io/apimachinery/pkg/runtime"
ctrl "sigs.k8s.io/controller-runtime"
"sigs.k8s.io/controller-runtime/pkg/client"
"sigs.k8s.io/controller-runtime/pkg/log"
batchv1 "wgh.io/project/api/v1"
)接下来定义了协调器CronJobReconciler。几乎每一个调节器都需要记录日志,并且能够获取对象,所以可以直接使用。
// CronJobReconciler reconciles a CronJob object
type CronJobReconciler struct {
client.Client
Scheme *runtime.Scheme
}下面配置在集群中运行的RBAC权限。ClusterRole的配置位于config/rbac/role.yaml,它通过 controller-gen使用make manifests命令从上述标记生成的。如果有报错,请运行错误中指定的命令并重新运行make manifests。
//+kubebuilder:rbac:groups=batch.wgh.io,resources=cronjobs,verbs=get;list;watch;create;update;patch;delete
//+kubebuilder:rbac:groups=batch.wgh.io,resources=cronjobs/status,verbs=get;update;patch
//+kubebuilder:rbac:groups=batch.wgh.io,resources=cronjobs/finalizers,verbs=update- 下面定义
Reconcile函数,Reconcile实际上对单个象执行协调。请求只有一个名称,但我们可以使用客户端从缓存中获取该对象。 - 返回一个空结果且没有错误,这向
controller-runtime表明我们已成功协调此对象,在进行一些更改之前无需重试。 - 大多数控制器都需要日志记录句柄和上下文,因此在这里设置。
- 上下文用于允许取消请求,并可能用于跟踪等操作。它是所有客户端方法的第一个参数。
Background上下文只是一个基本上下文,没有任何额外的数据或时间限制。 controller-runtime通过名为logr的库使用结构化日志记录。日志记录的工作原理是将键值对附加到静态消息。我们可以在协调方法的顶部预先分配一些对,以将这些对附加到此协调器中的所有日志行。
// Reconcile函数是Kubernetes控制循环的一部分,用于使集群现状趋于与期望状态一致。
// 用户需要修改Reconcile函数,比较CronJob对象指定的状态与集群实际状态,然后执行操作把集群状态调整为用户指定状态。
func (r *CronJobReconciler) Reconcile(ctx context.Context, req ctrl.Request) (ctrl.Result, error) {
_ = log.FromContext(ctx)
// TODO(user): your logic here
return ctrl.Result{}, nil
}最后,我们将此协调器添加到管理器中,以便在管理器启动时启动它。
// SetupWithManager sets up the controller with the Manager.
func (r *CronJobReconciler) SetupWithManager(mgr ctrl.Manager) error {
return ctrl.NewControllerManagedBy(mgr).
For(&batchv1.CronJob{}).
Complete(r)
}controller实现
CronJob 控制器的基本逻辑如下:
- 根据名称加载定时任务
- 列出所有有效的 job,更新其状态
- 根据保留的历史版本数清理版本过旧的 job
- 检查当前 CronJob 是否被挂起(如果被挂起,则不执行任何操作)
- 计算 job 下一个定时执行时间
- 如果 job 符合执行时机,没有超出截止时间,且不被并发策略阻塞,执行该 job
- 当任务进入运行状态或到了下一次执行时间, job 重新排队
需要修改上面的示例代码cronjob_controller.go。
首先要修改导入的一些包。
import (
"context"
"fmt"
"sort"
"time"
"github.com/robfig/cron"
kbatch "k8s.io/api/batch/v1"
corev1 "k8s.io/api/core/v1"
metav1 "k8s.io/apimachinery/pkg/apis/meta/v1"
"k8s.io/apimachinery/pkg/runtime"
ref "k8s.io/client-go/tools/reference"
ctrl "sigs.k8s.io/controller-runtime"
"sigs.k8s.io/controller-runtime/pkg/client"
"sigs.k8s.io/controller-runtime/pkg/log"
batchv1 "wgh.io/project/api/v1"
)然后添加一个时钟来计算时间。修改协调器,添加日志和时钟。realClock是结构体,实现了Clock接口,Now()方法返回time.Now(),获取真实时间。
type CronJobReconciler struct {
client.Client
Scheme *runtime.Scheme
Clock
}
// Clock
type realClock struct{}
func (_ realClock) Now() time.Time { return time.Now() }
// clock接口可以获取当前的时间,可以帮助我们在测试中模拟计时
type Clock interface {
Now() time.Time
}接着需要修改RBAC,因为需要一些权限去创建和管理job。
//+kubebuilder:rbac:groups=batch.wgh.io,resources=cronjobs,verbs=get;list;watch;create;update;patch;delete
//+kubebuilder:rbac:groups=batch.wgh.io,resources=cronjobs/status,verbs=get;update;patch
//+kubebuilder:rbac:groups=batch.wgh.io,resources=cronjobs/finalizers,verbs=update
//+kubebuilder:rbac:groups=batch,resources=jobs,verbs=get;list;watch;create;update;patch;delete
//+kubebuilder:rbac:groups=batch,resources=jobs/status,verbs=get然后修改协调器的核心逻辑。设置调度时间注释变量。
var (
scheduledTimeAnnotation = "batch.wgh.io/scheduled-at"
)1.根据名称加载定时任务
通过client获取定时任务。所有client方法第一个参数都是context,把请求对象信息作为最后一个参数。Get方法例外,它把NamespacedName作为中间的第二个参数。许多客户端方法最后也采用可变参数选项。
var cronJob batchv1.CronJob
if err := r.Get(ctx, req.NamespacedName, &cronJob); err != nil {
log.Error(err, "unable to fetch CronJob")
// 忽略掉 not-found 错误,它们不能通过重新排队修复(要等待新的通知)
// 在删除一个不存在的对象时,可能会报这个错误。
return ctrl.Result{}, client.IgnoreNotFound(err)
}2: 列出所有有效 job,更新它们的状态
为确保每个job的状态都会被更新到,我们需要列出某个CronJob在当前命名空间下的所有job。和Get方法类似,我们可以使用List方法来列出CronJob下所有的job。注意,我们使用变长参数来映射命名空间和任意多个匹配变量(实际上相当于是建立了一个索引)。
var childJobs kbatch.JobList
