longhorn支持备份存储在NFS或者与S3兼容的服务器中,比如AWS S3,minio或者oss等。这里介绍minio方式。
部署minio
集群A,部署minio,我这里用的velero中的minio。

部署后的nodePort地址有问题,容器d端口用的9000,需要修改为console的端口41972。


longhorn对接minio
打开longhorn-ui,选择setting-general-Backup Target
s3://rancherbackups@dummyregion/longhorn
minio-secret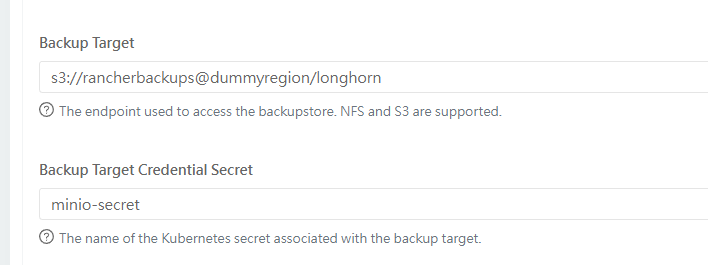
添加secret
echo -n minio | base64
echo -n minio123 | base64
# 地址可以查看minio pod日志
echo -n http://10.42.6.10:9000 | base64
cat minio-secret.yaml
apiVersion: v1
kind: Secret
metadata:
name: minio-secret
namespace: longhorn-system
type: Opaque
data:
AWS_ACCESS_KEY_ID: bWluaW8=
AWS_SECRET_ACCESS_KEY: bWluaW8xMjM=
AWS_ENDPOINTS: aHR0cDovLzEwLjQyLjYuMTA6OTAwMA==
注意
target因为是本地的,没有region,所以需要设置一个空的region。
secret需要提前创建,AWS_ENDPOINTS的地址需要设置为API的地址,不是console地址。不然会报错:S3 API Requests must be made to API port。
创建备份
部署mysql服务,rancher上启动应用商店,搜索mysql,存储选择longhorn。


在longhorn上创建备份
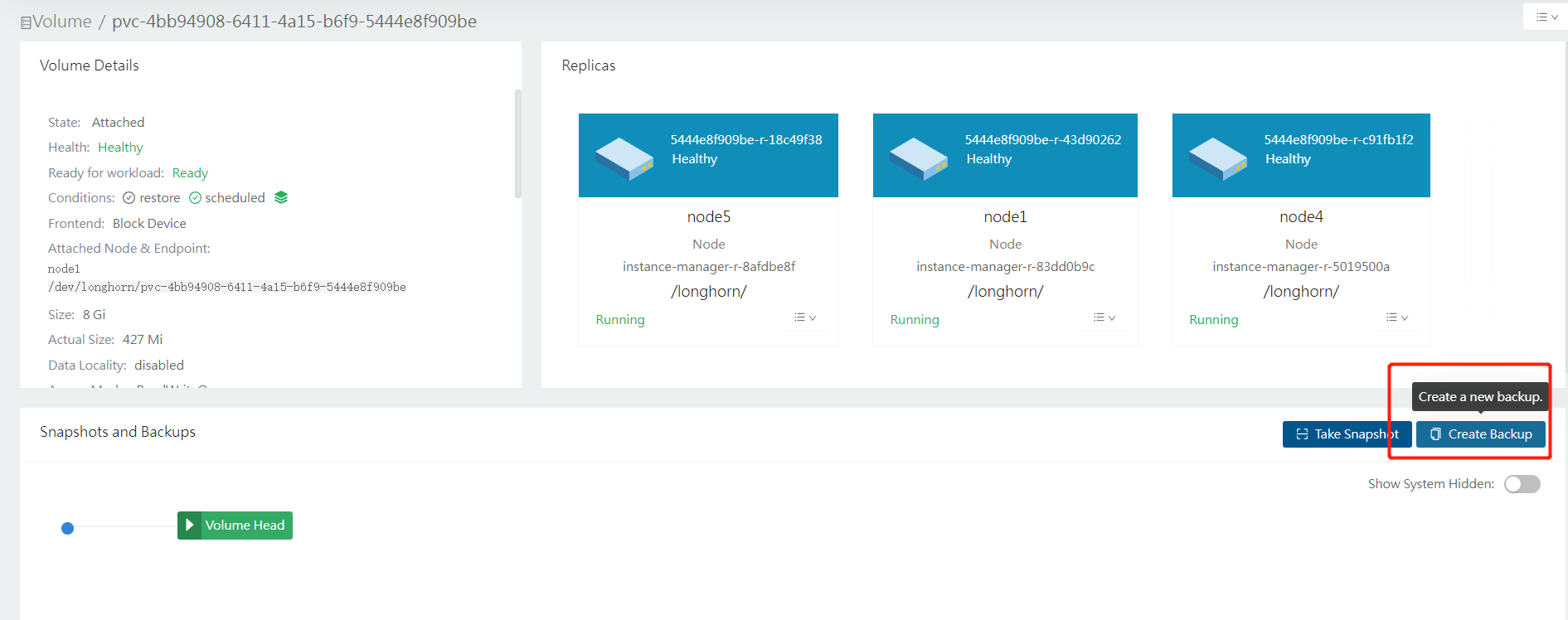
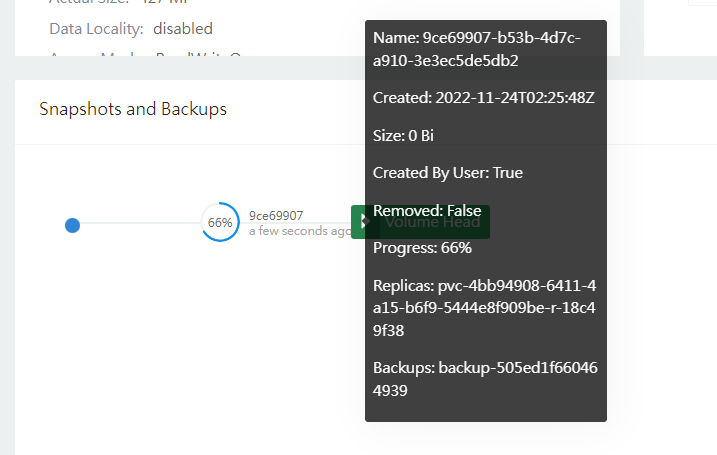
查看备份

