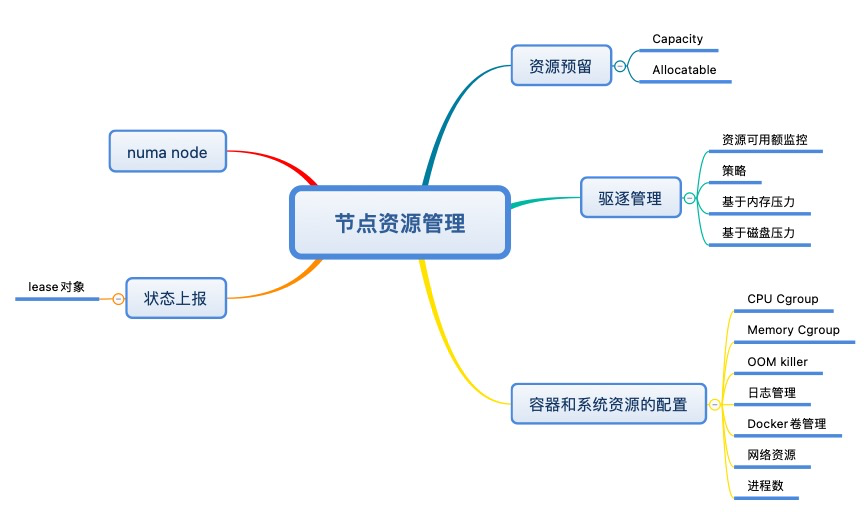
背景
下面我将以这个思维导图来总结一下k8s中节点的资源管理。
Numa Node
Non-Uniform Memory Access是一种内存访问方式,是为多核计算机设计的内存架构。
以下图为例,服务器有多个CPU和内存插槽,Numa Node1和左边的memory是通过FSB(Front Service Bus)直连的。访问是local access,效率会很高。
如果Numa Node1要访问右边的memory,是没有直连的,需要通过QPI(Quick Path Interconnect)的总线再通过FSB来访问,是remote access,效率很低。

解决
CPU Manager + Topology Manager可以实现让CPU尽量去访问本地的memory。在性能优化时会用到。
参考链接
状态上报
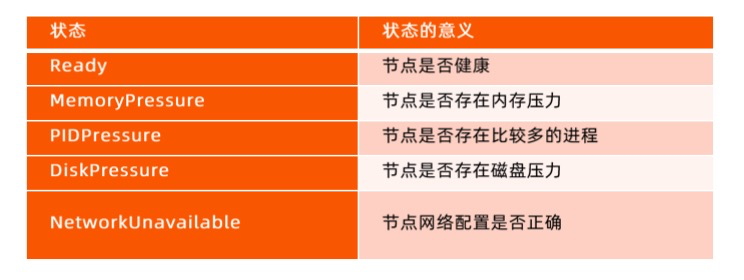
kubelet 周期性地向API Server进行汇报,并更新节点的相关健康和资源使用信息。
- 节点基础信息,包括IP地址、操作系统、内核、运行时、kubelet、kube-proxy版本信息。
- 节点资源信息包括 CPU、内存、HugePage、临时存储、GPU 等注册设备,以及这些资源中可以分配给容器使用的部分。
- 调度器在为 Pod 选择节点时会将机器的状态信息作为依据。
Lease对象
在早期版本kubelet的状态上报直接更新node对象,而上报的信息包含状态信息和资源信息,因此需要传输的数据包较大,给APIServer和etcd造成的压力较大。
Lease对象用来保存健康信息,在默认40s的nodeLeaseDurationSeconds 周期内,若Lease对象没有被更新,则对应节点可以被判定为不健康。
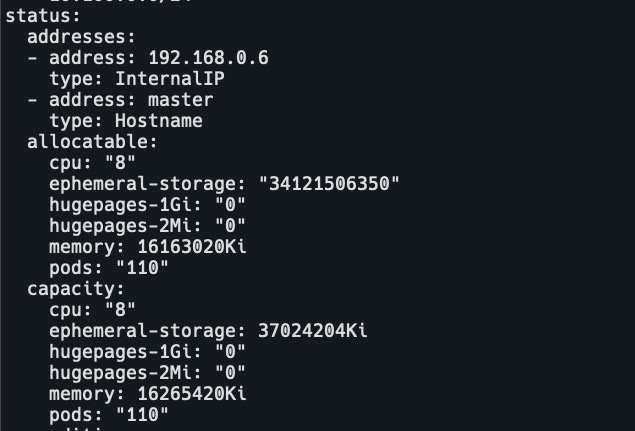
资源信息查看
k get node master -o yamlyaml文件中status字段为上报的节点资源信息。
健康状态信息查看
k get ns | grep kube-node-lease
k get lease -n kube-node-lease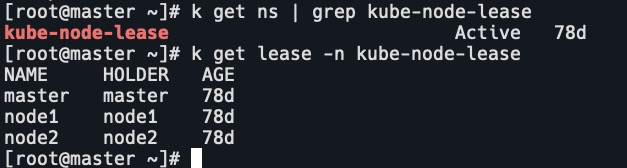
k get lease master -n kube-node-lease -o yaml在有多个controller manager时,需要开启leader election模式来争抢锁,抢到锁后需要renew。lease对象就可以很好的支持这种模式。
- holderIdentity:lease对象的持有者。
- leaseDurationSeconds:租约40s。
- renewTime:续约时间。kubelet会一直更新这个时间来续约。

