1.什么是docker
- 基于 Linux 内核的 Cgroup, Namespace,以及 Union FS 等技术,对进程进行封装隔离,属于操作系统层面的虚拟化技术,由于隔离的进程独立于宿主和其它的隔离的进程,因此也称其为容器。
- 最初实现是基于 LXC,从0.7以后开始去除 LXC,转而使用自行开发的 Libcontainer,从1.11开始,则进一步演进为使用 runC 和 Containerd。
- Docker 在容器的基础上,进行了进一步的封装,从文件系统、网络互联到进程隔离等等,极大的简化了容器的创建和维护,使得 Docker 技术比虚拟机技术更为轻便、快捷。
2.为什么要用 Docker
- 更高效地利用系统资源:虚拟机需要虚拟一个操作系统的,有一部分资源是要支撑这个操作系统的。
- 更快速的启动时间:操作系统启动比较慢,容器直接在物理机上启动进程。
- 一致的运行环境:把依赖打包成镜像,一次构建,到处运行。
- 持续交付和部署
- 更轻松地迁移
- 更轻松地维护和扩展
3.虚拟机和容器运行态的对比
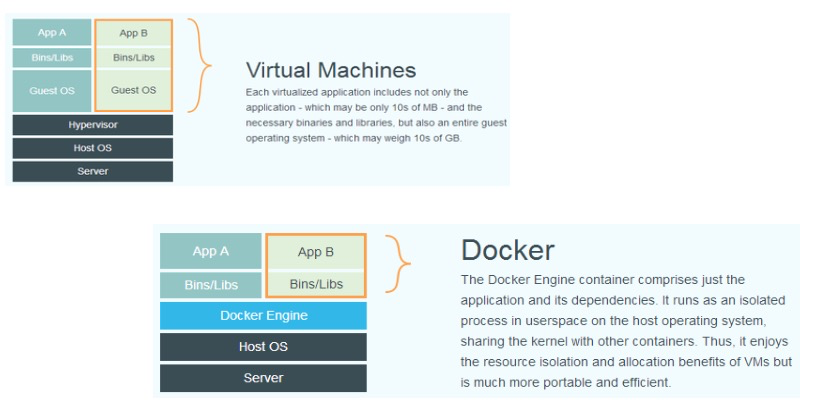
- 虚拟机:
Hypervisor:用来管理虚拟机
Guest OS:一个个虚拟机,包括完整的操作系统 - 容器:
服务器的主机OS之上就是docker引擎,即在主机上起进程。
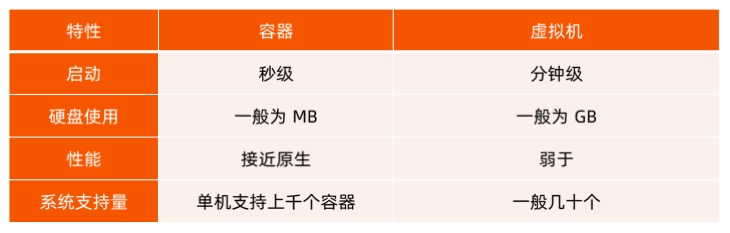
性能对比
4.docker安装
官方文档:https://docs.docker.com/engine/install/centos/
docker即之前的docker-io,1.13.1

docker-ce,社区版,1.13.1之后的版本
5.容器操作

- docker run 启动容器
- -it interactive,tty 交互
- -d 后台运行
- -p 端口映射
- -v 磁盘挂载
- docker start 启动已终止容器
- docker stop 停止容器
- docker ps 查看容器进程
- docker inspect ≤containerid> 查看容器细节
- docker exec 进入容器
# 通过 nsenter进入容器的各种namespace PID=$(docker inspect --format "{{ .State.Pid }}" <container>) $ nsenter --target $PID --mount --uts --ipc --net --pid docker cp file1 <containerid>:/file-to-path拷贝文件至容器内
6.容器主要特性
- 安全性:容器隔离性+linux本身的安全性
- 隔离性:所有的依赖打包好放在镜像中,所以需要依赖检查。
- 便携性:方便到处运行
- 可配额:依赖cgroup,控制容器使用的资源。
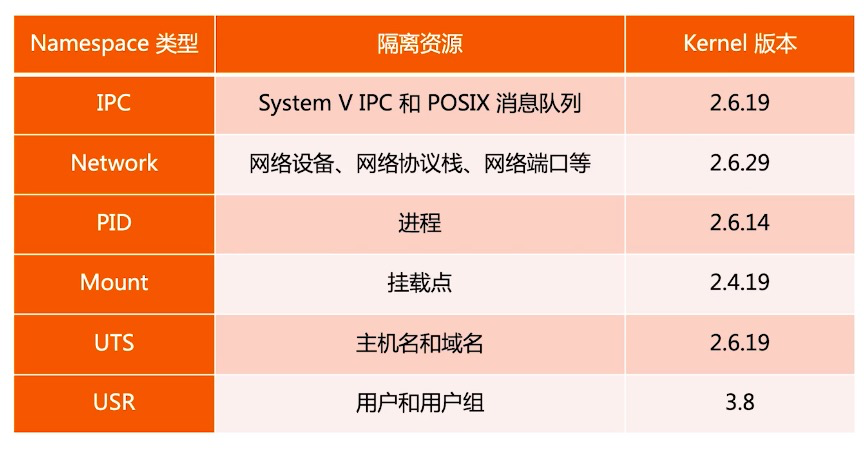
7.Namespace
Linux Namespace 是一种 Linux Kernel 提供的资源隔离方案:系统可以为进程分配不同的 Namespace;
并保证不同的 Namespace 资源独立分配、进程彼此隔离,即 不同的 Namespace 下的进程互不干扰。
Linux 内核代码中 Namespace 的实现
进程数据结构
Struct task struct {
...
/* namespaces */
struct nsproxy *nsproxy;
...