查看label

获取url

查看minio中的bucket内容

备份同步
在集群B中指定同样的target,secret
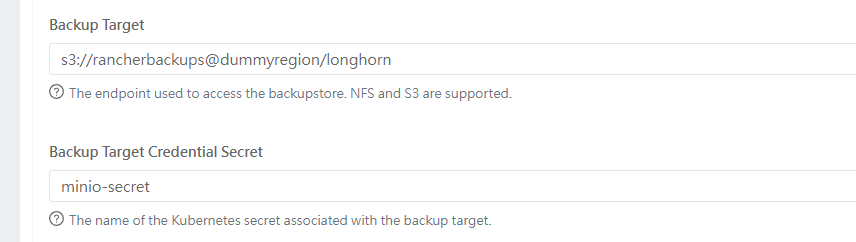
创建minio-api svc
在集群A中
apiVersion: v1
kind: Service
metadata:
labels:
component: minio
name: minio-api
namespace: velero
spec:
externalTrafficPolicy: Cluster
ports:
- nodePort: 30910
port: 9000
protocol: TCP
targetPort: 9000
selector:
component: minio
sessionAffinity: None
type: NodePort获取minio-api地址
echo -n http://172.16.255.201:30910 | base64
aHR0cDovLzE3Mi4xNi4yNTUuMjAxOjMwOTEw创建secret
在集群B中
cat minio-secret.yaml
apiVersion: v1
kind: Secret
metadata:
name: minio-secret
namespace: longhorn-system
type: Opaque
data:
AWS_ACCESS_KEY_ID: bWluaW8=
AWS_SECRET_ACCESS_KEY: bWluaW8xMjM=
AWS_ENDPOINTS: aHR0cDovLzE3Mi4xNi4yNTUuMjAxOjMwOTEw返回longhorn,点击backup,查看备份已经同步。

