在Karmada中,对集群的心跳探测有两种方式:
- 集群状态收集,更新集群的.status字段(包括Push和Pull两种模式);
- karmada控制面中karmada-cluster命名空间内的Lease对象,每个Pull模式集群都有一个关联的Lease对象。
集群状态收集
对于Push模式集群,Karmada控制面中的clusterStatus控制器将定期执行执行集群状态的收集任务; 对于Pull模式集群,集群中部署的 karmada-agent组件负责创建并定期更新集群的.status字段。
上述集群状态的定期更新任务可以通过–cluster-status-update-frequency标签进行配置(默认值为10秒)。
集群的Ready条件在满足以下条件时将会被设置为False:
- 集群持续一段时间无法访问;
- 集群健康检查响应持续一段时间不正常。
上述持续时间间隔可以通过–cluster-failure-threshold标签进行配置(默认值为30秒)。
集群租约对象更新
每当有集群加入时,Karmada将为每个Pull模式集群创建一个租约对象和一个租赁控制器。
ka get lease -A
每个租约控制器负责更新对应的租约对象,续租时间可以通过–cluster-lease-duration和–cluster-lease-renew-interval-fraction标签进行配置(默认值为10秒)。
由于集群的状态更新由clusterStatus控制器负责维护,因此租约对象的更新过程与集群状态的更新过程相互独立。
Karmada控制面中的cluster控制器将每隔–cluster-monitor-period时间(默认值为5秒)会检查Pull模式集群的状态,当cluster控制器在最后一个–cluster-monitor-grace-period时间段(默认值为40秒)内没有收到来着集群的消息时,集群的Ready条件将被更改为Unknown。