}Namespace 数据结构
struct nsproxy {
atomic_t count;
struct uts namespace *uts ns;
struct ipc_namespace *ipc_ns;
struct mnt namespace *mnt ns;
Struct pid namespace
*pid_ns_ for_children;
struct net *net_ns;
}Linux 对 Namespace 操作方法
- clone
在创建新进程的系统调用时,可以通过 flags 参数指定需要新建的 Namespace 类型:
I/ CLONENEWCGROUP / CLONE NEWIPC / CLONE NEWNET / CLONE_ NEWNS / CLONE_NEWPID/ CLONE_NEWUSER / CLONE NEWUTS
int clone(int (fn)(void ), void child_stack, int flags, void arg) - setns
该系统调用可以让调用进程加入某个已经存在的 Namespace 中:
Int setns(int fd, int nstype) - unshare
该系统调用可以将调用进程移动到新的 Namespace 下:
int unshare(int flags)
不同namespace的隔离性
-
pid namespace
- 不同用户的进程就是通过 Pid namespace 隔离开的,且不同 namespace 中可以有相同 Pid。
- 容器内的其他进程也是通过entrypoint即pid为1的进程fork出来的。容器本身进程也是主机上systemd fork出来的。所以主机上的pid和容器内的pid不一致。
-
net namespace
- 网络隔离是通过 net namespace 实现的,每个 net namespace 有独立的 network devices, IP addresses, IP routing tables, /proc/net 目录。这样进程就有了独立的身份。
- Docker 默认采用 veth 的方式将 container 中的虚拟网卡同 host 上的一个 docker bridge: docker0 连接在一起。
-
ipc namespace
- Container 中进程交互还是采用 linux 常见的进程间交互方法 (interprocess communication – ipc),包括常见的信号
量、消息队列和共享内存。 - container 的进程间交互实际上还是 host上 具有相同 Pid namespace 中的进程间交互,因此需要在IPC 资源申请时加入namespace 信息- 每个IPC 资源有一个唯一的32位ID。
- Container 中进程交互还是采用 linux 常见的进程间交互方法 (interprocess communication – ipc),包括常见的信号
-
mnt namespace
mnt namespace 允许不同 namespace 的进程看到的文件结构不同,这样每个 namespace 中的进程所看到的文件目录就被隔离开了。 -
uts namespace
UTS( "UNIX Time-sharing System" )namespace允许每个 container 拥有独立的 hostname 和 domain name,使其在
网络上可以被视作一个独立的节点而非 Host 上的一个进程。 -
user namespace
每个 container 可以有不同的 user 和 group id,也就是说可以在 container 内部用 container 内部的用户执行程序而非Host 上的用户。
namespace 的常用操作
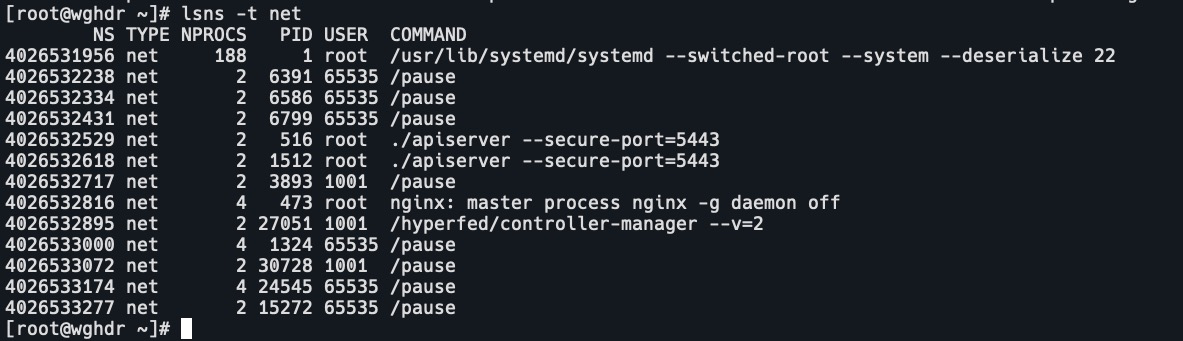
- 查看当前系统的 namespace:
lsns -t <type>
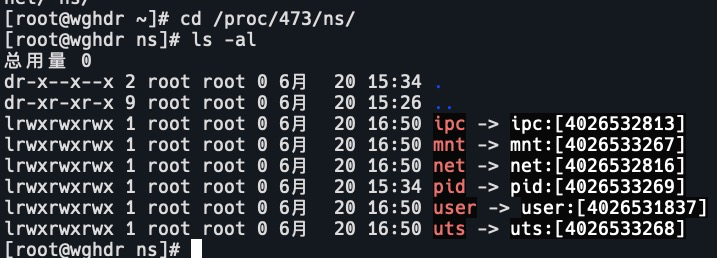
- 查看某进程的 namespace:
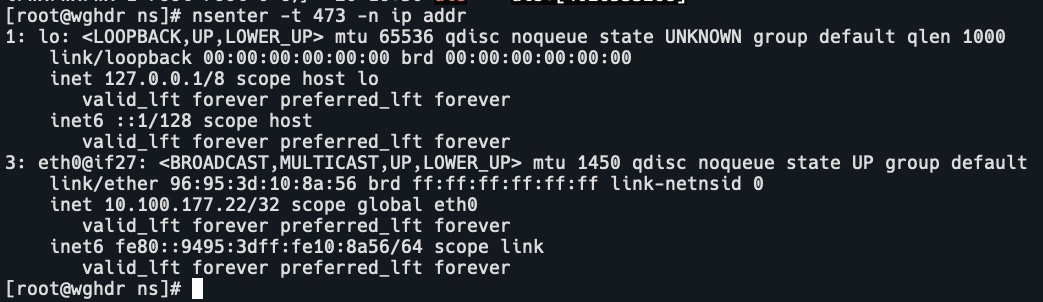
Is -la /proc/spid>/ns/ - 进入某 namespace 运行命令:
nsenter -t <pid> -n ip addr
8.Cgroups
- Cgroups (Control Groups)是 Linux 下用于对一个或一组进程进行资源控制和监控的机制;
- 可以对诸如 CPU 使用时间、内存、磁盘 I/0 等进程所需的资源进行限制;
- 不同资源的具体管理工作由相应的 Cgroup 子系统(Subsystem)来实现;
- 针对不同类型的资源限制,只要将限制策略在不同的的子系统上进行关联即可;
- Cgroups 在不同的系统资源管理子系统中以层级树(Hierarchy)的方式来组织管理:每个Cgroup 都可以包含其他的子Cgroup,因此子 Cgroup 能使用的资源除了受本 Cgroup 配置的资源参数限制,还受到父Cgroup 设置的资源限制。
Linux 内核代码中 Cgroups 的实现
进程数据结构
struct task struct {
#ifdef CONFIG CGROUPS
struct css_set_rcu *cgroups;
struct list_head cg_list;
#endif
}css_set 是 cgroup_subsys_state 对象的集合数据结构
struct css_set {
/*
*Set of subsystem states, one for each subsystem. This array is immutable after creation apart from the init_css_set during subsystem registration (at boot time).