if err := r.List(ctx, &childJobs, client.InNamespace(req.Namespace), client.MatchingFields{jobOwnerKey: req.Name}); err != nil {
log.Error(err, "unable to list child Jobs")
return ctrl.Result{}, err
}jobOwnerKey的作用:随着cronjobs数量的增加,遍历所有cronjob查找会变的相当低效。为了提高查询效率,这些任务会根据控制器名称建立索引。缓存后的job对象会被添加上一个jobOwnerKey 字段。这个字段引用其所属控制器和函数作为索引。
查找到所有的job后,将其归类为 active,successful,failed三种类型,同时持续跟踪其最新的执行情况以更新其状态。status应该从每次执行状态中获取。
使用isJobFinished函数检查一个job是否已处于finished状态。当一个job被标记为 succeeded或failed时,我们认为这个任务处于finished状态。 Status conditions允许我们给job对象添加额外的状态信息,可以通过这些信息来检查job的完成或健康状态。
// isJobFinished
isJobFinished := func(job *kbatch.Job) (bool, kbatch.JobConditionType) {
for _, c := range job.Status.Conditions {
if (c.Type == kbatch.JobComplete || c.Type == kbatch.JobFailed) && c.Status == corev1.ConditionTrue {
return true, c.Type
}
}
return false, ""
}使用getScheduledTimeForJob函数来提取创建job时注释中的执行时间。
getScheduledTimeForJob := func(job *kbatch.Job) (*time.Time, error) {
timeRaw := job.Annotations[scheduledTimeAnnotation]
if len(timeRaw) == 0 {
return nil, nil
}
timeParsed, err := time.Parse(time.RFC3339, timeRaw)
if err != nil {
return nil, err
}
return &timeParsed, nil
}
for i, job := range childJobs.Items {
_, finishedType := isJobFinished(&job)
switch finishedType {
case "": // ongoing
activeJobs = append(activeJobs, &childJobs.Items[i])
case kbatch.JobFailed:
failedJobs = append(failedJobs, &childJobs.Items[i])
case kbatch.JobComplete:
successfulJobs = append(successfulJobs, &childJobs.Items[i])
}
// 将启动时间存放在注释中,当job生效时可以从中读取
scheduledTimeForJob, err := getScheduledTimeForJob(&job)
if err != nil {
log.Error(err, "unable to parse schedule time for child job", "job", &job)
continue
}
// 判断是否有最新的启动时间
if scheduledTimeForJob != nil {
if mostRecentTime == nil || mostRecentTime.Before(*scheduledTimeForJob) {
mostRecentTime = scheduledTimeForJob
}
}
}
// 更新最后一次调度时间字段
if mostRecentTime != nil {
cronJob.Status.LastScheduleTime = &metav1.Time{Time: *mostRecentTime}
} else {
cronJob.Status.LastScheduleTime = nil
}
// 清空Active字段的历史内容
cronJob.Status.Active = nil
// 遍历当前正在运行的Job对象activeJobs,为每个Job构建对象引用,并将其添加到Active字段中。
for _, activeJob := range activeJobs {
jobRef, err := ref.GetReference(r.Scheme, activeJob)
if err != nil {
log.Error(err, "unable to make reference to active job", "job", activeJob)
continue
}
cronJob.Status.Active = append(cronJob.Status.Active, *jobRef)
}记录我们观察到的job数量。为便于调试,略微提高日志级别。注意,这里没有使用格式化字符串,使用由键值对构成的固定格式信息来输出日志。这样更易于过滤和查询日志。
log.V(1).Info("job count", "active jobs", len(activeJobs), "successful jobs", len(successfulJobs), "failed jobs", len(failedJobs))更新CronJob的状态。
if err := r.Status().Update(ctx, &cronJob); err != nil {
log.Error(err, "unable to update CronJob status")
return ctrl.Result{}, err
}更新状态后,后续要确保状态符合我们在spec定下的预期。
3.根据保留的历史版本数清理过旧的 job
先清理掉一些版本太旧的job,这样可以不用保留太多无用的job。
// 注意: 删除操作采用的“尽力而为”策略
// 如果个别job删除失败了,不会将其重新排队,直接结束删除操作
// 如果Spec指定了FailedJobsHistoryLimit,则获取失败Job列表
if cronJob.Spec.FailedJobsHistoryLimit != nil {
sort.Slice(failedJobs, func(i, j int) bool {
if failedJobs[i].Status.StartTime == nil {
return failedJobs[j].Status.StartTime != nil
}
// 对失败Job按启动时间排序
return failedJobs[i].Status.StartTime.Before(failedJobs[j].Status.StartTime)
})
// 遍历Job,删除索引超过限制的Job
for i, job := range failedJobs {
// 当前总失败Job数减去允许保留数,得出应当删除的Job数上限,如果当前索引大于或等于这个上限,表示这些Job都需要删除。
// 假如失败Job总数为10,允许保留数为5,那么应当删除的Job数为5,如果当前索引大于等于5,表示这些Job都需要删除
if int32(i) >= int32(len(failedJobs))-*cronJob.Spec.FailedJobsHistoryLimit {
break
}
// 是的话删除这个Job对象
if err := r.Delete(ctx, job, client.PropagationPolicy(metav1.DeletePropagationBackground)); client.IgnoreNotFound(err) != nil {
log.Error(err, "unable to delete old failed job", "job", job)
} else {
log.V(0).Info("deleted old failed job", "job", job)
}
}
}
// 如果指定了SuccessfulJobsHistoryLimit,处理成功Job
if cronJob.Spec.SuccessfulJobsHistoryLimit != nil {
sort.Slice(successfulJobs, func(i, j int) bool {
