pod完整生命周期参考这里,下面说一下具体每种异常状态应该怎么排查。
Init:0/1
初始化容器失败,需要查看日志分析。
Pending
pod一直处于Pending状态,说明pod还没有被调度到某个节点上,需要使用下面的命令查看一下event信息。
kubectl describe pod1.资源不足
查看events日志可以看到类型的信息:
Warning FailedScheduling 3m (x106 over 33m) default-scheduler 0/3 nodes are available: 1 node(s) had no available volume zone, 2 Insufficient cpu, 3 Insufficient memory.资源不足有3种情况:
- CPU不足
- 内存不足
- GPU不足
如何确定节点资源情况,
kubectl describe node <node-name>
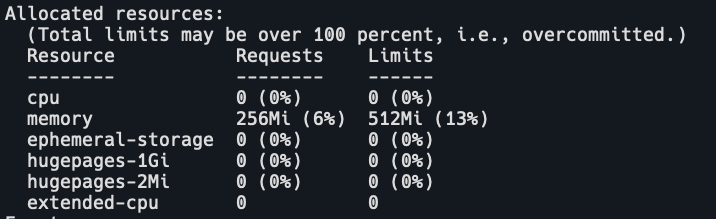
其中:
- Capacity:表示节点总资源大小
- Allocatable::表示此节点能够申请的资源总和
- Allocated resources::表示此节点已分配的资源
确定pod所需的requests大小,如果Allocatable- Allocated resources小于pod的request,那么这个node在调度的预选阶段就会被踢出,pod就无法调度到这个节点上。
解决
如果node资源理论上是够的,就需要看node上是否有应用使用异常。如果资源使用正常,就需要扩容了。
2.不满足 nodeSelector 与 affinity
如果节点打了label,而pod的nodeSelector没有指定所需的label,那么pod就无法调度到这个node上。


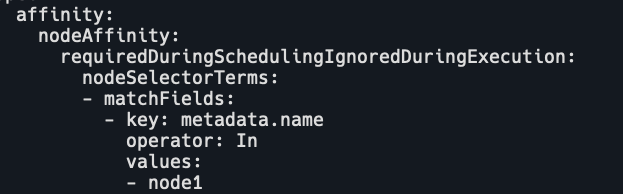
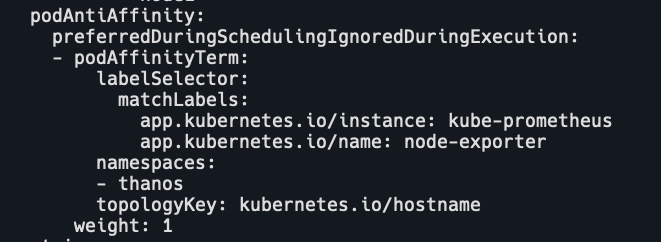
affinity包括pod affinity和node affinity,
- nodeAffinity: 节点亲和性,可以看成是增强版的 nodeSelector,用于限制 Pod 只允许被调度到某一部分 Node。