*/
struct cgroup_subsys_state *subsySICGROUP_SUBSYS_COUNTI;
};子系统

cgroups 实现了对资源的配额和度量。
- blkio:
设置限制每个块设备的输入输出控制。例如:磁盘,光盘以及 USB 等等 - cpu:
使用调度程序为 cgroup 任务提供 CPU 的访问 - cpuacct:
产生 cgroup 任务的 CPU 资源报告 - cpuset:
如果是多核心的 CPU,会为 cgroup 任务分配单独的 CPU 和内存。这样CPU就不用进程切换了,性能更高效。 - devices:
允许或拒绝 cgroup 任务对设备的访问 - freezer:
暂停和恢复 cgroup 任务 - memory:
设置每个 cgroup 的内存限制以及产生内存资源报告 - net_cls:
标记每个网络包以供 cgroup 方便使用 - ns:
名称空间子系统 - pid:
进程标识子系统
CPU 子系统
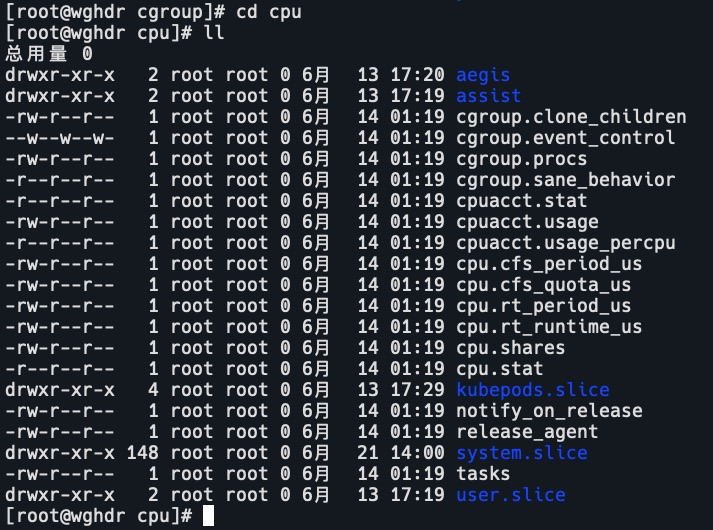
- cpu.shares:
可出让的能获得 CPU 使用时间的相对值。即占用的百分比。
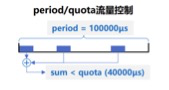
- cpu.cfs_period_us:
绝对时间。用来配置时间周期长度,单位为 us(微秒)。分母。 - cpu.cfs_quota_us:
用来配置当前 Cgroup 在 cfs_period_us 时间内最多能使用的 CPU 时间数,单位为 uS(微秒)。分子。
- cpu.stat:
Cgroup 内的进程使用的 CPU 时间统计。 - nr_periods:
经过 cpu.cfs_period_us 的时间周期数量。 - nr throttled:
在经过的周期内,有多少次因为进程在指定的时间周期内用光了配额时间而受到限制。 - throttled time
Cgroup 中的进程被限制使用 CPU 的总用时,单位是 ns(纳秒)。

shares和cfs_quota/period_us的区别
- cpu.shares是相对时间,如果有人竞争那么就按照这个百分比来划分,没人竞争的话就可以一直用。比如有两个进程分别占用的cpu百分比是50%,但是它什么都没跑没有占用cpu,那么另一个进程就可以把把全部的CPU吃掉。
- cfs_quota/period_us是绝对时间。比如进程划分了0.5个cpu,那么它只能用0.5个cpu,不能超过它。
Linux调度器
内核默认提供了5个调度器,Linux内核使用struct sched_class来对调度器进行抽象:
- Stop调度器,stop_sched_class:优先级最高的调度类,可以抢占其他所有进程,不能被其他进程抢占;
- Deadline调度器,dLsched_class:使用红黑树,把进程按照绝对截止期限进行排序,选择最小进程进行调度运行;
- RT调度器,rt_Sched_class:实时调度器,轮询的,保证实效性;调度器优先级最高。
- CFS调度器,cfs_sched_class:完全公平调度器,采用完全公平调度算法,引入虚拟运行时间概念;一般普通用户用的是这个调度器。调度器优先级次优。
- IDLE-Task调度器,idle_sched_class:空闲调度器,每个CPU都会有一个idle线程,当没有其他进程可以调度时,调度运行idle线程;
CFS调度器
- CFS是Completely Fair Scheduler简称,即完全公平调度器
- CFS 实现的主要思想是维护为任务提供处理器时间方面的平衡,这意味着应给进程分配相当数量的处理器。
- 分给某个任务的时间失去平衡时,应给失去平衡的任务分配时间,让其执行。
- CFS通过虚拟运行时间(vruntime)来实现平衡,维护提供给某个任务的时间量。
vruntime =实际运行时间*1024 / 进程权重 - 进程按照各自不同的速率在物理时钟节拍内前进,优先级高则权重大,其虚拟时钟比真实时钟跑得慢,但获得比较多的运行时间
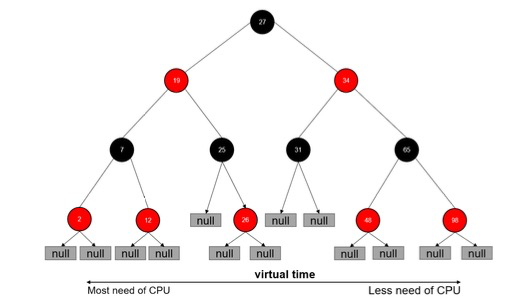
vruntime红黑树
CFS调度器没有将进程维护在运行队列中,而是维护了一个以虚拟运行时间为顺序的红黑树。红黑树的主要特点有:
- 自平衡,树上没有一条路径会比其他路径长出俩倍。
- O(log n)时间复杂度,能够在树上进行快速高效地插入或删除进程。
- 把vruntime最小的放在左边,最大的放在右边。调度的时候从最左边即最需要CPU的进程调度。
实例
在 /sys/fs/cgroup/cpu 目录中创建目录
mkdir /sys/fs/cgroup/cpu/cpudemo
启动for循环脚本,消耗CPU
cat main.go