检查集群状态
你可以使用kubectl来检查集群的状态细节:
ka describe cluster member1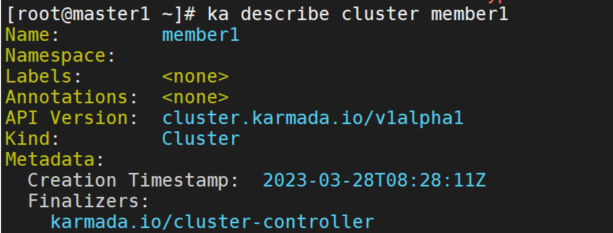
迁移过程
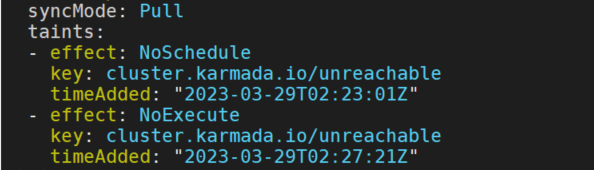
当集群被判定为不健康和集群Ready状态为Unknown时,集群将会被添加上Effect值为NoSchedule的污点。
如果集群的不健康状态持续一段时间(该时间可以通过–failover-eviction-timeout标签进行配置,默认值为5分钟)仍未恢复,集群将会被添加上Effect值为NoExecute的污点。
当用户创建PropagationPolicy/ClusterPropagationPolicy资源后,Karmada会通过webhook为它们自动增加如下集群污点容忍:
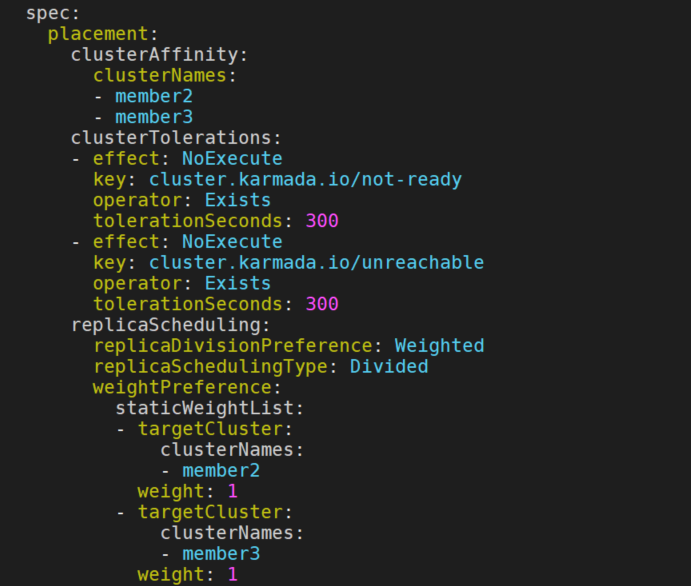
其中,容忍的tolerationSeconds值可以通过–default-not-ready-toleration-seconds与default-unreachable-toleration-seconds标签进行配置,这两个标签的默认值均为300。
故障迁移
当Karmada检测到故障群集不再被PropagationPolicy/ClusterPropagationPolicy分发策略容忍时,该集群将被从资源调度结果中删除,随后,Karmada调度器将重新调度相关工作负载。
重调度的过程有以下几个限制:
- 对于每个重调度的工作负载,其仍然需要满足PropagationPolicy/ClusterPropagationPolicy的约束,如ClusterAffinity或SpreadConstraints。
- 应用初始调度结果中健康的集群在重调度过程中仍将被保留。
Divided
对于Divided(切分)调度类型,Karmada调度器将尝试将应用副本迁移到其他健康的集群中去。
Duplicated
对于Duplicated(复制)调度类型,当满足分发策略限制的候选集群数量不小于故障集群数量时,将根据故障集群数量将工作负载重新调度到候选集群;否则,不进行重调度。
apiVersion: policy.karmada.io/v1alpha1
kind: PropagationPolicy
metadata:
name: nginx-propagation
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
name: nginx
placement:
clusterAffinity:
clusterNames:
- member1
- member2
- member3
- member5
spreadConstraints:
- maxGroups: 2
minGroups: 2
replicaScheduling:
replicaSchedulingType: Duplicated假设有5个成员集群,初始调度结果在member1和member2集群中。当member2集群发生故障,将触发调度器重调度。
需要注意的是,重调度不会删除原本状态为Ready的集群member1上的工作负载。在其余3个集群中,只有member3和member5匹配clusterAffinity策略。
由于传播约束的限制,最后应用调度的结果将会是[member1, member3]或[member1, member5]。
优雅故障迁移
为了防止集群故障迁移过程中服务发生中断,Karmada需要确保故障集群中应用副本的删除动作延迟到应用副本在新集群上可用之后才执行。
ResourceBinding/ClusterResourceBinding中增加了GracefulEvictionTasks字段来表示优雅驱逐任务队列。
当故障集群被taint-manager从资源调度结果中删除时,它将被添加到优雅驱逐任务队列中。
gracefulEvction控制器负责处理优雅驱逐任务队列中的任务。在处理过程中,gracefulEvction控制器逐个评估优雅驱逐任务队列中的任务是否可以从队列中移除。判断条件如下:
- 检查当前资源调度结果中资源的健康状态。如果资源健康状态为健康,则满足条件。
- 检查当前任务的等待时长是否超过超时时间,超时时间可以通过graceful-evction-timeout标志配置(默认为10分钟)。如果超过,则满足条件。
ka get ResourceBinding nginx-deployment -o yaml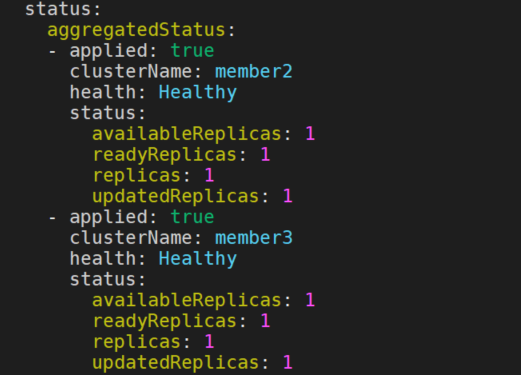
测试
pull模式
添加iptables

nginx部署请参考上篇文章中的nginx测试,现在nginx是在master2和master3上。在master3上添加iptables,阻止来自IP地址172.16.255.182的流量。
iptables -A INPUT -s 172.16.255.182 -j DROP
查看karmada-controller-manager日志
k logs karmada-controller-manager-6b455fd754-m44fz -f --tail=20 -n karmada-system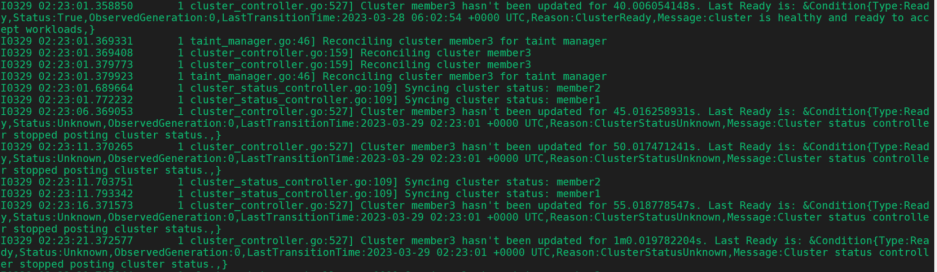
查看集群状态