资源预留
- 计算节点除用户容器外,还存在很多支撑系统运行的基础服务,譬如 systemd、 journald、 sshd、dockerd、 containerd、 kubelet 等。
- 为了使服务能够正常运行,要确保它们在任何时候都可以获取足够的系统资源,所以我们要为这些系统进程预留资源。
- kubelet 可以通过众多启动参数为系统预留 CPU、内存、PID 等资源,比如 Syste mReserved、KubeReserved 等。
Capacity 和 Allocatable
容量资源(Capacity)是指 kubelet 获取的计算节点当前的资源信息。

- CPU 是从 /proc/cpuinfo 文件中获取的节点 CPU 核数;

- memory 是从 /proc/memoryinfo 中获取的节点内存大小;
- ephemeral-storage 是指节点根分区的大小。

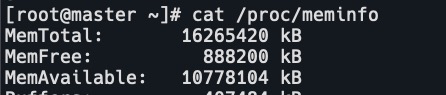

资源可分配额(Allocatable)是用户 Pod 可用的资源,是资源容量减去分配给系统的资源的剩余部分。
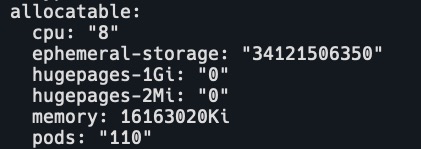
Capacity包括k8s,系统使用,驱逐阈值和Allocatable。

节点磁盘管理
- 系统分区 nodefs:工作目录和容器日志。
# containerd & docker cd /var/lib/kubelet/pods - 容器运行时分区 imagefs
- overlayfs在加载镜像时,用户镜像和容器可写层。
- 容器运行时分区是可选的,可以合并到系统分区中。
# containerd
cd /var/lib/kubelet/pods
# docker
cd /var/lib/docker/overlay2/
驱逐管理
kubelet 会在不可压缩资源如内存或者磁盘不够时会中止一些容器进程,以空出系统资源,保证节点的稳定性。
但由 kubelet 发起的驱逐只停止 Pod 的所有容器进程,并不会直接删除 Pod。
- Pod的status.phase 会被标记为 Failed。
- status.reason 会被设置为 Evicted。
- status.message 则会记录被驱逐的原因。
节点可用额监控
- kubelet 依赖内嵌的开源软件 cAdvisor,周期性检查节点资源使用情况。
- CPU 是可压缩资源,根据不同进程分配时间配额和权重分时复用。
- 驱逐策略是基于磁盘和内存资源用量进行的,因为两者属于不可压缩的资源,当此类资源使用耗尽时将无法再申请。

驱逐策略
- kubelet 获得节点的可用额信息后,会结合节点的容量信息来判断当前节点运行的 Pod 是否满足驱逐条件。
- 驱逐条件可以是绝对值或百分比,当监控资源的可使用额少于设定的数值或百分比时,kubelet就会发起驱逐操作。
- kubelet 参数 evictionMinimumReclaim 可以设置每次回收的资源的最小值,以防止小资源的多次回收。
分类
软驱逐就是给pod一个优雅终止的机会。
当软驱逐后又达到了硬驱逐的阈值就执行硬驱逐。