if successfulJobs[i].Status.StartTime == nil {
return successfulJobs[j].Status.StartTime != nil
}
return successfulJobs[i].Status.StartTime.Before(successfulJobs[j].Status.StartTime)
})
for i, job := range successfulJobs {
if int32(i) >= int32(len(successfulJobs))-*cronJob.Spec.SuccessfulJobsHistoryLimit {
break
}
if err := r.Delete(ctx, job, client.PropagationPolicy(metav1.DeletePropagationBackground)); err != nil {
log.Error(err, "unable to delete old successful job", "job", job)
} else {
log.V(0).Info("deleted old successful job", "job", job)
}
}
}4.检查是否被挂起
如果当前cronjob被挂起,不会再运行其下的任何job,我们将其停止。这对于某些job出现异常的排查非常有用。我们无需删除cronjob来中止其后续其他job的运行。
if cronJob.Spec.Suspend != nil && *cronJob.Spec.Suspend {
log.V(1).Info("cronjob suspended, skipping")
return ctrl.Result{}, nil
}5.计算job下一次执行时间
如果cronjob没被挂起,那么我们需要计算它的下一次执行时间,同时检查是否有遗漏的执行没被处理。
// getNextSchedule辅助函数
// 解析CronJob的定时表达式,生成定时器对象
getNextSchedule := func(cronJob *batchv1.CronJob, now time.Time) (lastMissed time.Time, next time.Time, err error) {
// 根据CronJob的调度表达式cronJob.Spec.Schedule解析成Cron定时器对象sched
sched, err := cron.ParseStandard(cronJob.Spec.Schedule)
if err != nil {
return time.Time{}, time.Time{}, fmt.Errorf("Unparseable schedule %q: %v", cronJob.Spec.Schedule, err)
}
// 使用最后调度时间或者对象创建时间作为起始时间
var earliestTime time.Time
if cronJob.Status.LastScheduleTime != nil {
earliestTime = cronJob.Status.LastScheduleTime.Time
} else {
earliestTime = cronJob.ObjectMeta.CreationTimestamp.Time
}
if cronJob.Spec.StartingDeadlineSeconds != nil {
// 如果开始执行时间超过了截止时间,不再执行
// 从now时间扣除StartingDeadlineSeconds定义的秒数,这样就计算出了调度允许的最早时间点schedulingDeadline。
schedulingDeadline := now.Add(-time.Second * time.Duration(*cronJob.Spec.StartingDeadlineSeconds))
if schedulingDeadline.After(earliestTime) {
earliestTime = schedulingDeadline
}
}
// 如果起始时间晚于当前时间,这是不合理的。直接返回空时间,表示没有找到最后调度时间,和下次调度时间sched.Next(now)
if earliestTime.After(now) {
return time.Time{}, sched.Next(now), nil
}
// 从起始时间开始向后遍历,计算每次调度时间
starts := 0
for t := sched.Next(earliestTime); !t.After(now); t = sched.Next(t) {
// 记录最近一次错过的时间
lastMissed = t
// 一个 CronJob 可能会遗漏多次执行。举个例子,周五 5:00pm 技术人员下班后,
// 控制器在 5:01pm 发生了异常。然后直到周二早上才有技术人员发现问题并
// 重启控制器。那么所有的以1小时为周期执行的定时任务,在没有技术人员
// 进一步的干预下,都会有 80 多个 job 在恢复正常后一并启动(如果 job 允许多并发和延迟启动)
// 如果 CronJob 的某些地方出现异常,控制器或 apiservers (用于设置任务创建时间)
// 的时钟不正确, 那么就有可能出现错过很多次执行时间的情形(跨度可达数十年)
// 这将会占满控制器的CPU和内存资源。这种情况下,我们不需要列出错过的全部执行时间。
// 限制遍历次数避免计算过多错过时间点
starts++
if starts > 100 {
// 获取不到最近一次执行时间,直接返回空切片。
return time.Time{}, time.Time{}, fmt.Errorf("Too many missed start times (> 100). Set or decrease .spec.startingDeadlineSeconds or check clock skew.")
}
}
// 返回最近错过时间和下次调度时间
return lastMissed, sched.Next(now), nil
}
// 计算出定时任务下一次执行时间(或是遗漏的执行时间)
missedRun, nextRun, err := getNextSchedule(&cronJob, r.Now())
if err != nil {
log.Error(err, "unable to figure out CronJob schedule")
// 重新排队直到有更新修复这次定时任务调度,不必返回错误
return ctrl.Result{}, nil
}上述步骤执行完后,将准备好的请求加入队列直到下次执行, 然后确定这些job是否要实际执行。
scheduledResult := ctrl.Result{RequeueAfter: nextRun.Sub(r.Now())} // save this so we can re-use it elsewhere
log = log.WithValues("now", r.Now(), "next run", nextRun)6.如果job符合执行时机,并且没有超出截止时间,且不被并发策略阻塞,执行该job
如果job错过了运行,且还没超出截止时间,那么需要重新执行。
if missedRun.IsZero() {
log.V(1).Info("no upcoming scheduled times, sleeping until next")
return scheduledResult, nil
}
// 确保错过的执行没有超过截止时间
log = log.WithValues("current run", missedRun)
tooLate := false
if cronJob.Spec.StartingDeadlineSeconds != nil {
tooLate = missedRun.Add(time.Duration(*cronJob.Spec.StartingDeadlineSeconds) * time.Second).Before(r.Now())
}
if tooLate {
log.V(1).Info("missed starting deadline for last run, sleeping till next")
// TODO(directxman12): events
return scheduledResult, nil
}如果确认job需要实际执行。我们有三种策略执行该job。
- 要么先等待现有的job执行完后,在启动本次job;
- 或是直接覆盖取代现有的job;
- 或是不考虑现有的job,直接作为新的job执行。
因为缓存导致的信息有所延迟,当更新信息后需要重新排队。