经测试,创建一个276M的备份,同步大约需要3分钟。

删除备份

等待自动同步,查看集群B中备份也已经删除。
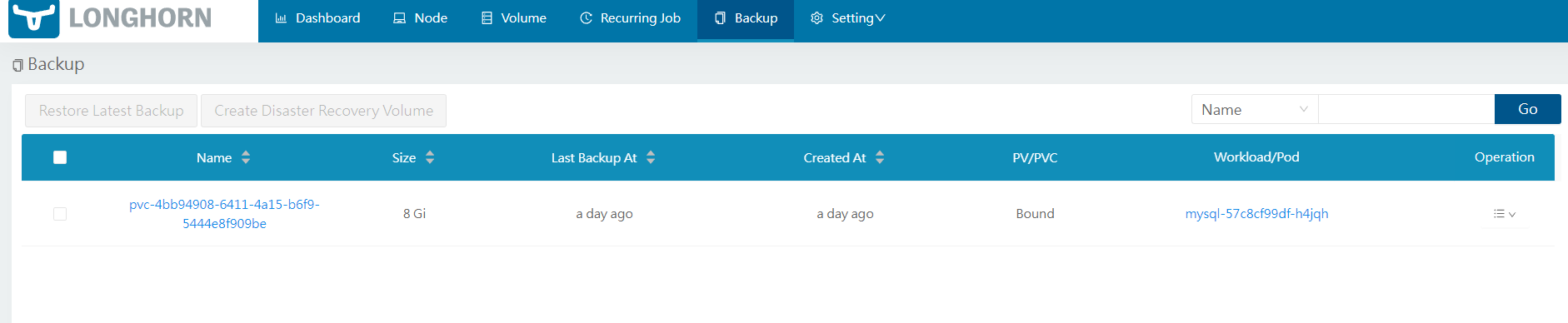
创建容灾恢复卷
容灾恢复 (DR) 卷是一种特殊卷,主要用于在整个主集群出现故障时将数据存储在备份集群中。灾难恢复卷用于提高Longhorn卷的弹性。对于灾难恢复卷,Last Backup表示其原始备份卷的最新备份。
在集群B的longhorn页面这种,使用集群A的Volume备份,在集群B中创建一个容灾恢复卷。

