背景
我们知道集群中pod的扩缩容可以用HPA,节点的扩缩容可以用
Cluster Autoscaler,缩容或者下线维持pod数量可以使用PDB,那么该如何实现集群核心组件的负载弹性呢,比如CoreDNS、Ingress Controller等。
一个集群应该部署多少个核心组件副本呢?这个问题没有统一的答案。不同类型的应用、不同的网络、不同的调度分布,环境都不是一致的。
但是大部分的情况下,核心组件的副本数目和集群的节点数目是成正比的,一个集群的节点数目越多,核心组件所需要的副本数就越多。
cluster-proportional-autoscaler
通过这个工具可以精确的实现核心组件的扩缩容。
官方地址:
https://kubernetes.io/docs/tasks/administer-cluster/dns-horizontal-autoscaling/
https://github.com/kubernetes-sigs/cluster-proportional-autoscaler
cpa只需要一个configmap和一个cpa的deployment,并在deployment中指定伸缩的监听对象以及伸缩策略即可。下面将以coredns为例进行测试。

伸缩策略
线性模型
{
"coresPerReplica": 2,
"nodesPerReplica": 1,
"min": 1,
"max": 100,
"includeUnschedulableNodes": true,
"preventSinglePointFailure": true
}coresPerReplica 的意思是按照核心数目来计算副本集,
nodesPerReplica 是按照节点数目来计算副本集,
includeUnschedulableNodes 为true表示按照节点数进行扩展,否则只在可以调度的节点上扩展(不包括cordon和drain节点)
preventSinglePointFailure 如果是单节点会确保至少2个副本
副本数量
replicas = max( ceil( cores 1/coresPerReplica ) , ceil( nodes 1/nodesPerReplica ) )
replicas = min(replicas, max)
replicas = max(replicas, min)
假如集群有2个node,每台机器都是4C8G,那么如果按照 coresPerReplica 这个指标计算,则需要 241/2=4个副本;
如果按照 nodesPerReplica 来计算,则需要 2*1/1=2个副本;
所以最后的副本数是 max(4,2)= 4。
梯度模型
{
"coresToReplicas":
[
[ 1, 1 ],
[ 64, 3 ],
[ 512, 5 ],
[ 1024, 7 ],
[ 2048, 10 ],
[ 4096, 15 ]
],
"nodesToReplicas":
[
[ 1, 1 ],
[ 2, 2 ]
]
}这个配置表示存在 coresToReplicas 和 nodesToReplicas 两个梯度,其中 coresToReplicas 的梯度表示:最小为 1 个副本;CPU 核心数目大于 3 小于 64 的时候,为 2 个副本;依次类推。
同样 nodesToReplicas 表示 1 个节点的时候为 1 个副本,2 个节点的时候为 2 个副本。
安装使用
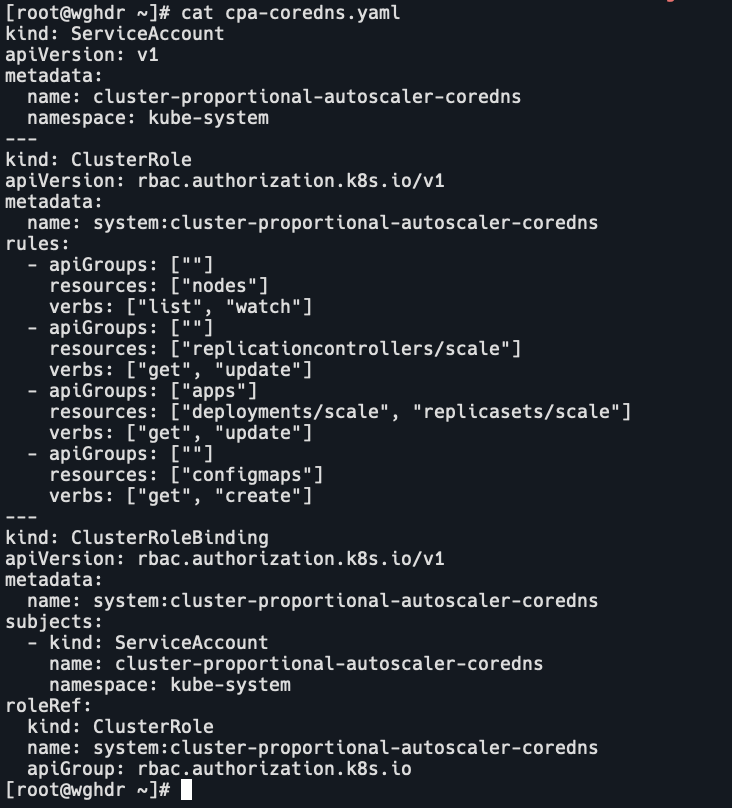
- 创建cpa-coredns.yaml,授权cpa对pod数进行修改
kind: ServiceAccount apiVersion: v1 metadata: name: cluster-proportional-autoscaler-coredns namespace: kube-system --- kind: ClusterRole apiVersion: rbac.authorization.k8s.io/v1 metadata: name: system:cluster-proportional-autoscaler-coredns rules: - apiGroups: [""] resources: ["nodes"] verbs: ["list", "watch"] - apiGroups: [""] resources: ["replicationcontrollers/scale"] verbs: ["get", "update"] - apiGroups: ["apps"] resources: ["deployments/scale", "replicasets/scale"] verbs: ["get", "update"] - apiGroups: [""] resources: ["configmaps"] verbs: ["get", "create"] --- kind: ClusterRoleBinding apiVersion: rbac.authorization.k8s.io/v1 metadata: name: system:cluster-proportional-autoscaler-coredns subjects: - kind: ServiceAccount name: cluster-proportional-autoscaler-coredns namespace: kube-system roleRef: kind: ClusterRole name: system:cluster-proportional-autoscaler-coredns apiGroup: rbac.authorization.k8s.io
- 创建cpa-deployyaml,指定pod副本数,监听coredns,伸缩策略,用户角色。
kind: ConfigMap apiVersion: v1 metadata: name: coredns-autoscaler namespace: kube-system data: linear: |- { "coresPerReplica": 2, "nodesPerReplica": 1, "min": 1, "max": 10, "preventSinglePointFailure": true } --- apiVersion: apps/v1 kind: Deployment metadata: name: coredns-autoscaler namespace: kube-system labels: app: autoscaler spec: selector: matchLabels: app: autoscaler replicas: 1 template: metadata: labels: app: autoscaler spec: containers: - image: lank8s.cn/cpa/cluster-proportional-autoscaler:1.8.4 name: autoscaler command: - /cluster-proportional-autoscaler - --namespace=kube-system - --configmap=coredns-autoscaler - --target=deployment/coredns - --logtostderr=true - --v=2 serviceAccountName: cluster-proportional-autoscaler-coredns - 部署
k create -f cpa-coredns.yaml k create -f cpa-deploy.yaml - 查看pod
- 查看日志
- 修改cm中的min为2,机器是2c4g,所以改了min。
- 也可以使用helm安装,添加repo
helm repo add cluster-proportional-autoscaler https://kubernetes-sigs.github.io/cluster-proportional-autoscaler helm repo update helm upgrade --install cluster-proportional-autoscaler \ cluster-proportional-autoscaler/cluster-proportional-autoscaler --values coredns-cpa.yaml






hpa和cpa的区别
-
hpa:是Kubernetes的顶级API资源。它监控pods中容器的CPU或内存使用率,并自动对副本数进行扩缩容。
-
cpa:是一个DIY容器,它不是Kubernetes API资源。它也不需要监控CPU或者内存使用率,它只需要监控集群中的节点数和CPU核心数,并根据configmap来定义副本数。