// 确定要job的执行策略 —— 并发策略可能禁止多个job同时运行
if cronJob.Spec.ConcurrencyPolicy == batch.ForbidConcurrent && len(activeJobs) > 0 {
log.V(1).Info("concurrency policy blocks concurrent runs, skipping", "num active", len(activeJobs))
return scheduledResult, nil
}
// 直接覆盖现有 job
if cronJob.Spec.ConcurrencyPolicy == batch.ReplaceConcurrent {
for _, activeJob := range activeJobs {
// 对activeJobs进行遍历删除,忽略可能因为Jobs已经消失而返回的NotFoundError
if err := r.Delete(ctx, activeJob, client.PropagationPolicy(metav1.DeletePropagationBackground)); client.IgnoreNotFound(err) != nil {
log.Error(err, "unable to delete active job", "job", activeJob)
return ctrl.Result{}, err
}
}
}确定如何处理现有job后,创建符合我们预期的job。
// constructJobForCronJob函数根据CronJob模板和调度时间构建Job对象
constructJobForCronJob := func(cronJob *batchv1.CronJob, scheduledTime time.Time) (*kbatch.Job, error) {
// job名称带上执行时间以确保唯一性,避免job创建两次。
name := fmt.Sprintf("%s-%d", cronJob.Name, scheduledTime.Unix())
// 设置job的元数据
job := &kbatch.Job{
ObjectMeta: metav1.ObjectMeta{
Labels: make(map[string]string),
Annotations: make(map[string]string),
Name: name,
Namespace: cronJob.Namespace,
},
// 从CronJob模板深拷贝Spec
Spec: *cronJob.Spec.JobTemplate.Spec.DeepCopy(),
}
// 拷贝Annotations和Labels
for k, v := range cronJob.Spec.JobTemplate.Annotations {
job.Annotations[k] = v
}
job.Annotations[scheduledTimeAnnotation] = scheduledTime.Format(time.RFC3339)
for k, v := range cronJob.Spec.JobTemplate.Labels {
job.Labels[k] = v
}
// 设置所有者引用,这允许Kubernetes垃圾回收器在删除CronJob时知道需要协调哪个cronjob。
if err := ctrl.SetControllerReference(cronJob, job, r.Scheme); err != nil {
return nil, err
}
return job, nil
}
// 构建job
job, err := constructJobForCronJob(&cronJob, missedRun)
if err != nil {
log.Error(err, "unable to construct job from template")
// don't bother requeuing until we get a change to the spec
return scheduledResult, nil
}
// 在集群中创建job
if err := r.Create(ctx, job); err != nil {
log.Error(err, "unable to create Job for CronJob", "job", job)
return ctrl.Result{}, err
}
log.V(1).Info("created Job for CronJob run", "job", job)7.当 job开始运行或到了job下一次的执行时间,重新排队
然后,我们将返回上面准备的结果,即我们希望在下次需要运行时重新排队。
// 当有job进入运行状态后,重新排队,同时更新状态
return scheduledResult, nil
}最后,我们将更新我们的设置。为了让我们的协调器能够快速查找其所有者的作业,我们需要一个索引。我们声明一个索引键,后续我们可以将其用于client的虚拟变量名中,从job对象中提取索引值。索引器将自动为我们处理命名空间,因此,所以如果job有owner值,我们只需提取ower name。
另外,我们需要告知manager,这个控制器拥有哪些job。当对应的job发生变更或被删除自动调用Reconcile。
var (
jobOwnerKey = ".metadata.controller"
apiGVStr = batchv1.GroupVersion.String()
)
// SetupWithManager sets up the controller with the Manager.
func (r *CronJobReconciler) SetupWithManager(mgr ctrl.Manager) error {
// 此处不是测试,我们需要创建一个真实的时钟
if r.Clock == nil {
r.Clock = realClock{}
}
if err := mgr.GetFieldIndexer().IndexField(context.Background(), &kbatch.Job{}, jobOwnerKey, func(rawObj client.Object) []string {
// 根据jobOwnerKey获取job的所有者对象,提取owner
job := rawObj.(*kbatch.Job)
owner := metav1.GetControllerOf(job)
if owner == nil {
return nil
}
// 确保owner是个CronJob
if owner.APIVersion != apiGVStr || owner.Kind != "CronJob" {
return nil
}
// 是CronJob,返回
return []string{owner.Name}
}); err != nil {
return err
}
// 使用控制器管理器构建控制器对象
return ctrl.NewControllerManagedBy(mgr).
// 监听CronJob类型资源
For(&batchv1.CronJob{}).
// 处理Job类型的归属资源
Owns(&kbatch.Job{}).
// 完成控制器设置
Complete(r)
}main.go
如果我们要使用任何其他CRD,我们必须用相同的方法添加它们的scheme。内置类型如Job就添加了它自己的scheme clientgoscheme。
var (
scheme = runtime.NewScheme()
setupLog = ctrl.Log.WithName("setup")
)
func init() {
utilruntime.Must(clientgoscheme.AddToScheme(scheme))
utilruntime.Must(batchv1.AddToScheme(scheme))
//+kubebuilder:scaffold:scheme
}kubebuilder添加了一个阻塞调用我们的CornJob控制器的SetupWithManager方法。
func main() {
...
if err = (&controller.CronJobReconciler{
Client: mgr.GetClient(),
Scheme: mgr.GetScheme(),
}).SetupWithManager(mgr); err != nil {
setupLog.Error(err, "unable to create controller", "controller", "CronJob")
os.Exit(1)
}
...