- podAffinity: Pod 亲和性,用于将一些有关联的 Pod 调度到同一个地方,比如同一个节点或同一个可用区的节点等。
- podAntiAffinity: Pod 反亲和性,用于避免将某一类 Pod 调度到同一个地方避免单点故障,比如将集群 DNS 服务的 Pod 副本都调度到不同节点,避免一个节点挂了造成整个集群 DNS 解析失败,使得业务中断。
解决
node添加对应的label;affinity的required改成prefer,前提是你了解这么改带来的影响。
3.node有taint,pod没有容忍
查看node的taint:
kubectl describe node node1
查看pod的tolerations:
kubectl get po -o yaml
我这里taints没有设置,假如node有下面的taint,
Taints: test=true:NoSchedulepod如果没有对应的tolerations,pod就无法调度到这个node上。
解决
1.pod添加容忍
tolerations:
- key: "test"
operator: "Equal"
value: "true"
effect: "NoSchedule"2.删除taint
kubectl taint nodes node1 test-附录
新加入集群的node,一般是不允许pod调度到这个node上的,需要等待node初始化成功,状态变为ready后再删除这个taint。这时就可以给node添加下面的taint:
kubectl taint node node1 node.kubernetes.io/uninitializedunschedulable
# 或者
kubectl taint node node1 node.kubernetes.io/uninitialized如果node异常,node也会自动被添加上taint。
Conditon Value Taints
-------- ----- ------
OutOfDisk True node.kubernetes.io/out-of-disk
Ready False node.kubernetes.io/not-ready
Ready Unknown node.kubernetes.io/unreachable
MemoryPressure True node.kubernetes.io/memory-pressure
PIDPressure True node.kubernetes.io/pid-pressure
DiskPressure True node.kubernetes.io/disk-pressure
NetworkUnavailable True node.kubernetes.io/network-unavailable4.kube-scheduler异常
检查 maser 上的 kube-scheduler 是否运行正常,异常的话可以尝试重启临时恢复。
5.pv或者pvc异常
pod指定了pvc,storageClass为本地存储,没有设置provisioner,这时如果只创建了pvc而没有创建pv,pvc就会异常,pod就会处于pending状态。
解决
创建对应的pv,或者使用动态provisioner,比如nfs-client-provisioner,ceph等,这样只需要指定pvc的配置,就会自动创建出对应的pv。
6.可用的pod和磁盘不在同一个可用区
pod和挂载的磁盘都在可用区A中。如果pod被驱逐了,可用区A中的node都不符合条件,即使可用区B中有node符合条件,也无法调度到B中的node,pod处于pending状态。
原因
磁盘无法跨可用区挂载,而且网络延时会极大的降低 IO 速率。
Unknown
pod处于Unknown状态,一般是node失联了,没有上报状态给 apiserver。
可能的原因有:
- 节点高负载导致无法上报
- 节点宕机
- 节点被关机
- 网络不通
CrashLoopBackOff
pod处于CrashLoopBackOff状态说明pod之前启动过,但是又异常退出了,pod的restartPolicy不是Never,pod就会重启。查看Pod的Restarts大于0。
1.容器进程主动退出
如果是容器进程主动退出,pod的退出状态码一般在 0-128 之间,也可能是业务程序 BUG,需要查看容器日志分析。
2.健康检查失败
健康检查配置不合理
initialDelaySeconds太短,容器启动慢,导致容器还没完全启动就开始探测,如果successThreshold是默认值 1,检查失败一次就会被kill,然后pod一直这样被kill重启。
容器内进程端口挂掉
使用 netstat -alnp 检查端口监听是否还在,如果不在了,健康检查连接异常,从而健康检查失败。
节点负载过高
cpu 占用高会导致进程无法正常发包收包,连接超时,导致kubelet认为pod不健康。
3.容器OOM
查看pod的events可以看到OOMKilled,说明容器实际占用的内存超过limit了,查看内核日志会报: Memory cgroup out of memory。
解决
根据需求调整limit。
4.系统OOM
如果发生系统OOM,表示被SIGKILL信号杀死,同时内核会报错: Out of memory: Kill process …。
大概率是节点上部署了其它非K8S管理的进程消耗了比较多的内存,或者 kubelet 的 --kube-reserved 和 –-system-reserved 配的比较小,没有预留足够的空间给其它非容器进程。


附录:退出状态码
通过kubectl describe pod可以看到上次退出时的状态码。如果不为 0,表示异常退出。
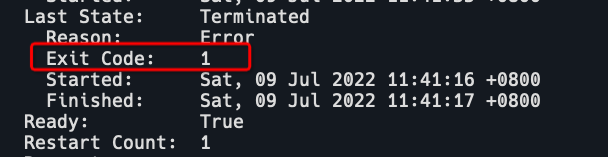
退出状态码的区间
- 必须在 0-255 之间
- 0 表示正常退出
- 外界中断导致程序退出的时候状态码区间在 129-255,(操作系统给程序发送中断信号,比如 kill -9 是 SIGKILL,ctrl+c 是 SIGINT)
- 一般程序自身原因导致的异常退出状态区间在 1-128 (这只是一般约定,程序如果一定要用129-255的状态码也是可以的)
假如代码指定的退出状态码时不在 0-255 之间,例如: exit(-1),这时会自动做一个转换,最终呈现的状态码还是会在 0-255 之间。
常见异常状态码
-
137 (被 SIGKILL 中断信号杀死)
- 一般是因为pod中容器内存达到了它的资源限制(resources.limits),即发生了内存溢出(OOM),CPU达到限制只需要不分时间片给程序就可以。cgroup会将此容器强制杀掉,类似于kill -9,pod中可以看到OOMKilled。
- 还可能是宿主机本身资源不够用了(OOM),内核会选取内存占用最大的进程杀掉来释放内存
- 不管是 cgroup 限制杀掉进程还是因为节点机器本身资源不够导致进程死掉,都可以从系统日志中找到记录:
ubuntu 的系统日志在/var/log/syslog,centos 的系统日志在/var/log/messages,都可以用journalctl -k来查看系统日志 - 也可能是livenessProbe检查失败,kubelet 杀死的 pod
- 还可能是被恶意木马进程杀死
-
1 和 255
具体错误原因只能看容器日志,因为很多程序员写异常退出时习惯用 exit(1) 或 exit(-1),-1 会根据转换规则转成 255
Linux 常见标准中断信号
Linux 程序被外界中断时会发送中断信号,程序退出时的状态码就是中断信号值加上 128 得到的,比如 SIGKILL 的中断信号值为 9,那么程序退出状态码就为 9+128=137。
SIGHUP 1
SIGINT 2
SIGKILL 9
SIGTERM 15Terminating
pod处于Terminating 状态参考这里:https://wghdr.top/archives/1534
ImagePullBackOff/ErrImagePull
这种状态是因为镜像下载失败,比如镜像地址在国外无法访问,harbor等仓库需要登录,镜像文件过大机器空间不足等。
Error
pod异常退出,且pod的restartPolicy是Never。
Evicted
pod被驱逐。可能的原因是使用的资源超出限制,node异常,node下线等。