现象
查看pod和svc的ip。
k get po,svc -n redis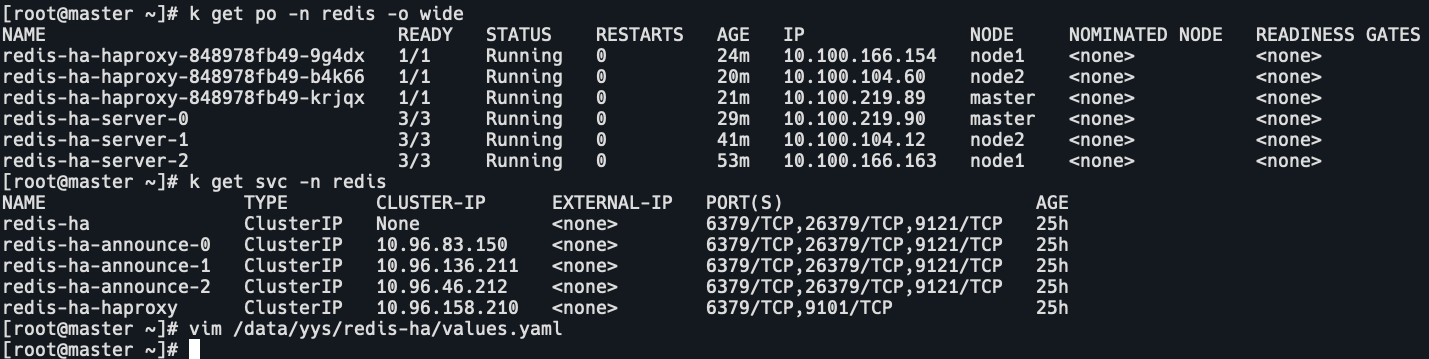
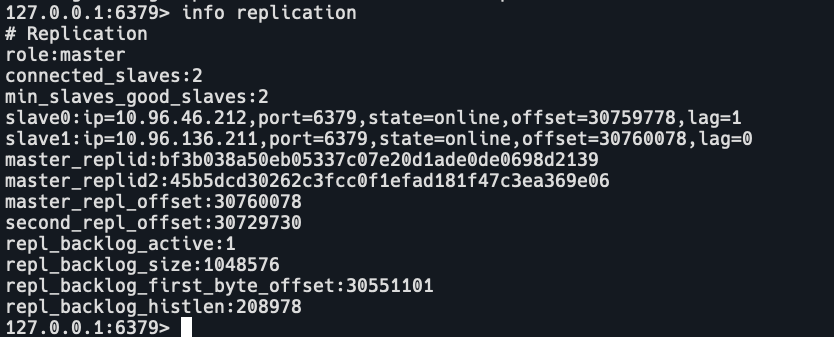
查看server0,master,只有一个slave,地址是10.96.83.150

查看server1,slave,master地址是10.96.136.211,salve地址是10.96.46.212
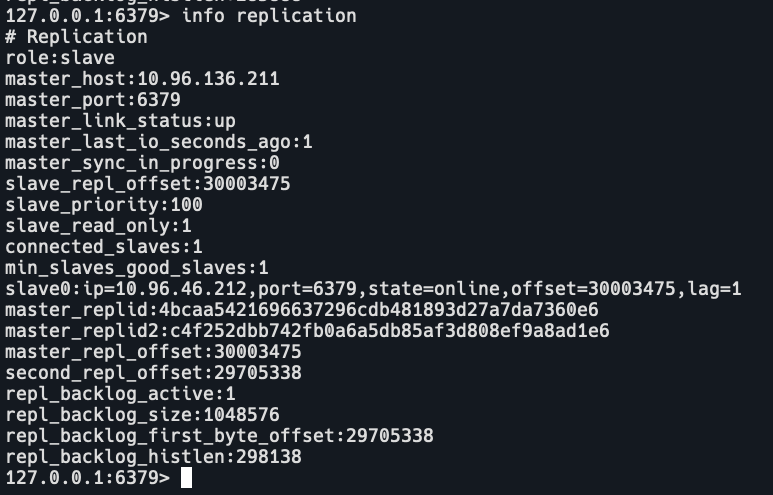
查看serevr2,slave,master地址是10.96.83.150,min_slaves_good_slaves:0

即server0和serevr2在一个集群里,server1单独一个集群。
查看哨兵日志
redis-master 10.96.136.211。
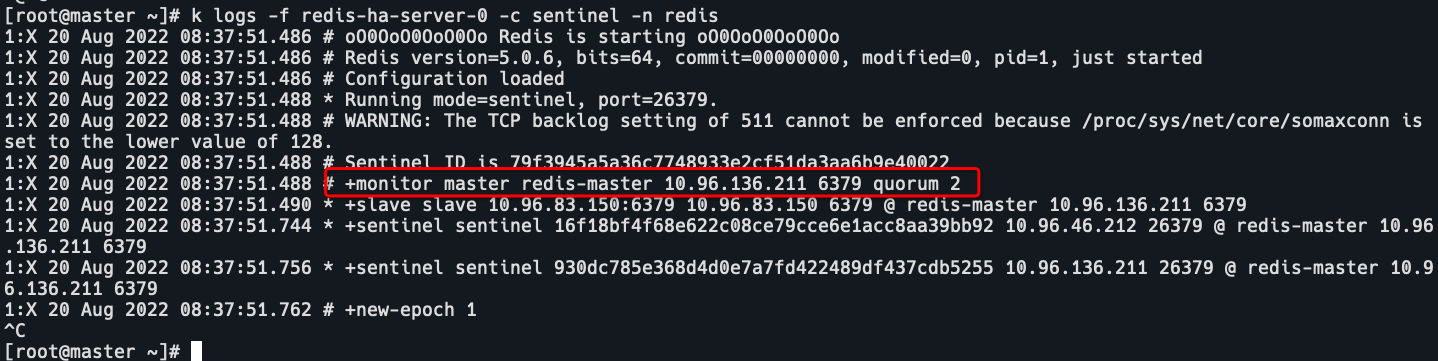