}添加Webhook验证
如果要为CRD实现准入Webhook,唯一需要做的就是实现Defaulter和/或Validator接口。
Kubebuilder 会帮你处理剩下的事情,例如:
- 创建 webhook 服务端。
- 确保服务端已添加到 manager 中。
- 为你的 webhooks 创建处理函数。
- 用路径在你的服务端中注册每个处理函数。
首先使用下面的命令创建脚手架,这会在main.go中注册你的webhook。
# 默认和验证 webhook
kubebuilder create webhook --group batch --version v1 --kind CronJob --defaulting --programmatic-validation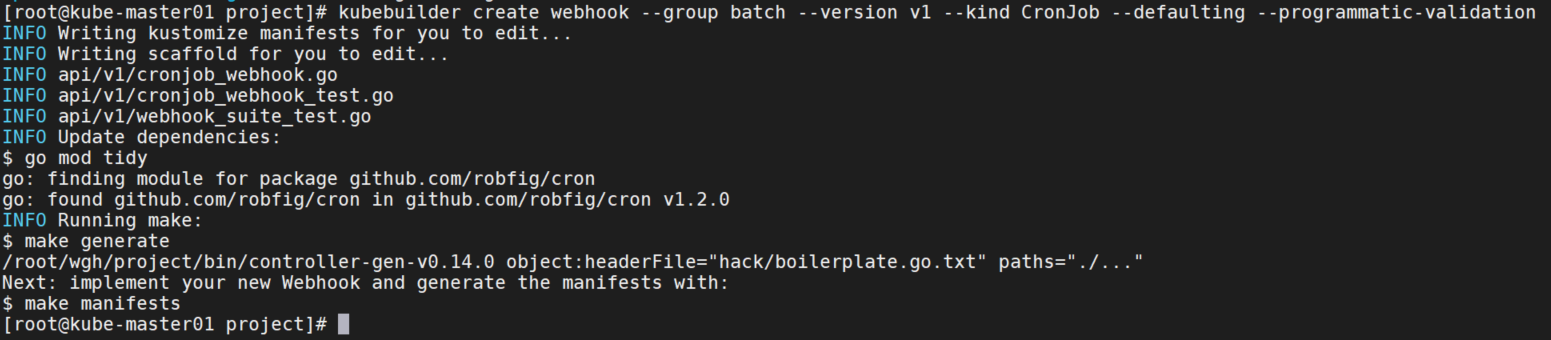
cronjob_webhook.go
目录位置:/api/v1/cronjob_webhook.go
首先修改import,导入一些包。
"github.com/robfig/cron"
apierrors "k8s.io/apimachinery/pkg/api/errors"
"k8s.io/apimachinery/pkg/runtime"
"k8s.io/apimachinery/pkg/runtime/schema"
validationutils "k8s.io/apimachinery/pkg/util/validation"
"k8s.io/apimachinery/pkg/util/validation/field"
ctrl "sigs.k8s.io/controller-runtime"
logf "sigs.k8s.io/controller-runtime/pkg/log"
"sigs.k8s.io/controller-runtime/pkg/webhook"
"sigs.k8s.io/controller-runtime/pkg/webhook/admission"接下来,我们将为Webhook设置一个记录器。
var cronjoblog = logf.Log.WithName("cronjob-resource")然后,我们使用管理器设置Webhook。
// SetupWebhookWithManager will setup the manager to manage the webhooks
func (r *CronJob) SetupWebhookWithManager(mgr ctrl.Manager) error {
return ctrl.NewWebhookManagedBy(mgr).
For(r).
Complete()
}请注意我们用kubebuilder标记去生成webhook清单。 这个标记负责生成一个mutating webhook清单。标记的含义解释在这里。
//+kubebuilder:webhook:path=/mutate-batch-wgh-io-v1-cronjob,mutating=true,failurePolicy=fail,sideEffects=None,groups=batch.wgh.io,resources=cronjobs,verbs=create;update,versions=v1,name=mcronjob.kb.io,admissionReviewVersions=v1
path:定义webhook接受请求的HTTP路径
mutating:是否为mutating webhook,这里是true
failurePolicy:失败策略,这里设置为会返回原请求的fail
sideEffects:none表示没有副作用
groups:该webhook适用于的API group,这里是batch.wgh.io
resources:适用的资源类型,这里是cronjobs
verbs:允许的verbs,这里是create和update
versions:适用的API版本,这里是v1
name:webhook的名称
admissionReviewVersions:支持的AdmissionReview版本,这里是v1使用webhook.Defaulter接口给CRD设置默认值。webhook会自动调用这个默认值。该Default方法应更改接收器,并设置默认值。
var _ webhook.Defaulter = &CronJob{}
// Default implements webhook.Defaulter so a webhook will be registered for the type
func (r *CronJob) Default() {
cronjoblog.Info("default", "name", r.Name)
if r.Spec.ConcurrencyPolicy == "" {
r.Spec.ConcurrencyPolicy = AllowConcurrent
}
if r.Spec.Suspend == nil {
r.Spec.Suspend = new(bool)
}
if r.Spec.SuccessfulJobsHistoryLimit == nil {
r.Spec.SuccessfulJobsHistoryLimit = new(int32)
*r.Spec.SuccessfulJobsHistoryLimit = 3
}
if r.Spec.FailedJobsHistoryLimit == nil {
r.Spec.FailedJobsHistoryLimit = new(int32)
*r.Spec.FailedJobsHistoryLimit = 1
}
}这个标记负责生成一个validating webhook清单。
//+kubebuilder:webhook:path=/validate-batch-wgh-io-v1-cronjob,mutating=false,failurePolicy=fail,sideEffects=None,groups=batch.wgh.io,resources=cronjobs,verbs=create;update,versions=v1,name=vcronjob.kb.io,admissionReviewVersions=v1
# 如果你要想开启删除验证,请将 verbs 修改为 "verbs=create;update;delete"如果实现webhook.Validator接口并调用了这个验证,webhook将会自动被服务。
ValidateCreate, ValidateUpdate 和 ValidateDelete 方法期望在创建、更新和删除时 分别验证其接收者。我们将 ValidateCreate 从 ValidateUpdate 分离开来以允许某些行为,像 使某些字段不可变,以至于仅可以在创建的时候去设置它们。我们也将 ValidateDelete 从 ValidateUpdate 分离开来以允许在删除的时候的不同验证行为。然而,这里我们只对 ValidateCreate 和 ValidateUpdate 用相同的共享验证。在 ValidateDelete 不做任何事情,因为我们不需要再 删除的时候做任何验证。
我们验证CronJob的spec和name。
func (r *CronJob) validateCronJob() error {
var allErrs field.ErrorList
if err := r.validateCronJobName(); err != nil {
allErrs = append(allErrs, err)
}
if err := r.validateCronJobSpec(); err != nil {
allErrs = append(allErrs, err)
}
if len(allErrs) == 0 {
return nil
}
return apierrors.NewInvalid(
schema.GroupKind{Group: "batch.tutorial.kubebuilder.io", Kind: "CronJob"},
r.Name, allErrs)
}
func (r *CronJob) validateCronJobName() *field.Error {
if len(r.ObjectMeta.Name) > validationutils.DNS1035LabelMaxLength-11 {
// The job name length is 63 character like all Kubernetes objects
// (which must fit in a DNS subdomain). The cronjob controller appends
// a 11-character suffix to the cronjob (`-$TIMESTAMP`) when creating
// a job. The job name length limit is 63 characters. Therefore cronjob
// names must have length <= 63-11=52. If we don't validate this here,
// then job creation will fail later.