修改kubelet配置文件
cat /var/lib/kubelet/config.yaml
# 添加配置
# 指定硬驱逐
evictionHard:
memory.available: '500Mi'
nodefs.available: '1Gi'
imagefs.available: '100Gi'
# 指定每次最少驱逐资源
evictionMinimumReclaim:
memory.available: '0Mi'
nodefs.available: '500Mi'
imagefs.available: '2Gi'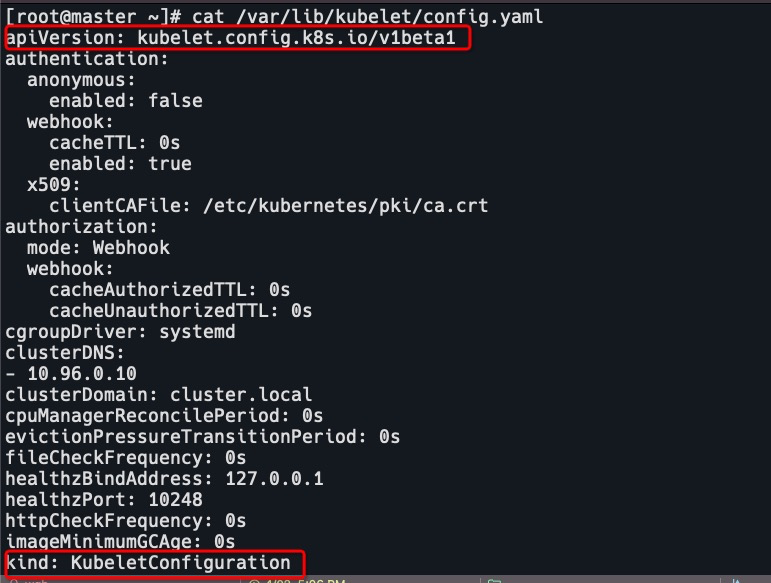
基于内存压力的驱逐
- memory.available 表示当前系统的可用内存情况。
- kubelet默认设置了 memory.avaiable小于100Mi 的硬驱逐条件。
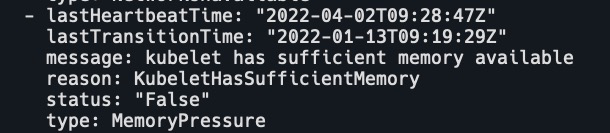
- 当 kubelet 检测到当前节点可用内存资源紧张并满足驱逐条件时,会将节点的 MemoryPressure状态设置为 True,调度器会阻止 BestEffort Pod 调度到内存承压的节点。
# 查看conditions中的MemoryPressure k get node master -o yaml
驱逐顺序
kubelet 启动对内存不足的驱逐操作时,会依照如下的顺序选取目标 Pod:
- 判断 Pod 所有容器的内存使用量总和是否超出了请求的内存量,超出请求资源的 Pod 会成为备选目标。
- 查询 Pod 的调度优先级,低优先级的 Pod 被优先驱逐。
- 计算 Pod 所有容器的内存使用量和 Pod 请求的内存量的差值,差值越小,越不容易被驱逐。