redis-master 10.96.83.150发生了FAILOVER,重新选举,选举了10.96.136.211为master。
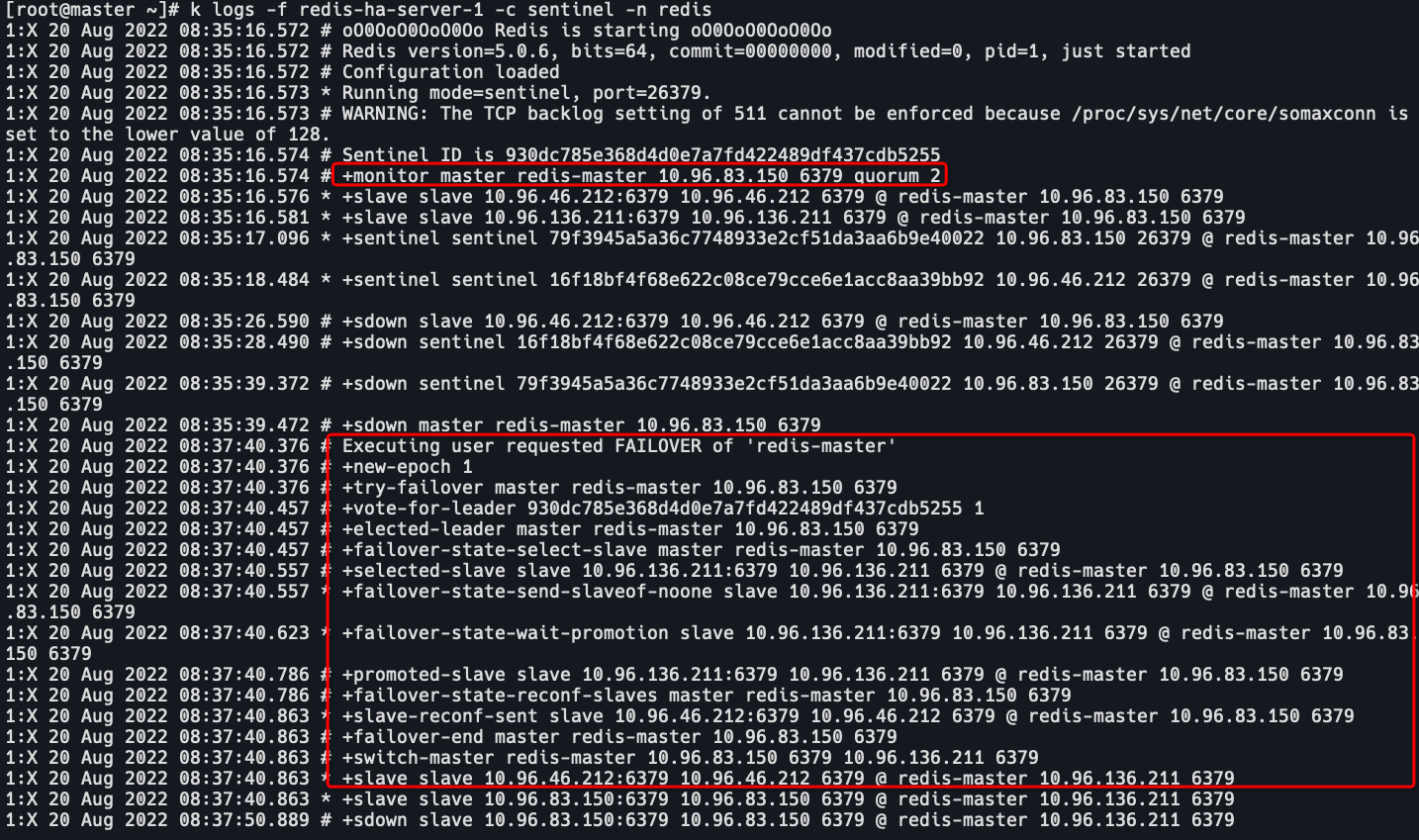
master是10.96.83.150,然后10.96.83.150reboot了,从10.96.136.211接收配置更新,切换到了10.96.136.211为master。
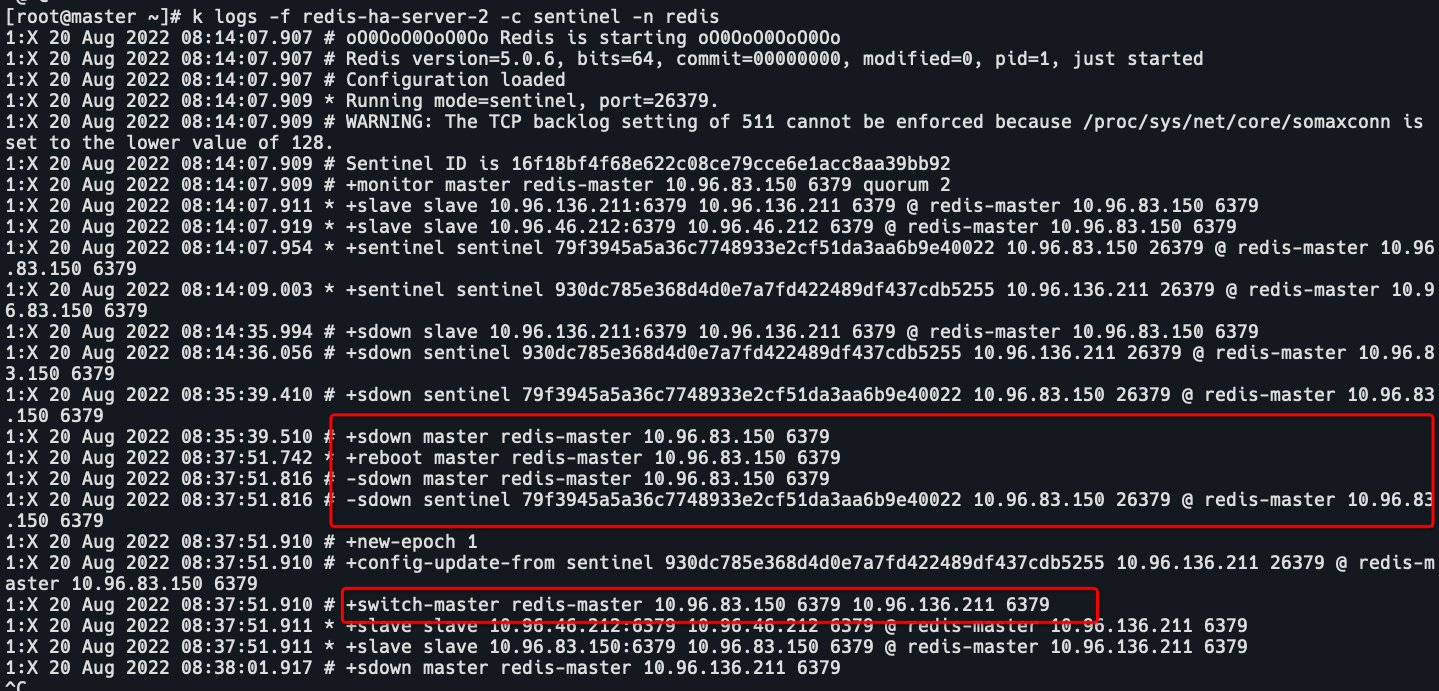
原因
如果当前主库突然出现暂时性 “失联”,而并不是真的发生了故障,此时监听的哨兵会自动启动主从切换机制。当这个原始的主库从假故障中恢复后,又开始处理请求,但是哨兵已经选出了新的主库,这样一来,旧的主库和新主库就会同时存在,这就是脑裂现象。
redis pod启动时间不同,导致了启动时选举异常。
影响
脑裂最直接的影响,就是客户端不知道应该往哪个主节点写入数据,结果就是不同的客户端会往不同的主节点上写入数据。严重的话,脑裂会进一步导致数据丢失。