package main
func main() {
go func() {
for {
}
}()
for {
}
}
go build
./busyloop
查看CPU占和pid

添加进程到cpudemo
cd /sys/fs/cgroup/cpu/cpudemo
echo 20948 > cgroup.procs
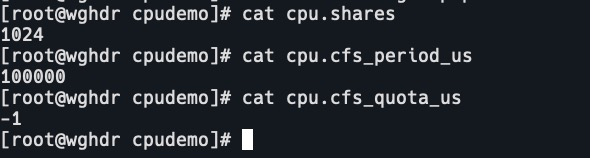
查看默认cpu cgroup
cpu.shares:1024
cpu.cfs_period_us:100000 100微秒
cpu.cfs_quota_us:-1 不限制
设置cpu.cfs_quota_us,使用1个CPU
echo 100000 > cpu.cfs_quota_us
设置cpu.cfs_quota_us,使用0.5个CPU
echo 50000 > cpu.cfs_quota_us
cpuacct 子系统
用于统计 Cgroup 及其子 Cgroup 下进程的 CPU 的使用情况。
- cpuacct.usage
包含该 Cgroup 及其子 Cgroup 下进程使用 CPU 的时间,单位是 ns(纳秒)。 - cpuacct.stat
包含该 Cgroup 及其子 Cgroup 下进程使用的 CPU 时间,以及用户态和内核态的时间。
Memory 子系统

- memory.usage_in_bytes
cgroup 下进程使用的内存,包含 cgroup 及其子 cgroup 下的进程使用的内存 - memory.maxusage in_ bytes
cgroup 下进程使用内存的最大值,包含子 cgroup 的内存使用量。 - memory.limit_in bytes
设置 Cgroup 下进程最多能使用的内存。如果设置为-1,表示对该 cgroup 的内存使用不做限制。 - memory.oom_control
设置是否在 Cgroup 中使用 OOM (Out of Memory) Killer,默认为使用。当属于该 cgroup 的进程使用的内存超过最大的限定值时,会立刻被 OOM Killer 处理。
Cgroup driver
- Systemd:
- 当操作系统使用systemd作为init system时,初始化进程生成一个根cgroup目录结构并作为cgroup管理器。
- systemd与cgroup紧密结合,并且为每个Systemd unit分配cgroup。
- cgroupfs:
docker默认用cgroupfs作为cgroup驱动。
存在问题:
- 在systemd作为init system的系统中,默认并存着两套groupdriver。
- 这会使得系统中docker和kubelet管理的进程被cgroupfs驱动管,而systemd拉起的服务由systemd驱动管,让cgroup管理混乱且容易在资源紧张时引发问题。
因此kubelet会默认–cgroup-driver=systemd,若运行时cgroup不一致时,kubelet会报错。
ps aux|grep kubelet
cat /var/lib/kubelet/config.yaml
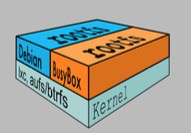
9.Union FS文件系统
- 将不同目录挂载到同一个虚拟文件系统下的文件系统。
- 支持为每一个成员目录(类似Git Branch)设定readonly、 readwrite和writeable权限
- 文件系统分层,对readonly权限的branch可以逻辑上进行修改(增量地,不影响 eadonly部分的)。
- 通常Union FS有两个用途,一方面可以将多个disk挂到同一个目录下,另一个更常用的就是将一个readonly的branch和一个 writeable的branch联合在一起。
docker的文件系统
- Bootfs (boot file System):
- Bootloader -引导加载 kernel
- Kernel – 当 kernel被加载到内存中后 umountbootfs
- rootfs (root file System):
- /dev, /proc, /bin, /etc 等标准目录和文件。
- 对于不同的 Linux 发行版,bootfs 基本是一致的,但 rootfs 会有差别。

docker启动
- Linux启动
在启动后,首先将rootfs设置为readonly,进行一系列检查,然后将其切换为readwrite供用户使用。 - Docker启动
- 初始化时也是将rootfs以readonly方式加载并检查,然而接下来利用union mount的方式将一个readwrite文件系统挂载在readonly的rootfs之上;