基于磁盘压力的驱逐
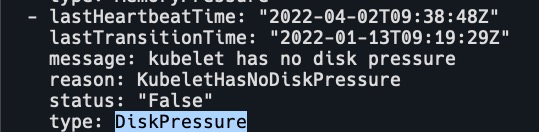
以下任何一项满足驱逐条件时,它会将节点的 DiskPressure 状态设置为 True,调度器不会再调度任何 Pod 到该节点上。
- nodefs.available
- nodefs.inodesFree
- imagefs.available
- imagefs.inodesFree
驱逐行为
- 有容器运行时分区
- nodefs 达到驱逐阈值,那么kubelet 删除已经退出的容器。
- Imagefs 达到驱逐阈值,那么 kubelet 删除所有未使用的镜像。
- 无容器运行时分区
- kubelet 同时删除未运行的容器和未使用的镜像。
驱逐顺序
回收已经退出的容器和未使用的镜像后,如果节点依然满足驱逐条件,kubelet 就会开始驱逐正在运行的 Pod,进一步释放磁盘空间。
- 判断 Pod 的磁盘使用量是否超过请求的大小,超出请求资源的 Pod 会成为备选目标。
- 查询 Pod 的调度优先级,低优先级的 Pod 优先驱逐。
- 根据磁盘使用超过请求的数量进行排序,差值越小,越不容易被驱逐。
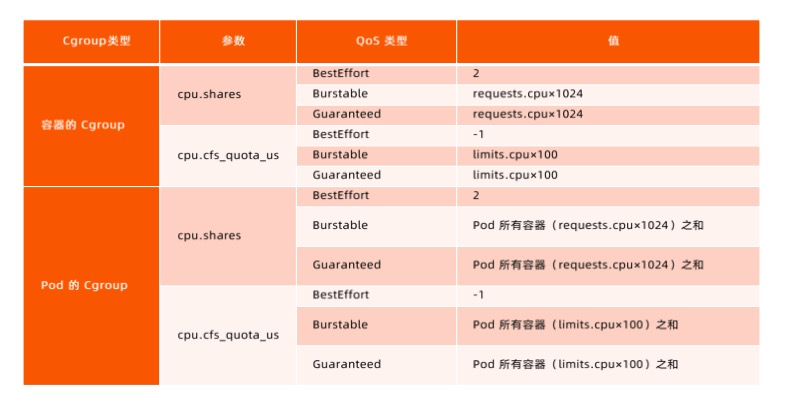
容器和资源配置
针对不同 Qos Class 的 Pod, Kubneretes 按如下 Hierarchy 组织 Cgroup 中的 Memory 子系统。
cd /sys/fs/cgroup/memory/kubepods.slice
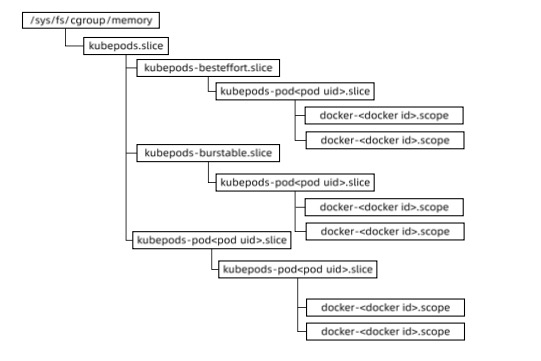
内存cgroup配置