return field.Invalid(field.NewPath("metadata").Child("name"), r.Name, "must be no more than 52 characters")
}
return nil
}
func (r *CronJob) validateCronJobSpec() *field.Error {
// kubernetes API machinery 的字段助手会帮助我们很好地返回结构化的验证错误。
return validateScheduleFormat(
r.Spec.Schedule,
field.NewPath("spec").Child("schedule"))
}我们需要验证cronjob格式是否正确。
func validateScheduleFormat(schedule string, fldPath *field.Path) *field.Error {
if _, err := cron.ParseStandard(schedule); err != nil {
return field.Invalid(fldPath, schedule, err.Error())
}
return nil
}OpenAPI schema声明性地验证一些字段。kubebuilder验证标记:前缀是 // +kubebuilder:validation。 你可以通过运行controller-gen crd -w查找到kubebuilder支持的用于声明验证的所有标记。
运行和部署controller
对API做了任何修改后都要首先重新生成CR,CRD配置清单。
make manifests
安装CRD。
make install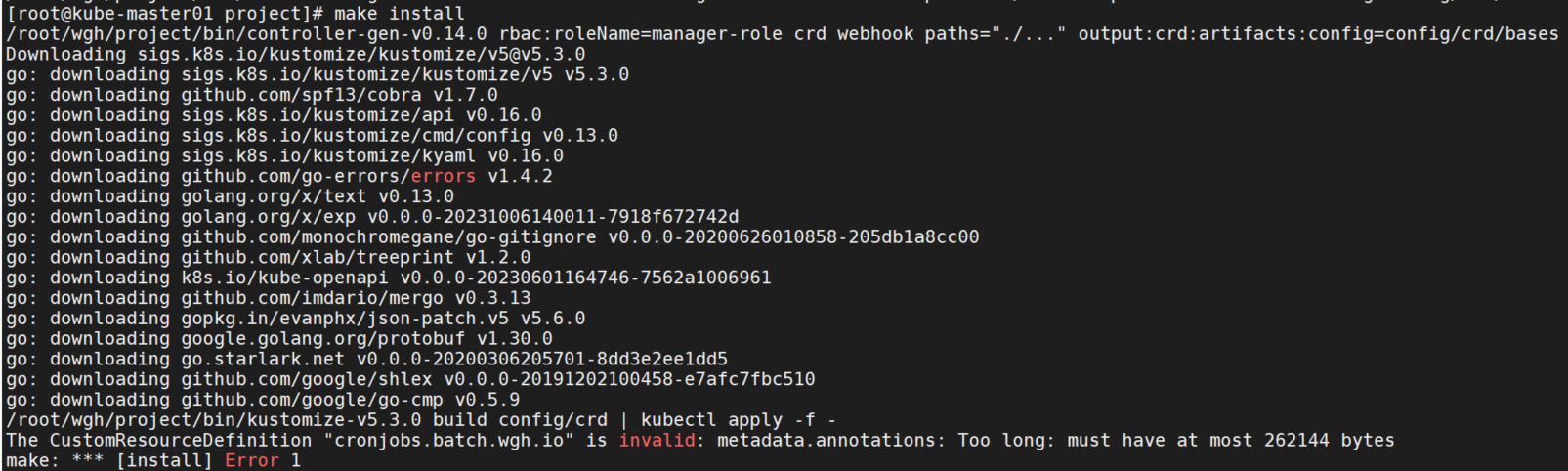
报错:The CustomResourceDefinition "cronjobs.batch.wgh.io" is invalid: metadata.annotations: Too long: must have at most 262144 bytes annotations过长。
查看CRD配置文件:
apiVersion: apiextensions.k8s.io/v1
kind: CustomResourceDefinition
metadata:
annotations:
controller-gen.kubebuilder.io/version: v0.14.0
name: cronjobs.batch.wgh.io这个annotations是没有超出长度的。在github上找到了issue:https://github.com/kubernetes-sigs/kubebuilder/issues/2556 ,有两种解决方法:
第一种是修改Makefile中的manifests配置,将crd修改为crd:maxDescLen=0
.PHONY: manifests
manifests: controller-gen ## Generate WebhookConfiguration, ClusterRole and CustomResourceDefinition objects.
- $(CONTROLLER_GEN) rbac:roleName=manager-role crd webhook paths="./..." output:crd:artifacts:config=config/crd/bases
+ $(CONTROLLER_GEN) rbac:roleName=manager-role crd:maxDescLen=0 webhook paths="./..." output:crd:artifacts:config=config/crd/bases第二种是在apply时添加--server-side参数跳过验证。这里采用了第一种方法,修改后再次执行make命令安装成功。

查看crd。

先禁用webhook,启动控制器。
export ENABLE_WEBHOOKS=false
make run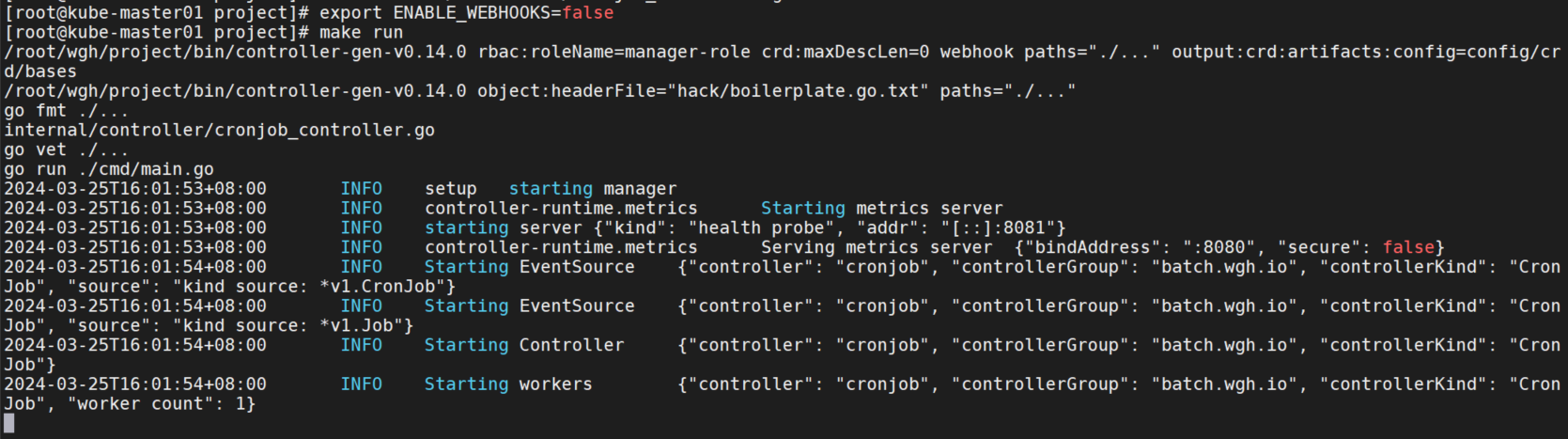
测试CronJob
编写测试文件:config/samples/batch_v1_cronjob.yaml
apiVersion: batch.wgh.io/v1
kind: CronJob
metadata:
labels:
app.kubernetes.io/name: cronjob
app.kubernetes.io/instance: cronjob-sample
app.kubernetes.io/part-of: project
app.kubernetes.io/managed-by: kustomize
app.kubernetes.io/created-by: project
name: cronjob-sample
spec:
schedule: "*/1 * * * *"
startingDeadlineSeconds: 60
concurrencyPolicy: Allow # explicitly specify, but Allow is also default.