- 然后将下层的 FS设定为readonly并且向上叠加。
- 这样一组readonly和一个writeable的结构构成一个container的运行时态,每一个 FS被称作一个FS层。
写操作
由于镜像具有共享特性,所以对容器可写层的操作需要依赖存储驱动提供的写时复制和用时分配机制,以此来支持对容器可写层的修改,进而提高对存储和内存资源的利用率。
- 写时复制
即 Copy-on-Write。确保了底下的基础镜像不被修改。
一个镜像可以被多个容器使用,但是不需要在内存和磁盘上做多个拷贝。在需要对基础镜像层进行修改时,可以复制到容器的可写层的进行修改,在上层进行覆盖,而基础镜像里面的文件不会改变。不同容器对文件的修改都相互独立、互不影响。 - 用时分配
按需分配空间,而非提前分配,即当一个文件被创建出来后,才会分配空间。
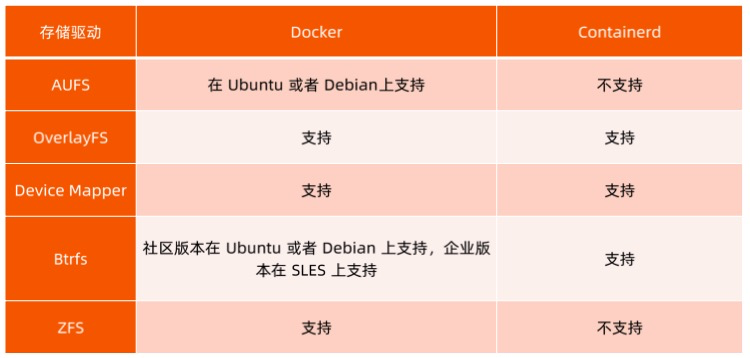
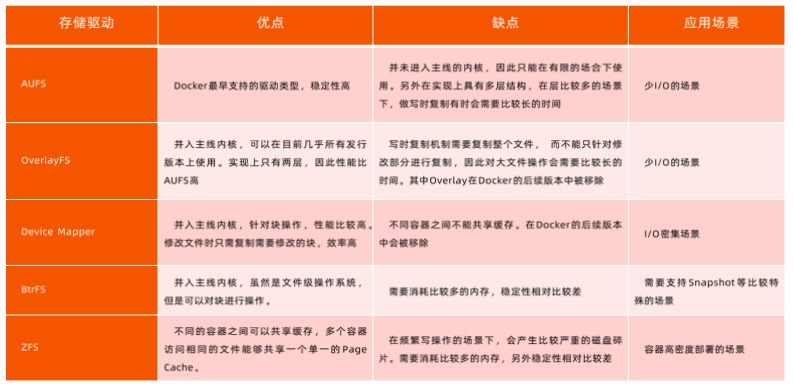
容器存储驱动
OverlayFS
OverlayFS 也是一种与 AUFS 类似的联合文件系统,同样属于文件级的存储驱动,包含了最初的Overlay和更稳定的 overlay2。
Overlay 只有两层:upper 层和 lower 层,lower 层代表镜像层,upper 层代表容器可写层。

实例
创建测试目录和测试文件
mkdir overlayfs
cd overlayfs
mkdir upper lower merged work
echo "from lower" > lower/in_lower.txt
echo "from upper" > upper/in_upper.txt
echo "from lower" > lower/in_both.txt
echo "from upper" > upper/in_both.txt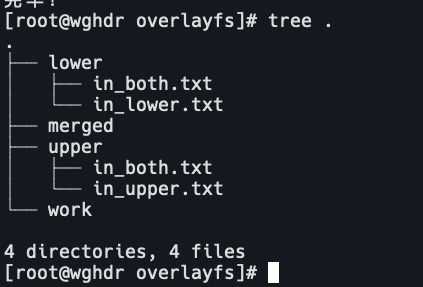
将upper和lower目录合并到一起
sudo mount -t overlay overlay -o lowerdir=`pwd`/lower,upperdir=`pwd`/upper,workdir=`pwd`/work `pwd`/merged
查看merged目录文件
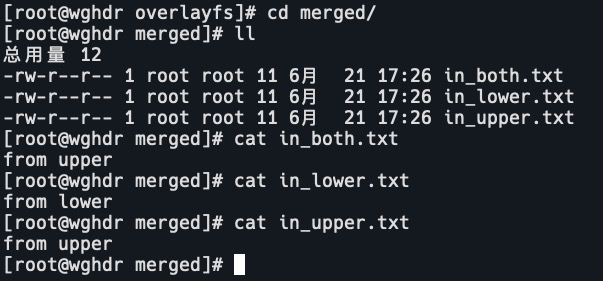
把lower和upper目录以overlayfs的形式mount到一个虚拟目录时,它整合了上册和下层的文件。
删除merged目录文件,查看lower和upper目录
rm -f in_both.txt
rm -f in_lower.txt
rm -f in_upper.txt
ll ../lower
ll ../upper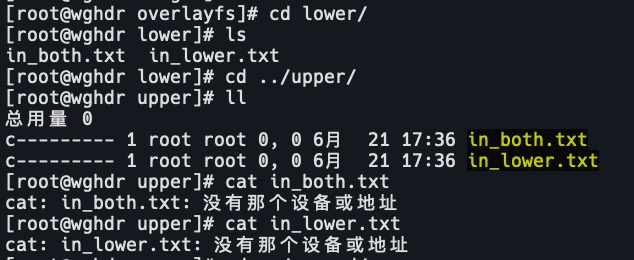
merged目录中删除文件,upper目录会做对应修改,lower目录不会变。
在upper目录中新建文件

OCl 容器标准
OCI:Open Container Initiative
OCI组织于 2015 年创建,是一个致力于定义容器镜像标准和运行时标准的开放式组织。
OCI定义了镜像标准(Image Specification)、运行时标准(Runtime Specification )和分发标准(Distribution Specification)
- 镜像标准定义应用如何打包
- 运行时标准定义如何解压应用包并运行
- 分发标准定义如何分发容器镜像
Docker 引擎架构
docker命令发送到docker-daemon,daemon再通过grpc连接到containerd,containerd再启动shim进程,shim再通过runc(底层运行时的接口)启动容器进程。

shim的作用
在早期,docker启动容器是直接通过daemon启动容器进程的,没有containerd下面那些。daemon进程就是所有容器进程的父进程。当升级或者重启docker时。父进程不存在了,所有的容器进程都会重启。
有了containerd后,它不作为父进程,而是启动一个shim进程来维护容器的生命周期。shim进程交给操作系统来管理,比如systemd。containerd下面没有任何子进程,可以随便重启升级。容器都不受影响。这样控制组件和数据面组件分离开了。
10.容器网络
- Null(–net=None)
创建一个网络namespace,但是不做配置,需要用户自己通过运行 docker network 命令来完成网络配置。
k8s使用网络插件来完成网络配置,即使用了null模式。 - Host
使用主机网络名空间,复用主机网络。
比如作为管理员需要配置主机网络,启动的容器就可以使用主机网络,这样就可以通过容器来修改主机网络。 - Container