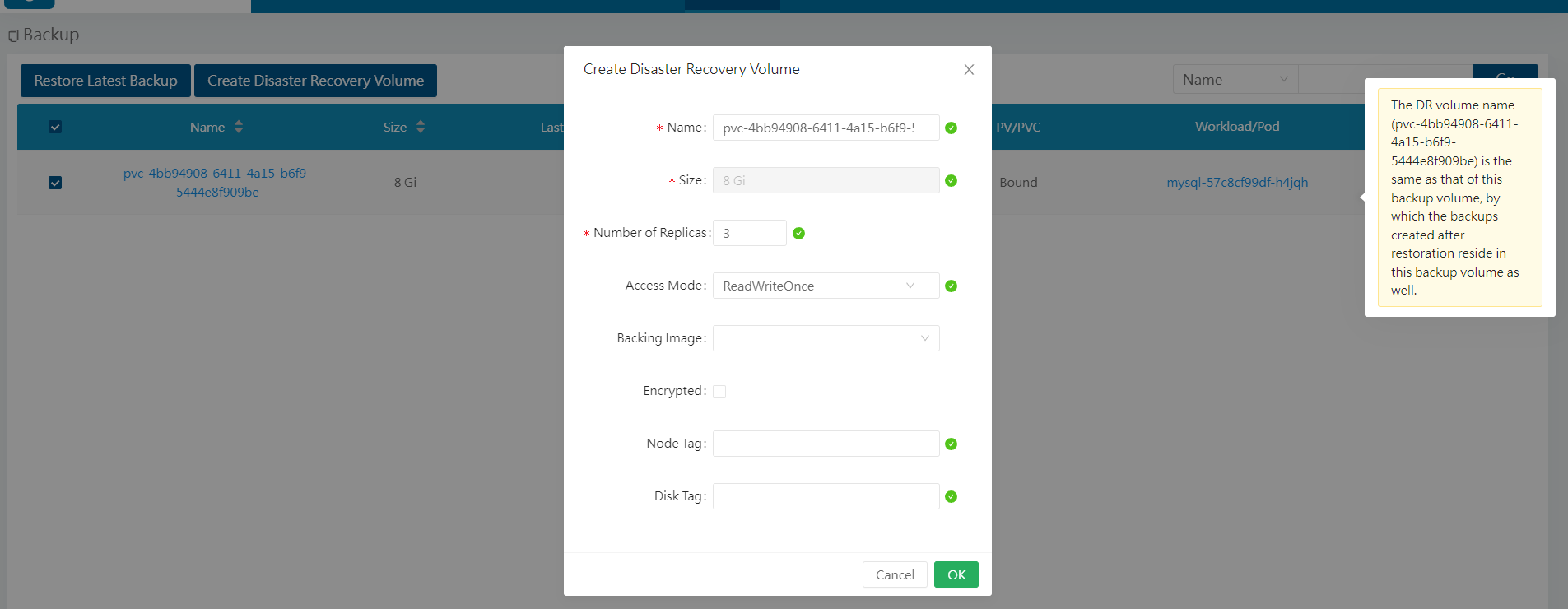
点击OK,再点击volume页面,查看容灾恢复卷。

在集群A的mysql中插入数据
mysql -u root -p
create database test;
use test;
CREATE TABLE Persons
-> (
-> Id_P int,
-> LastName varchar(255),
-> FirstName varchar(255),
-> Address varchar(255),
-> City varchar(255)
-> );
show tables;
INSERT INTO Persons VALUES ('1', 'qq', 'aa', 'hz', 'zj');
INSERT INTO Persons VALUES ('2', 'ww', 'ss', 'hz', 'zj');
INSERT INTO Persons VALUES ('3', 'ee', 'dd', 'hz', 'zj');
select * from Persons;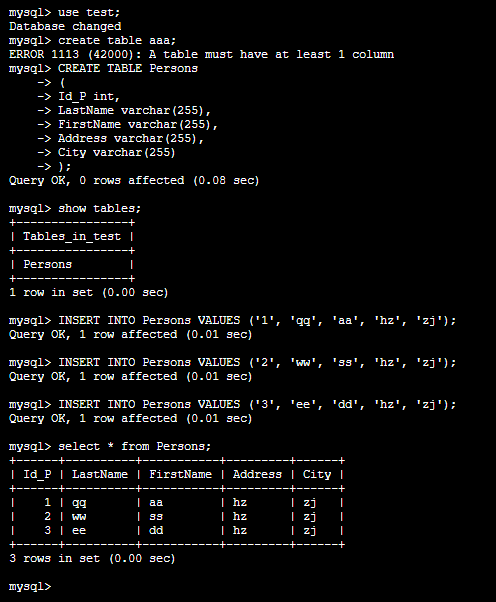
访问集群A的longhorn页面,对这个卷再次进行备份。

如果之前的备份加了label,后面的备份也需要加上对应的label,否则无法正常备份。

过一会可以看到集群B中的容灾恢复卷图标变成了灰色,代表这个卷正在同步集群A中volume的最新备份数据Last Backup,此时无法激活和使用容灾恢复卷。

同步完成后,图标变成蓝色。


Recurring Jobs
使用longhorn ui设置Recurring Jobs
如果在集群A中对Volume设置了定时任务自动备份,集群B中的longhorn会定时轮询最新的备份,将增量数据信息自动同步到容灾恢复卷,以保持与集群A中Volume数据一致。
使用StorageClass设置Recurring Jobs
使用StorageClass创建的任何卷都将自动设置这些recurring jobs。
allowVolumeExpansion: true
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
annotations:
longhorn.io/last-applied-configmap: |
......
parameters:
numberOfReplicas: "3"
staleReplicaTimeout: "30"
fromBackup: ""
fsType: "ext4"
dataLocality: "disabled"
recurringJobs: '[
{
"name":"snap",
"task":"snapshot",
"cron":"*/1 * * * *",
"retain":1
},
{
"name":"backup",
"task":"backup",
"cron":"*/2 * * * *",
"retain":1
}
]'
name: longhorn需要设置的字段:
- name:job的名称。不要在一个recurring Jobs中使用重复的名称。并且name的长度不能超过8个字符。
- task:job的类型。它仅支持snapshot(定期创建快照)或backup(定期创建快照然后进行备份)。
- cron:Cron表达式。job的执行时间。
- retain:Longhorn将为job保留多少快照/备份(snapshots/backups)。应该不少于 1。
分离卷时允许Recurring Job

