背景
集群中如果dns的性能不足,可能会影响应用的访问。关于CoreDNS的介绍请看这里。下面介绍几种优化手段。
1.调整CoreDNS的副本数
- CoreDNS作为集群中的核心组件,可以根据集群规模大致推算出副本数,比如修改为5个副本:
kubectl scale deployment/coredns --replicas=5 -n kube-system - 使用cluster-proportional-autoscaler根据集群规模和CPU核心数来实现更精确的扩缩容。
2.禁用 ipv6
- 容器内发起dns请求时是同时发起ipv4和ipv6的请求的。
- 如果不需要ipv6的解析,当容器请求某个域名时,coredns解析不到ipv6记录,就会转发到上游去解析。
- 如果到上游需要经过较长时间(比如跨公网,跨机房专线),就会拖慢整个解析流程的速度,业务层面就会感知到dns解析慢。
使用template插件,可以用它来禁用 IPV6 的解析,添加如下配置,即给所有ipv6的解析请求都响应空记录。
插件的官网地址:https://coredns.io/plugins/template/#description
. {
template ANY ANY {
rcode NXDOMAIN
}
}3.优化 ndots

比如要解析 kubernetes.test.svc.cluster.local 这个 service,
- 查询 kubernetes.test.svc.cluster.local.default.svc.cluster.local,查不到。
- 查询 kubernetes.test.svc.cluster.local.svc.cluster.local,查不到。
- 查询 kubernetes.test.svc.cluster.local.cluster.local,查不到。
- 查询 kubernetes.test.svc.cluster.local.openstacklocal,查不到。
- 不加后缀,查询 kubernetes.test.svc.cluster.local,查到了。
通过这个栗子可以看到请求一个普通的域名,都需要经过5次解析,集群中充斥着大量无用的 DNS 请求。
自定义dns policy
那么该怎么优化呢?参考这里的自定义dns policy章节,再让业务发起请求时尽量带上完整的域名,这样就不会有过多无效请求。
使用autopath插件
autopath插件可以避免每次域名解析经过多次请求才能解析到,原理是CoreDNS智能识别拼接过search的DNS解析,直接响应CNAME并附上相应的ClusterIP。
插件的官网地址:https://coredns.io/plugins/autopath/
修改coredns的configmap:
ks edit cm coredns这是原有的cm配置:
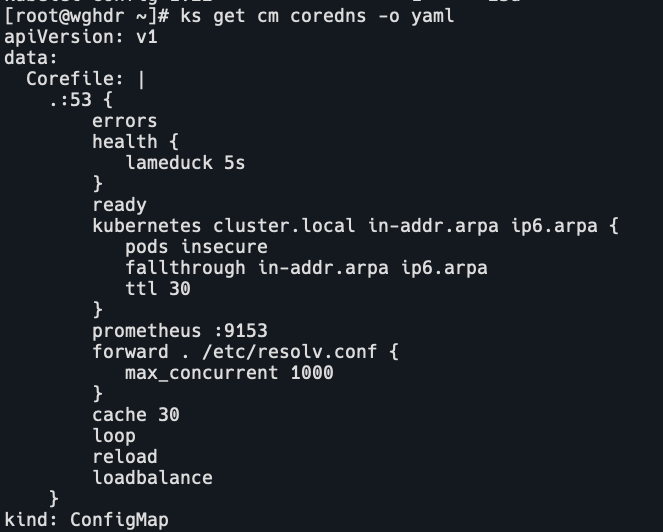
这是修改后的cm配置:
kubernetes cluster.local in-addr.arpa ip6.arpa {
# insecure改为verified
pods verified
fallthrough in-addr.arpa ip6.arpa
ttl 30
}
# 新增
autopath @kubernetes
prometheus :9153coredns会watch所有的pod,启用autopath后,会增加coredns 的内存消耗,所以需要根据情况适当调节coredns的memory request和limit。
3.NodeLocal DNSCache
通过在集群节点上启动一个DaemonSet运行DNS缓存代理来提高集群DNS性能。
参考链接:https://kubernetes.io/zh-cn/docs/tasks/administer-cluster/nodelocaldns/