重用其他容器的网络。
可以使用container模式创建多个互相调用的容器,都在一个网络namespace下,就相当于本地调用。当然也可以放在一个镜像中。 - Bridge(–net=bridge)
默认模式。使用 Linux 网桥和 iptables 提供容器互联,Docker 在每台主机上创建一个名字叫docker0的网桥,通过 veth pair 来连接该主机的每一个 EndPoint。
原理和下面的实例中过程一样,创建veth pair;把一端连到docker0,另一端连到容器的eth0中;为eth0分配ip;如果有端口映射再配置iptables。
跨主机网络通信
- Overlay(libnetwork, Libky)
从容器里出来的数据包在主机层添加一层包头,把本地地址作为源地址,把对端地址作为目标地址,到达目标主机后拆包。vxlan,ipip,gre等。网络插件比如flannel和calico。 - Remote(work with remote drivers)
- Underlay:
使用现有底层网络,为每一个容器配置可路由的网络 IP。由于容器会消耗大量的ip地址,需要很好的规划。
创建一个网桥;把主机网卡配置到网桥中;默认路由到网桥;启动容器,创建veth对,一端在网桥,一端在容器网卡。
- Overlay:
通过网络封包实现。
- Underlay:

实例
使用null模式创建容器,观察容器网络的变化。
创建nginx容器
docker run --network=none -d nginx
docker ps
查看容器pid,进入net ns
docker inspect 0051ecc1f947 | grep -i pid
nsenter -t 26708 -n ip a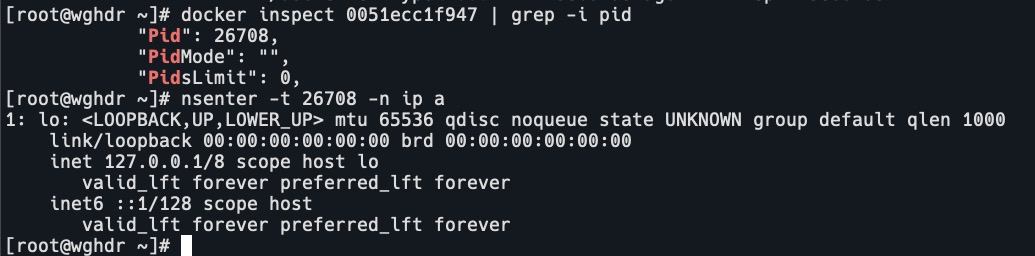
可以看到容器现在只有loopback口,没有任何的网络配置。
创建net ns
mkdir /var/run/netns
ll netns/把容器进程和net ns关联
export pid=26708
ln -s /proc/$pid/ns/net /var/run/netns/$pid
ll netns/
ip netns list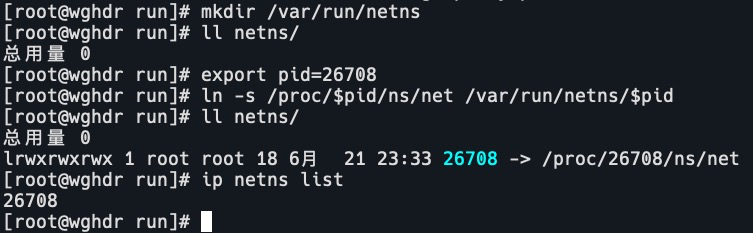
查看docker0网桥
brctl show
ip a
创建网络veth对(virtual ethernet 虚拟以太网)
ip link add A type veth peer name B
配置A,把网线插到docker0上
brctl addif docker0 A
ip link set A up
配置B,即配置容器网络,网关为docker0
SETIP=172.18.0.100
SETMASK=16
GATEWAY=172.18.0.1
# 把B放到上面创建的net ns中
ip link set B netns $pid
# 进入net ns设置设备B名字为eth0
ip netns exec $pid ip link set dev B name eth0
# 开启eth0
ip netns exec $pid ip link set eth0 up
# 配置eth0网络
ip netns exec $pid ip addr add $SETIP/$SETMASK dev eth0
ip netns exec $pid ip route add default via $GATEWAY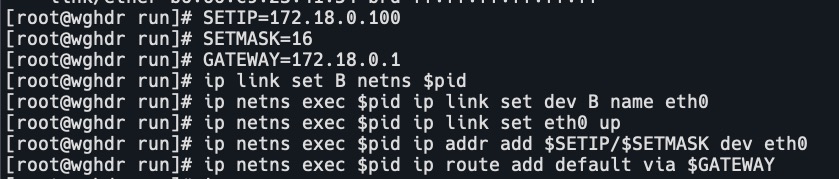

检查连通性
curl 172.18.0.100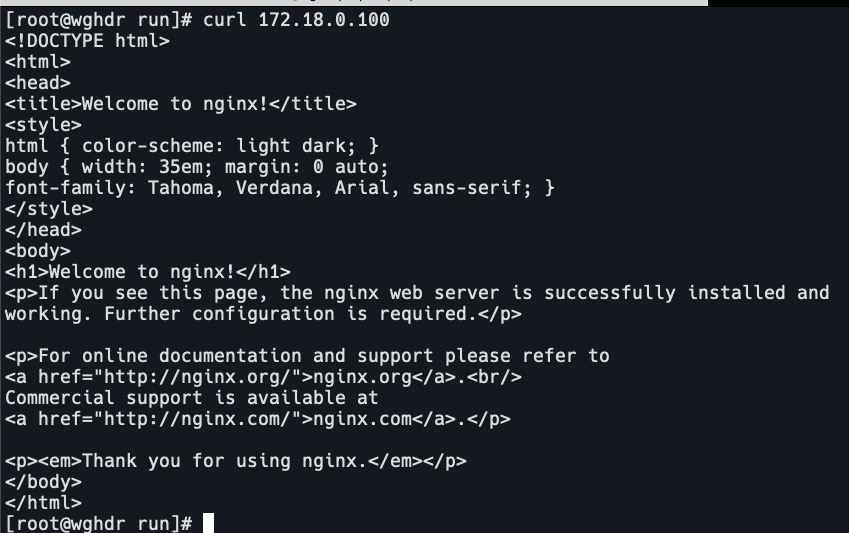
再次进入net ns查看网络配置
nsenter -t 26708 -n ip a
11.Dockerfile
以源代码的形式在Dockerfile中定义全部应用所需的依赖。再通过docker build来读取文件中的指令并运行,最后生成一个容器镜像。
构建上下文(build context)
当运行 docker build 命令时,当前工作目录被称为构建上下文。
docker build 默认查找当前目录的 Dockerfile 作为构建输入,也可以通过下面的命令指定 Dockerfile。
docker build -f ./Dockerfile当 docker build 运行时,首先会把构建上下文传输给 docker daemon,把没用的文件包含在构建上下文时,会导致传输时间长,构建需要的资源多,构建出的镜像大等问题。
比如下面两条命令:
docker build -f /httpserver/Dockerfile .