启用这个选项,即使卷已分离,也可以进行周期性备份(recurring backup)。
在卷自动附加(attached automatically)期间,卷状态不是ready,Workload无法使用该卷。Workload必须等到recurring job完成才可以使用。
注意
为了避免当卷长时间没有新数据时,recurring jobs可能会用相同的备份和空快照覆盖旧的备份/快照的问题,Longhorn执行以下操作:
- Recurring backup job仅在自上次备份以来卷有新数据时才进行新备份。
- Recurring snapshot job仅在卷头(volume head)中有新数据(实时数据)时才拍摄新快照。
在集群B中恢复mysql应用
集群B中没有mysql namespace,先创建ns。
激活灾难恢复卷
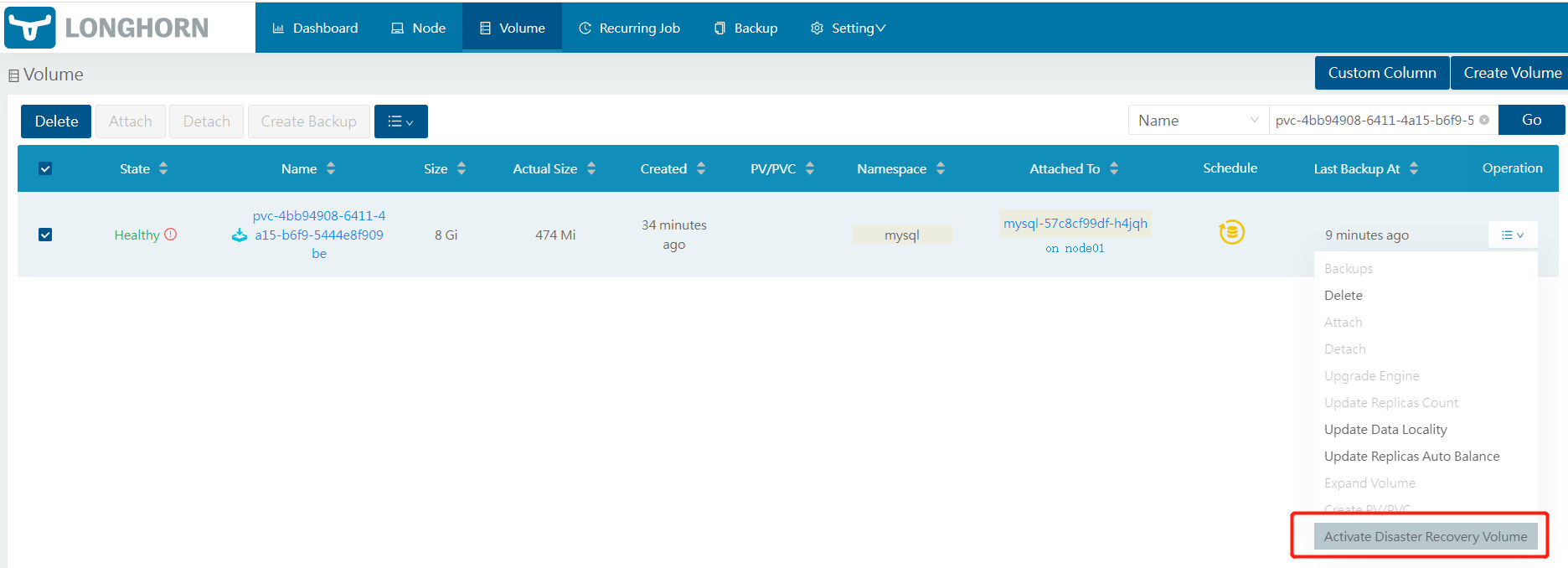
可以选择块设备或者iscsi格式,点击OK。