针对不同 Qos Class 的 Pod, Kubneretes 按如下 Hierarchy 组织 Cgroup 中的 CPU 子系统。
cd /sys/fs/cgroup/cpu/kubepods.slice

CPU cgroup配置
OOM killer
- 系统的 OOM killer 根据进程的 oomscore 来进行优先级排序,选择待终止的进程,且进程的 oom score越高,越容易被终止。
- 进程的 oom_score 是根据当前进程使用的内存占节点总内存的比例值乘以10,再加上oom_score_adj 综合得到的。
- 而容器进程的 oom_score_adj 是 kubelet 根据 memory.request 进行设置的。

# 查看pod和pod的qos
k get po
# 可以看到pod是BestEffort的
k get po nginx-6cc88c7947-vh4rq -o yaml | grep -i qos
# 查看pod的id
crictl pods --namespace default
# 查看pod的容器进程
crictl ps | grep a04cabae42e13
# 查看进程的pid
crictl inspect 5ed0e8a0350fb | grep pid
# 查看进程的oom_score是1000
cat /proc/30626/oom_score
# 查看进程的oom_score_adj也是1000
cat /proc/30626/oom_score_adj
日志管理
节点上需要通过运行 logrotate 的定时任务对系统服务日志进行 rotate 清理,以防止系统服务日志占用大量的磁盘空间。
- logrotate 的执行周期不能过长,以防日志短时间内大量增长。
- 同时配置日志的 rotate 条件,在日志不占用太多空间的情况下,保证有足够的日志可供查看。
- Docker
- 除了基于系统 logrotate 管理日志,还可以依赖 Docker 自带的日志管理功能来设置容器日志的数量和每个日志文件的大小。
- Docker 写入数据之前会对日志大小进行检查和 rotate 操作,确保日志文件不会超过配置的数量和大小。
- Containerd
- 日志的管理是通过 kubelet 定期(默认为10s)执行 du命令,来检查容器日志的数量和文件的大小的。
- 每个容器日志的大小和可以保留的文件个数,可以通过 kubelet 的配置参数 container-log-max-size 和container-log-max-files 进行调整。
docker卷管理
- 在构建容器镜像时,可以在 Dockerfile 中通过 VOLUME 指令声明一个存储卷,目前Kubernetes 尚未将其纳入管控范围,不建议使用。
- 如果容器进程在可写层或 emptyDir 卷进行大量读写操作,就会导致磁盘IO过高,因为多个emptyDir共享一个nodefs,从而影响其他容器进程甚至系统进程。
- Docker 和 Containerd 运行时都基于 Cgroup v1。对于块设备,只支持对 Direct IO限速,而对于 Buffer IO还不具备有效的支持。因此,针对设备限速的问题,目前还没有完美的解决方案,对于有特殊 IO需求的容器,建议使用独立的磁盘空间。
网络管理
由网络插件通过 Linux Traffic Control 为 Pod 限制带宽。
可利用 CNI 社区提供的 bandwidth 插件。
cat /etc/cni/net.d/10-calico.conflist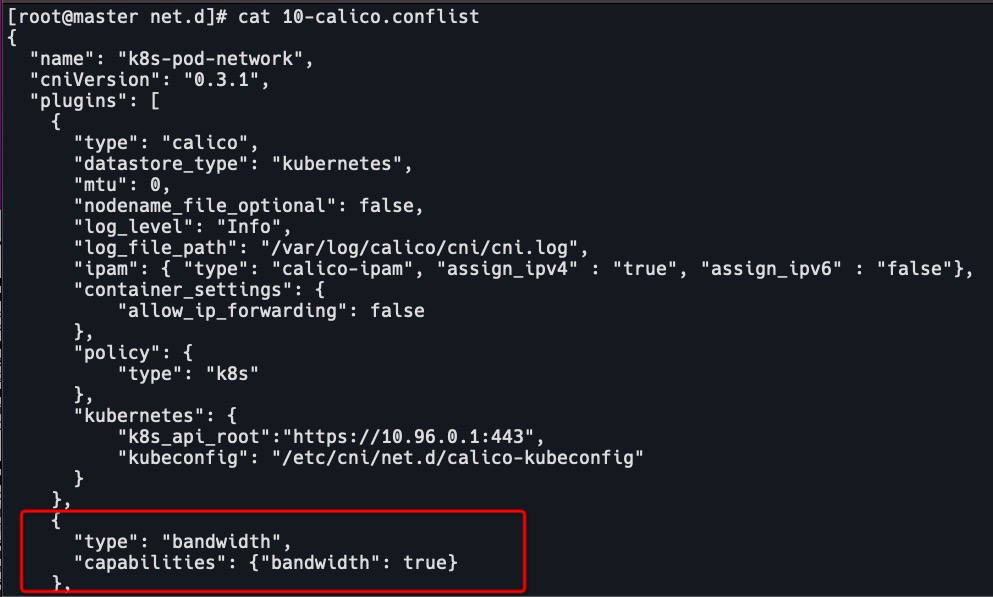
设置pod带宽限制
metadata:
annotations:
kubernetes.io/ingress-bandwidth: 10M
kubernetes.io/egress-bandwidth: 10M进程数
kubelet 默认不限制 Pod 可以创建的子进程数量,但可以通过启动参数 podPidsLimit 开启限制,还可以由 reserved 参数为系统进程预留进程数。
- kubelet 通过系统调用周期性地获取当前系统的 PID 的使用量,并读取/proc/sys/kernel/pid_max,获取系统支持的PID 上限。
- 如果当前的可用进程数少于设定闻值,那么 kubelet 会将节点对象的 PIDPressure 标记为True。
- kube-scheduler 在进行调度时,会从备选节点中对处于 NodeUnderPIDPressure 状态的节点进行过滤。
