背景
当集群需要的资源是动态的,业务有明显的波峰波谷。如果集群保持固定的大小,在集群规划时,需要按照最高规格去规划,这样当波谷时,集群的利用率就很低。而如果按照最小规格去规划,当业务越来越多时,pod可能就无法启动了。
修改deployment中的replica可以手工扩缩容,但是不知道具体什么时间业务到达波峰。那么如果根据业务来动态扩展集群资源呢,这时就可以用Cluster Autoscaler。
工作机制
- 扩容
由于资源不足,Pod 调度失败,即有 Pod一直处于 Pending 状态。

- 缩容
node 的资源利用率较低时,持续10 分钟低于 50%。
此 node 上存在的 Pod 都能被重新调度到其他 node 上运行。

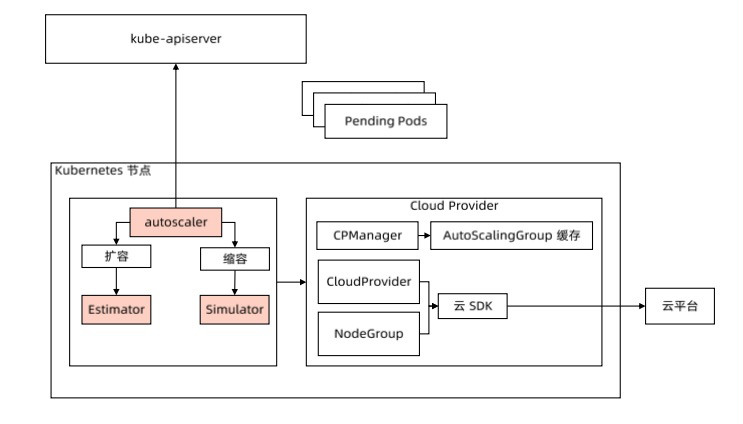
架构
- Autoscaler: 核心模块,负责整体扩缩容功能。
- Estimator:负责评估计算扩容节点。
- Simulator:负责模拟调度,计算缩容节点。
- cloud-Provider:与云交互进行节点的增删操作,每个支持 CA 的主流厂商都实现自己的 plugin实现动态缩放。
扩展机制
- 为了自动创建和初始化 Node, Cluster Autoscaler 要求 Node 必须属于某个 Node Group,比如:
- GCE/GKE 中的 Managed instance groups (MIG)
- AWS 中的 Autoscaling Groups;
- Cluster APi Node。
- 当集群中有多个 Node Group 时,可以通过–expander=coption>选项配置选择 Node Group 的策略,支持如下四种方式:
- random:随机选择。
- most-pods:选择容量最大(可以创建最多 Pod)的 Node Group。
- least-waste:以最小浪费原则选择,即选择有最少可用资源的 Node Group。
- price:选择最便宜的 Node Group。
为什么不定义一个对象,比如集群使用率到达80%就扩容集群,而是使用Cluster Autoscaler呢?
由于调度策略是有很多种的,比如一个deployment需要3个replica,正常只需要一个4c8g的节点就够用了,但是pod配置了反亲和性,要求3个replica不能在同一个节点上,这样就不能只根据一的根据集群使用率来调度pod。