jobTemplate:
spec:
template:
spec:
containers:
- name: hello
image: busybox
args:
- /bin/sh
- -c
- date; echo Hello from the Kubernetes cluster
restartPolicy: OnFailure创建
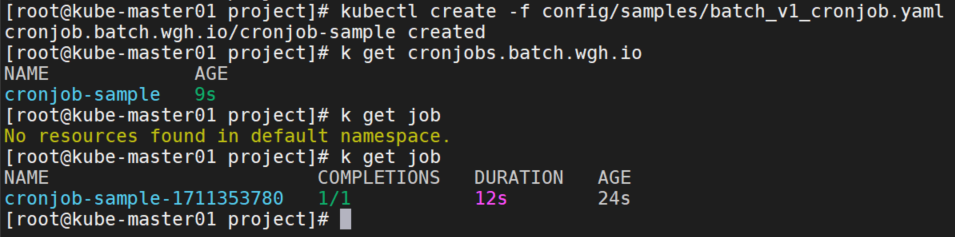
kubectl create -f config/samples/batch_v1_cronjob.yaml
查看controller日志

job运行成功。
第二次运行成功。
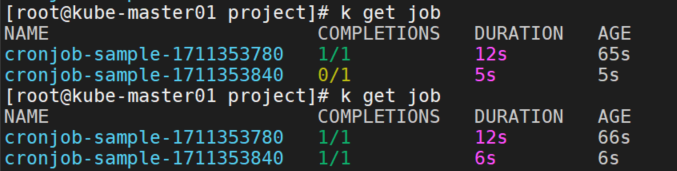
关闭controller。
修改MakeFile,将docker换位nerdctl。
CONTAINER_TOOL ?= nerdctl
#CONTAINER_TOOL ?= docker构建镜像。
make docker-build docker-push IMG=registry-1.docker.io/wgh9626/cronjob:v1这里会无法拉取gcr.io镜像,修改Dockerfile,修改镜像为:togettoyou/gcr.io.distroless.static:nonroot
再次构建报错go mod无法下载。

在Dockerfile中添加环境变量:ENV GOPROXY=https://goproxy.cn,direct,再次运行成功。
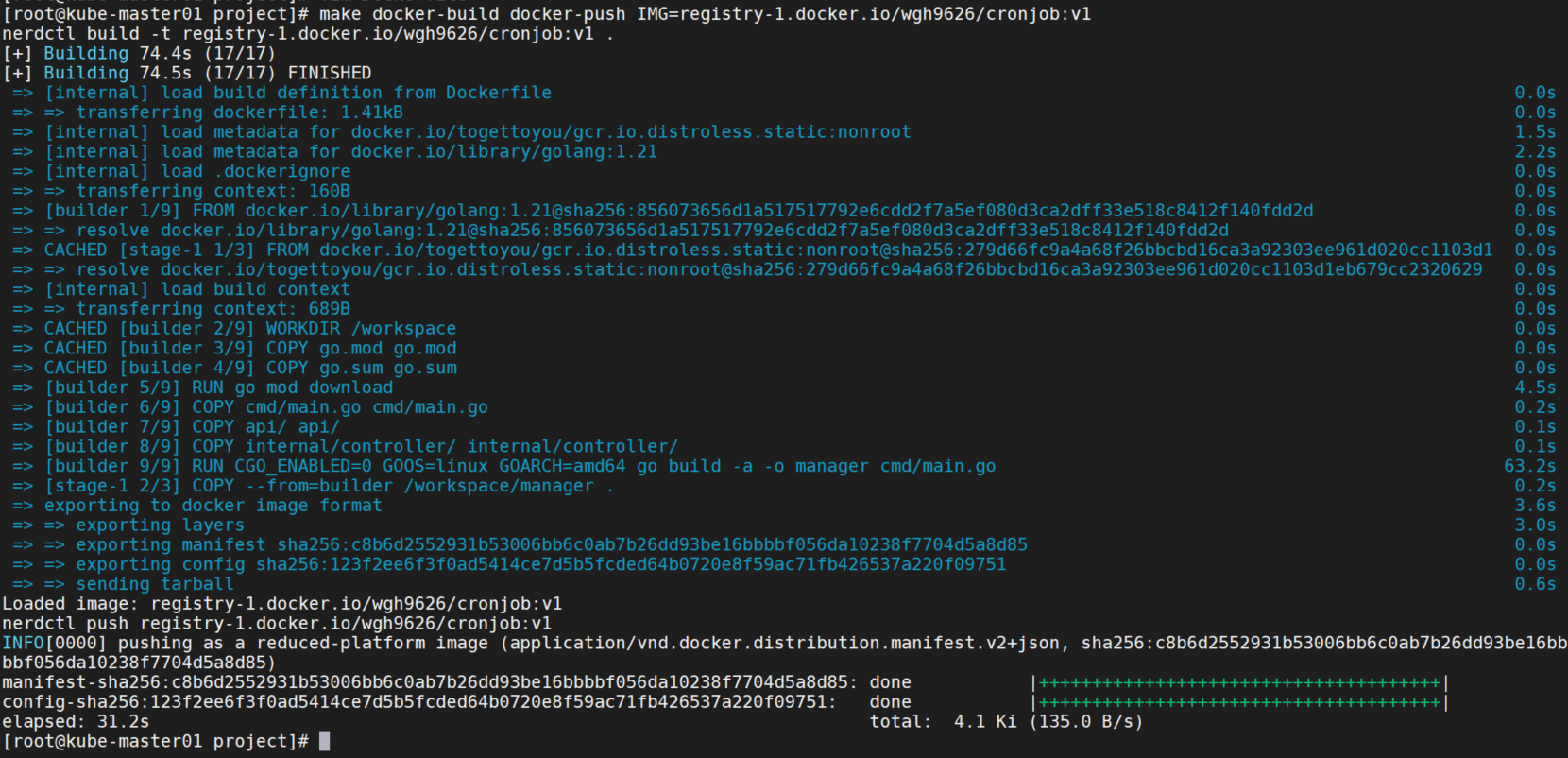

部署镜像。
make deploy IMG=registry-1.docker.io/wgh9626/cronjob:v1可以看到自动创建了一些资源。
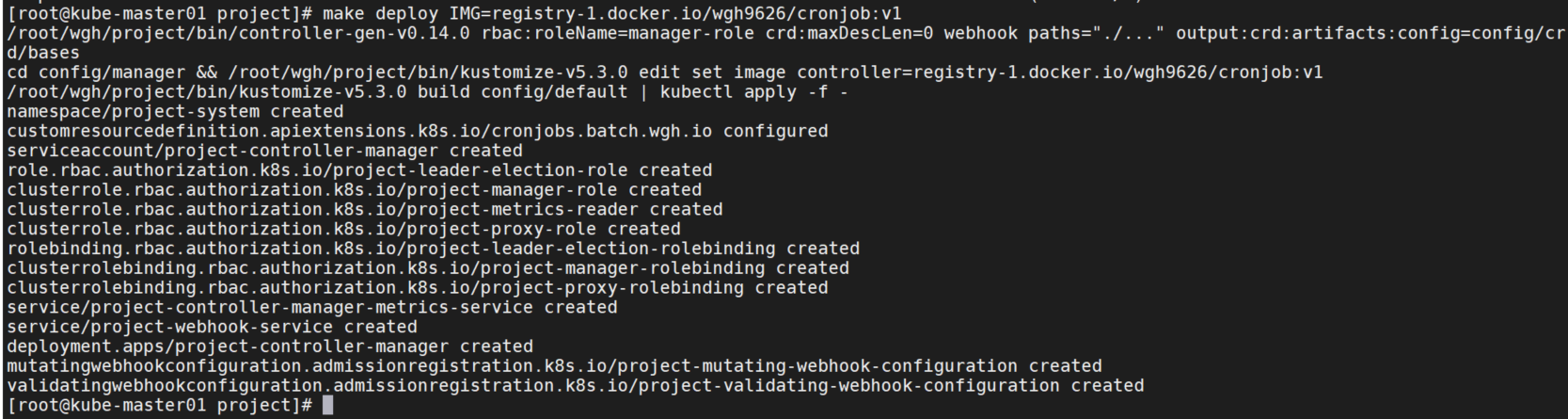
这里pod会无法启动,因为在集群中webhook需要证书,报错:MountVolume.SetUp failed for volume "cert" : secret "webhook-server-cert" not found
部署webhook
首先安装cert-manager,使用cert manager为webhook服务器提供证书。