查看member3集群
ka describe clusters member3
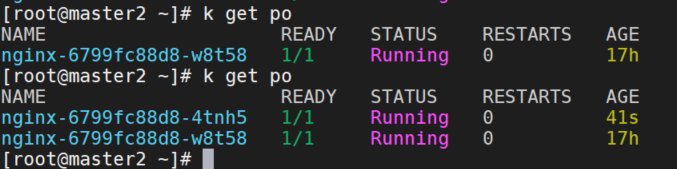
查看nginx服务

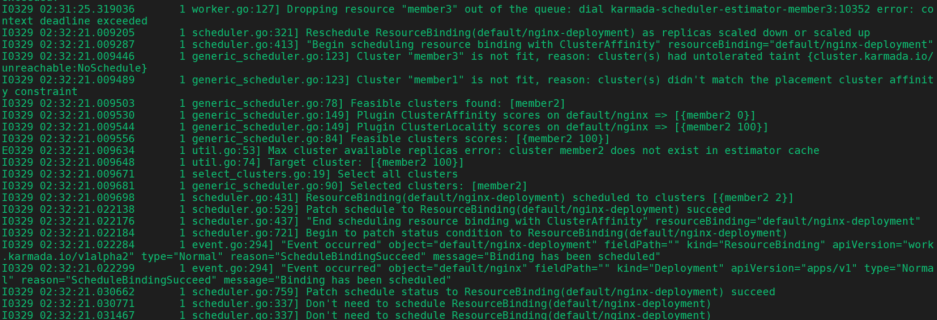
查看karmada-scheduler调度日志
- member3集群状态改变,重新调度ResourceBinding,nginx-deployment

- 把member3移除队列,scaled down or scaled up nignx-deployment。
- member3有禁止调度污点不满足条件,member1不满足集群亲和性,member2满足条件。
- 给member2集群打分
- 调度ResourceBinding到member2上
- ResourceBinding调度完成,不再需要调度了。

删除防火墙规则
iptables -L --line-numbers | more
iptables -D INPUT 3
查看控制器日志
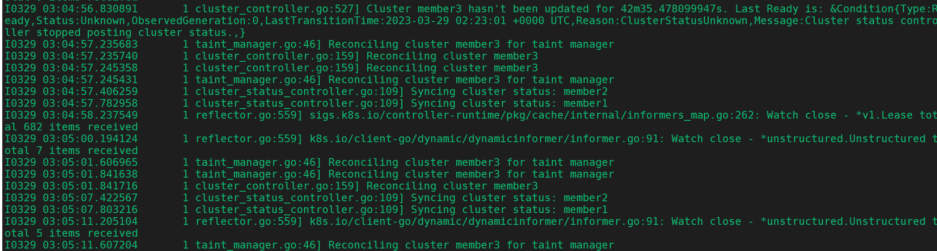
查看调度日志

查看服务


push模式
member2关机
member2不通,设置taint,心跳检查失败。
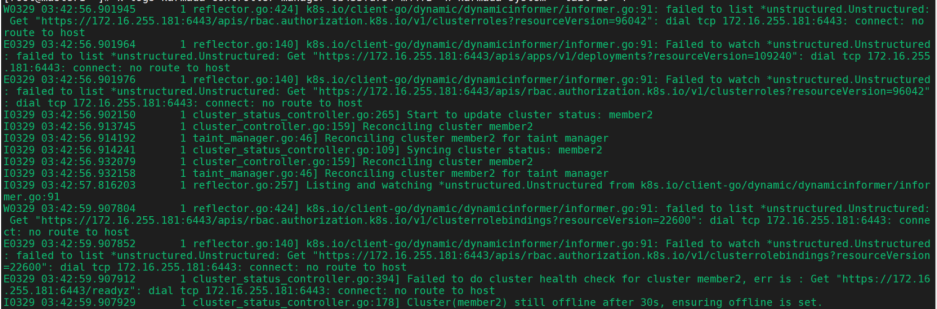
member2状态变为False

重新调度rb,给member3打分,调度rb到member3上,调度完成。

member3上pod已启动

member2开机
pod不会自动删除