等待volume变成Detached状态后,创建PVC。

不建议修改PV和PVC的名称,点击OK创建。
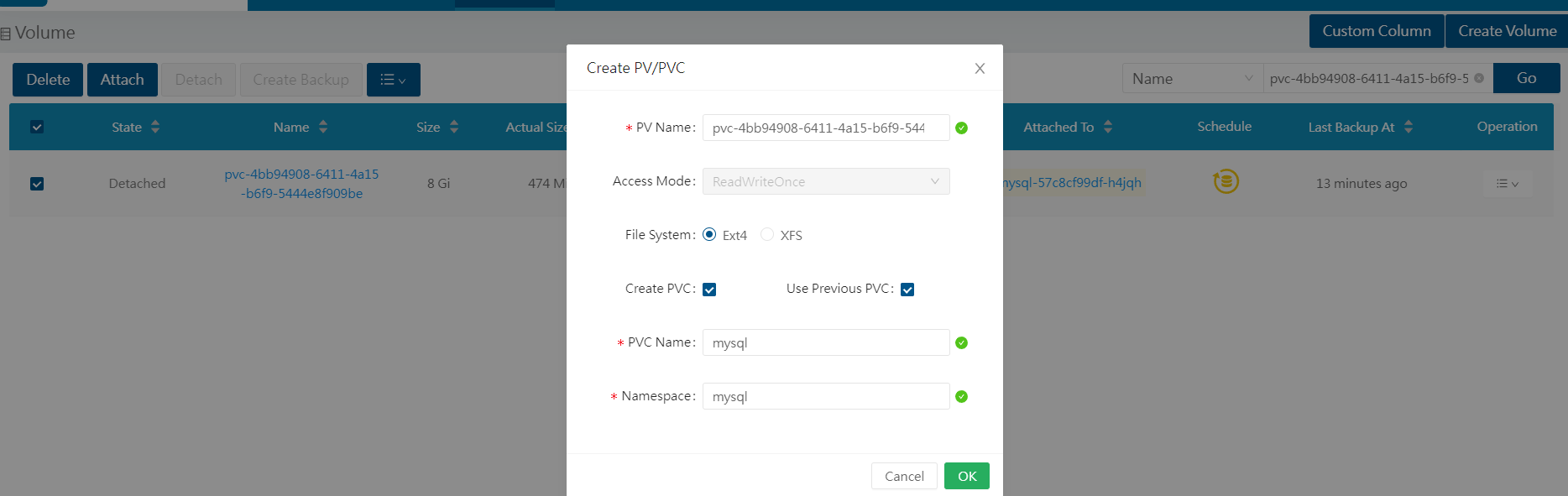
返回rancher,查看PVC已经创建。

使用恢复的PVC创建mysql应用
导入A集群的mysql-secret,svc,deployment到集群B中。查看B集群中的mysql应用。

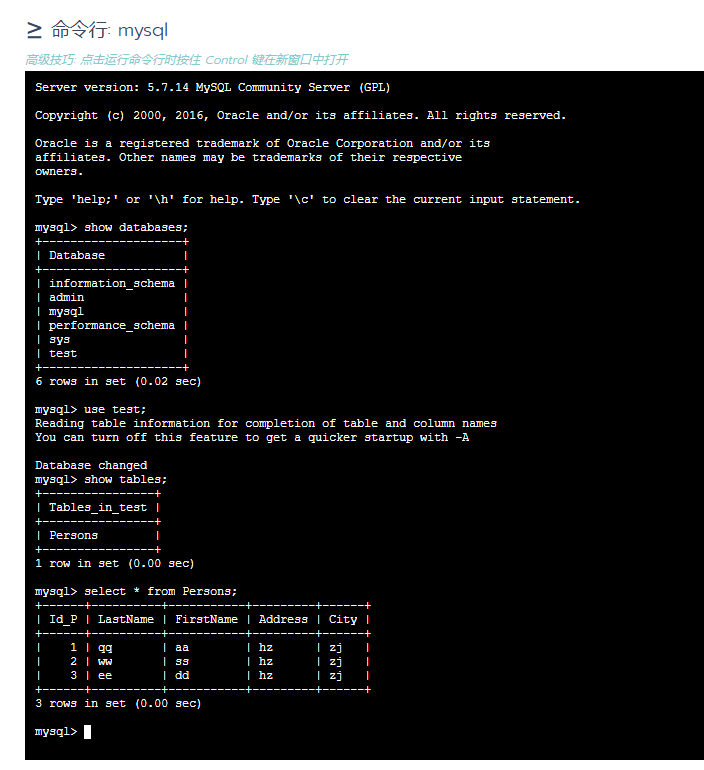
进入容器,查询数据。A集群中插入的数据已经自动同步到了B集群中。

longhorn使用oss备份
对于oss,需要启用virtual-hosted-style方式访问。
启用方法
将值为true的新字段 VIRTUAL_HOSTED_STYLE 添加到secret中,例如:
apiVersion: v1
kind: Secret
metadata:
name: oss-secret
namespace: longhorn-system
type: Opaque
data:
AWS_ACCESS_KEY_ID: aaaaaa
AWS_SECRET_ACCESS_KEY: bbbbbb
AWS_ENDPOINTS: cccccc
VIRTUAL_HOSTED_STYLE: dHJ1ZQ== # true- AWS_ACCESS_KEY_ID:oss用户名
- AWS_SECRET_ACCESS_KEY:oss密码
- AWS_ENDPOINTS:oss地址