在config/default/webhookcainjection_patch.yaml目录中可以看到MutatingWebhookConfiguration和ValidatingWebhookConfiguration都已经添加了cert-manager.io/inject-ca-from: CERTIFICATE_NAMESPACE/CERTIFICATE_NAME的annotations。这样CA就会自动注入到webhook中。
修改config/default/kustomization.yaml文件,启用cert-manager。
- ../certmanager
replacements:
# 下面的全部取消注释。
....再编辑config/crd/kustomization.yaml文件,开启CRD的CA注入。
- path: patches/cainjection_in_cronjobs.yaml重新部署镜像。
make undeploy
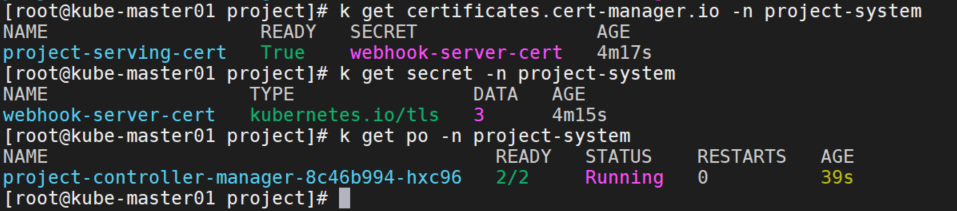
make deploy IMG=registry-1.docker.io/wgh9626/cronjob:v1pod报错secret "webhook-server-cert" not found,查看secret没有生成,certificates状态为False,查看cert-manager-controller日志报错:415: Unsupported Media Type,需要开启kube-apiserver的feature-gates=ServerSideApply=true参数。重新部署。
gcr.io/kubebuilder/kube-rbac-proxy:v0.15.0镜像会无法下载,可以使用registry-1.docker.io/wgh9626/kube-rbac-proxy:v0.15.0
controller成功启动。
创建一个CronJob测试webhook。
kubectl create -f config/samples/batch_v1_cronjob.yaml可以看到执行成功。


下面创建一个无效的CronJob,将上面的配置文件改为如下:
schedule: "* * * *"创建失败,controller验证后返回了错误信息。