docker build /httpserver/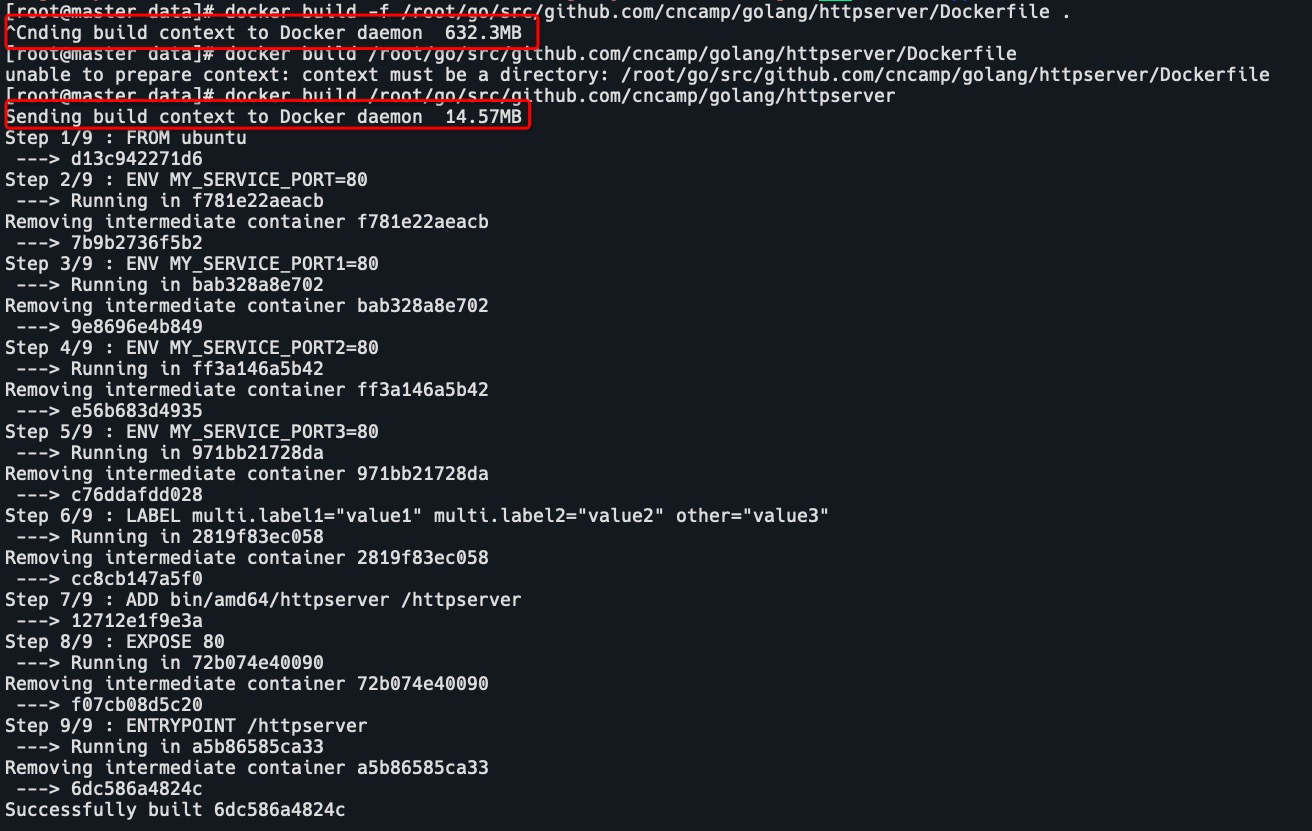
可以通过.dockerignore文件从编译上下文排除某些文件。
因此需要确保构建上下文清晰,比如创建一个专门的目录放置Dockerfile,并在目录中运行 docker build。
镜像构建日志
通过日志可以看到在构建镜像时到底在做什么。具体日志信息可以参考上方的图片。
Build Cache
构建容器镜像时,Docker 依次读取 Dockerfile 中的指令,并按顺序依次执行构建指令。
Docker 读取指令后,会先判断缓存中是否有可用的已存镜像,只有已存镜像不存在时才会重新构建。已存在的镜像会提示“Using Cache”
- 针对 ADD 和 COPY 指令,Docker 判断该镜像层每一个文件的内容并生成一个 checksum,与现存镜像比较时,Docker 比较的是二者的 checksum。
- 其他指令,比如 RUN apt-get -y update,Docker 简单比较与现存镜像中的指令字串是否一致。
- 当某一层 cache 失效以后,所有所有层级的 cache 均一并失效,后续指令都重新构建镜像。
- 尽量把不变的层放在下面,把变动频繁的放在上层,可以更多的使用缓存提升构建效率。
多段构建 (Multi-stage build)
这是有效减少镜像层级的方式。第一段中下载所需的代码文件,比如可以编译成一个二进制文件;然后第二段中再拷贝二进制文件,这样生成的镜像就会很小。
FROM golang:1.16-alpine As build
RUN apk add --no-cache git
RUN go get github.com/golang/dep/cmd/dep
COPY Gopkg.lock Gopkg.toml /go/src/project/
WORKDIR /go/Src/project/
RUN dep ensure -vendor-only
COPY . /go/src/project/
RUN go build -O /bin/project
FROM scratch
COPY --from=build /bin/project /bin/project
ENTRYPOINT ["/bin/project"]
CMD I"--help"]Dockerfile 常用指令
- FROM:选择基础镜像,推荐 alpine
FROM [--platform=<platform>] <image> [@<digest>] [AS sname>] - LABELS:按标签组织项目
LABEL multi.labell="value1" multi.label2="value2" other="value3"配合 label filter 可过滤镜像查询结果
docker images -f label=multi.labell="value1" - RUN:执行命令
最常见的用法是RUN apt-get update && apt-get install这两条命令应该永远用&&连接,如果分开执行,
RUN apt-get update构建层被缓存,可能会导致新 package 无法安装。 - CMD:容器镜像中包含应用的运行命令,需要带参数
CMD ["executable", "param1", "param2"..] - EXPOSE:发布端口
EXPOSE <port> I<port>/≤protocol>...]是镜像创建者和使用者的约定,在 docker run -P 时,docker 会自动映射 expose 的端口到主机上随机端口,如0.0.0.0:32768->80/tcp
- ENV 设置环境变量
ENV <key>=<value>… - ADD:从源地址(文件,目录或者 URL)复制文件到目标路径
ADD [--chown=<user>:<group>] <src>... <dest> ADD I--chown=<user>:<group>]["<src>",..."<dest>"〕(路径中有空格时使用)- ADD 支持 Go 风格的通配符,如 ADD check* /testdir/
- src 如果是文件,则必须包含在编译上下文中,ADD 指令无法添加编译上下文之外的文件
- src 如果是 URL
- 如果 dest 结尾没有/,那么 dest 是目标文件名,如果 dest 结尾有/,那么 dest 是目标目录名
- 如果 src 是一个目录,则所有文件都会被复制至 dest
