报错详情
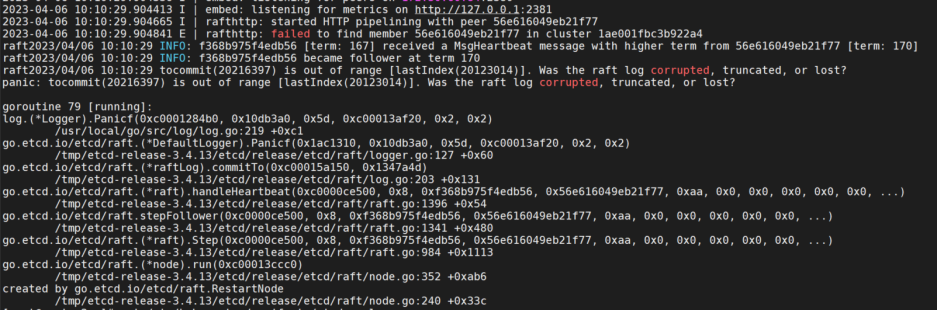
报错原因是添加了etcd启动参数:
- --heartbeat-interval=500 # 心跳检查间隔 默认100ms
- --election-timeout=5000 # 选举超时,默认1000ms
- --max-request-bytes=33554432 # etcd Raft消息最大字节数,ETCD默认该值为1.5M;如果业务数据很大,超过了1.5M,那么会导致无法写入元数据。这里是32M。
- --quota-backend-bytes=8589934592 # ETCD db数据大小,当数据达到2G的时候就不允许写入,这里是8G。
- --auto-compaction-retention=1 # 代表1小时压缩一次。默认的历史数据是不会清理的,数据达到2G就不能写入,必须要清理压缩历史数据才能继续写入;
- --auto-compaction-mode=periodic # 压缩历史数据
# 自动压缩碎片后还需要单独再清理占用的系统存储空间,etcdctl defrag。推荐通过 cronjob 定期执行 etcdctl defrag(如果 defrag 执行时间 > election timeout,则集群会进入重新选主模式)添加后etcd无法启动,报错如上图所示。
查看etcd集群状态。

解决
需要把这个异常etcd节点从集群中删除,再添加。
mv /etc/kubernetes/manifests/etcd.yaml /root
etcdctl member list
etcdctl member remove xxx
etcdctl member add master1 --endpoints=https://172.50.60.21:2379 --peer-urls=https://172.50.60.21:2380
cp -r /var/lib/etcd/member /root/member-bak
rm -rf /var/lib/etcd/member
vim /root/etcd.yaml
- --initial-advertise-peer-urls=https://172.50.60.21:2380
# 添加所有节点
- --initial-cluster=master1=https://172.50.60.21:2380,master3=https://172.50.60.84:2380,master2=https://172.50.60.72:2380
- --initial-cluster-state=existing
mv /root/etcd.yaml /etc/kubernetes/manifests删除节点,重新添加。

恢复。

附录
etcd报错:
etcdserver/api/etcdhttp: /health error;QGET failed etcdserver:request timed out(status code 503) etcdserver:publish error:etcdserver: request timed out
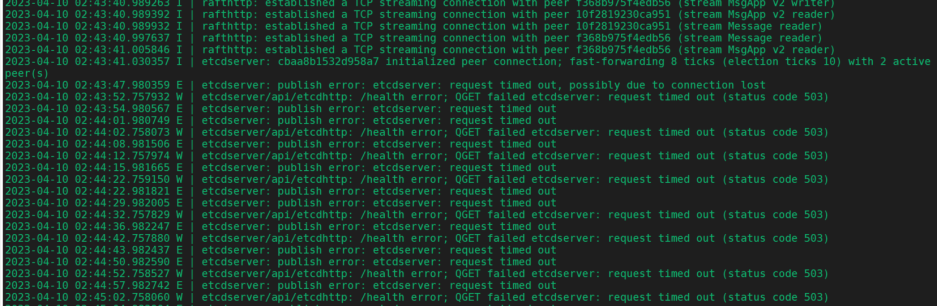
操作步骤同上,删除节点,重新添加。