当哨兵恢复对老master节点的感知后,会将其降级为slave节点,然后从新maste同步数据(full resynchronization),导致脑裂期间老master写入的数据丢失。
如何判断数据丢失
数据丢失不一定是发生了脑裂,最常见的原因是主库的数据还没有同步到从库,结果主库发生了故障,等从库升级为主库后,未同步的数据就丢失了。
通过比对主从库上的复制进度差值来进行判断,也就是计算 master_repl_offset 和 slave_repl_offset 的差值。如果从库上的 slave_repl_offset 小于老master的 master_repl_offset,那么,我们就可以认定数据丢失是由数据同步未完成导致的。
而判断是否发生了脑裂,可以采取排查客户端的操作日志的方式。通过看日志能够发现,在主从切换后的一段时间内,会有客户端仍然在和老master通信,并没有和升级的新master进行交互,这就相当于主从集群中同时有了两个master。根据这个迹象,我们就可以判断可能是发生了脑裂。
解决
查看value.yaml

这两个配置就是用来解决redis脑裂。
min-slaves-to-write
是指主库最少得有 N 个健康的从库存活才能执行写命令。
这个配置虽然不能保证 N 个从库都一定能接收到主库的写操作,但是能避免当没有足够健康的从库时,主库无法正常写入,以此来避免数据的丢失 ,如果设置为 0 则表示关闭该功能。
min-slaves-max-lag
是指从库和主库进行数据复制时的 ACK 消息延迟的最大时间;超出则拒绝写入。
这两个配置项组合后的要求是,主库连接的从库中至少有 N 个从库,和主库进行数据复制时的 ACK 消息延迟不能超过 T 秒,否则,主库就不会再接收客户端的请求了。
这样一来,即使原主库是假故障,它在假故障期间也无法响应哨兵发出的心跳测试,也不能和从库进行同步,自然也就无法和从库进行 ACK 确认了。原主库就会被限制接收客户端请求,客户端也就不能在原主库中写入新数据,就可以避免脑裂现象的发生了。

恢复
删除redis pod,重新同步。