- 如果 src 是一个本地压缩文件,则在 ADD 的同时完整解压操作
- 如果 dest 不存在,则 ADD 指令会创建目标目录
- 应尽量减少通过 ADD URL 添加 remote 文件,建议使用 curl 或者 wget && untar
- COPY:从源地址(文件,目录或者URL)复制文件到目标路径
COPY I--chown=cuser>:<group>] <src>... <dest> COPY [--chown=<user>:<group>]["<src>"…"<dest>"]// 路径中有空格时使用COPY 与ADD的区别:
- COPY 只支持本地文件的复制,不支持URL
- COPY 不解压文件
- COPY 可以用于多阶段编译场景,可以用前一个临时镜像中拷贝文件
- COPY 语义上更直白,复制本地文件时,优先使用 COPY
- ENTRYPOINT:定义可以执行的容器镜像入口命令
ENTRYPOINT ["executable","param1","param2"] // docker run参数追加模式 ENTRYPOINT command param1 param2 // docker run 参数替换模式docker run –entrypoint 可替换 Dockerfile 中定义的ENTRYPOINT
ENTRYPOINT 的最佳实践是用 ENTRYPOINT 定义镜像主命令,并通过 CMD 定义主要参数,如下所示ENTRYPOINT ["S3cmd"] CMD ["--help"] - VOLUME:将指定目录定义为外挂存储卷,Dockerfile 中在该指令之后所有对同一目录的修改都无效
VOLUME ["/data"] 等价于 docker run -V /data,可通过 docker inspect 查看主机的 mount point, /var/lib/ docker/volumes/scontainerid>/_dataUSER:切换运行镜像的用户和用户组,因安全性要求,越来越多的场景要求容器应用要以 non-root 身份运行
USER <user>:[<group>] - WORKDIR:等价于 cd,切换工作目录
WORKDIR /path /to/workdir - 其他非常用指令
ARG
ONBUILD
STOPSIGNAL
HEALTHCHECK
SHELL
最佳实践
目标:易管理、少漏洞、镜像小、层级少、利用缓存
- 不要安装无效软件包
- 应简化镜像中同时运行的进程数,理想状况下,每个镜像应该只有一个进程。
- 当无法避免同一镜像运行多进程时,应选择合理的初始化进程 (init process)
- 最小化层级数
- 最新的 docker 只有 RUN, COPY,ADD 创建新层,其他指令创建临时层,不会增加镜像大小,比如 EXPOSE 指令就不会生成新层
- 多条 RUN 命令可通过连接符连接成一条指令集以减少层数
- 通过多段构建减少镜像层数
- 把多行参数按字母排序,可以减少可能出现的重复参数,并且提高可读性
- 编写 dockerfile 的时候,应该把变更频率低的编译指令优先构建以便放在镜像底层以有效利用 build cache
- 复制文件时,每个文件应独立复制,这确保某个文件变更时,只影响改文件对应的缓存
多进程的容器镜像
选择适当的 init 进程
- 需要捕获 SIGTERM 信号并完成子进程的优雅终止
- 负责清理退出的子进程以避免僵尸进程
可以使用开源项目,把tini作为容器的ENTRYPOINT,它可以传递SIGTERM 信号,还可以负责清理异常退出的子进程。
https://github.com/krallin/tini
镜像管理
docker save/load
docker tag
docker push/pull版本管理
docker tag 命令可以为容器镜像添加标签
docker tag 0e5574283393 hub.docker.com/httpserver:v1.0
hub.docker.com:镜像仓库地址,如果不填,则默认为hub.docker.com: repositry
httpserver:镜像名
v1.0:tag,常用来记录版本信息
镜像仓库
Docker hub
https://hub.docker.coml
创建私有镜像仓库
docker run -d -p 5000:5000 registry
docker的劣势
隔离性:多个容器共用宿主机的内核,各应用之间的隔离不如虚拟机彻底。