背景
本地环境目前需要监控底层硬件健康状况,防止存储异常导致丢失数据。使用IPMI exporter获取到的数据不全;使用SNMP exporter的话,需要对应不同的硬件厂商mib,底层上无法控制。而我的环境中虚拟化使用的是vSphere,所以采用了vmware-exporter来监控vSphere。
部署
我这里是在k8s集群中部署的。监控是使用rancher部署的,namespace是cattle-monitoring-system,对应修改。
deployment,svc
也可以创建secret来存储密码,cm来存储配置信息。参考官方文档:https://github.com/pryorda/vmware_exporter/tree/main/kubernetes
下面的yaml中是直接存储到了环境变量中。
cat vmware-exporter.yaml
---
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: vmware-exporter
name: vmware-exporter
name: vmware-exporter
namespace: cattle-monitoring-system
spec:
progressDeadlineSeconds: 600
replicas: 1
revisionHistoryLimit: 10
selector:
matchLabels:
app: vmware-exporter
name: vmware-exporter
strategy:
rollingUpdate:
maxSurge: 1
maxUnavailable: 0
type: RollingUpdate
template:
metadata:
annotations:
labels:
app: vmware-exporter
name: vmware-exporter
spec:
containers:
- env:
- name: VSPHERE_USER
value: administrator@admin
- name: VSPHERE_PASSWORD
value: admin
- name: VSPHERE_HOST
value: "192.168.1.1"
- name: VSPHERE_IGNORE_SSL
value: "True"
- name: VSPHERE_SPECS_SIZE
value: "2000"
- name: VSPHERE_FETCH_ALARMS
value: "True"
image: pryorda/vmware_exporter
imagePullPolicy: IfNotPresent
name: vmware-exporter
ports:
- containerPort: 9272
name: tcp
protocol: TCP
resources: {}
securityContext:
allowPrivilegeEscalation: true
capabilities: {}
privileged: false
readOnlyRootFilesystem: false
runAsNonRoot: false
stdin: true
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
tty: true
dnsPolicy: ClusterFirst
restartPolicy: Always
schedulerName: default-scheduler
securityContext: {}
terminationGracePeriodSeconds: 30
---
apiVersion: v1
kind: Service
metadata:
labels:
app: vmware-exporter
name: vmware-exporter
name: vmware-exporter
namespace: cattle-monitoring-system
spec:
ports:
- name: http
port: 9272
protocol: TCP
targetPort: 9272
selector:
app: vmware-exporter
name: vmware-exporter
sessionAffinity: None
type: ClusterIP
加一个收集告警信息的配置,这样后面告警也根据这个来告警。

servicemonitor
cat vmware-exporter-servicemonitor.yaml
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
labels:
app: vmware-exporter
name: vmware-exporter
name: vmware-exporter
namespace: cattle-monitoring-system
spec:
jobLabel: vmware_vcenter
endpoints:
- interval: 60s
port: http
path: /metrics
# 需要适当调整获取metrics的超时时间,防止数据过多导致超时拉取失败。
scrapeTimeout: 30s
scheme: http
namespaceSelector:
matchNames:
- cattle-monitoring-system
selector:
matchLabels:
app: vmware-exporter
name: vmware-exporter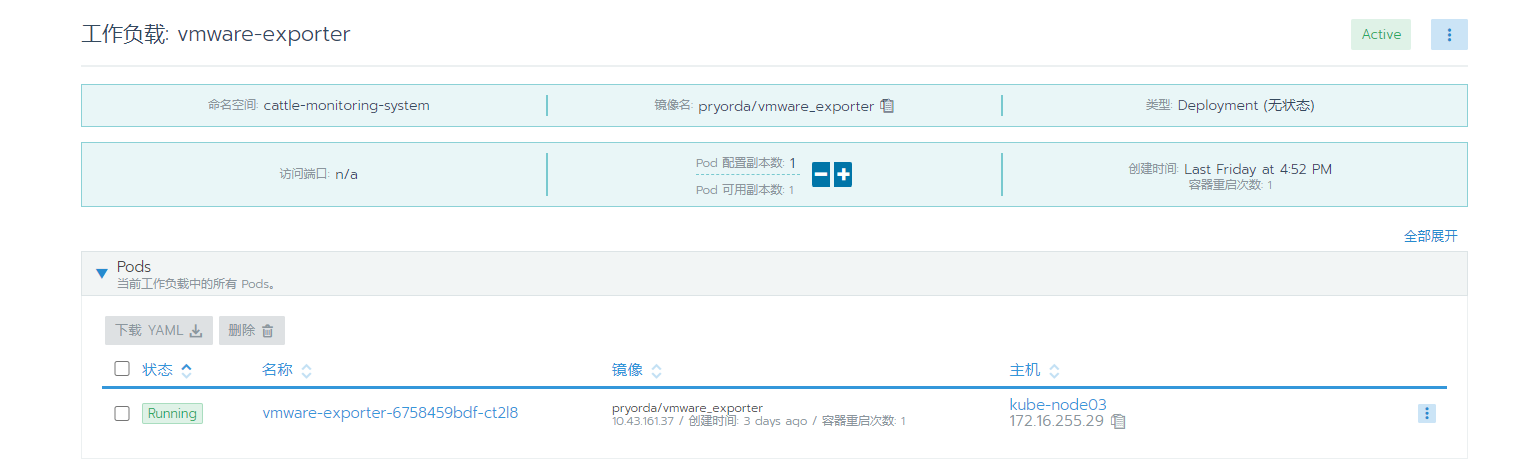
测试metrics
curl http://10.43.161.37:9272/metrics
添加grafana
导入模板11243。也可以使用官方的:https://github.com/pryorda/vmware_exporter/tree/main/dashboards

添加告警
告警尝试过用具体的metrics来实现,比如拔掉一个电源PS1,在zabbix上马上就能显示告警,而vmware-exporter获取的metrics却迟迟没有更新。所以只能采用alarm的形式来获取vSphere的告警信息。


apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
labels:
app: rancher-monitoring
release: rancher-monitoring
name: vmware-alert
namespace: cattle-monitoring-system
spec:
groups:
- name: vmware-alert
rules:
- alert: vmware-alert
expr: vmware_host_red_alarms == 1.0
for: 5m
labels:
alert_name: vmware-alert
alert_type: metric
severity: critical
comparison: equal
expression: vmware_host_red_alarms == 1.0
annotations:
description: 告警项为 {{ $labels.alarms }},告警主机为 {{ $labels.host_name }}
summary: 告警项为 {{ $labels.alarms }},告警主机为 {{ $labels.host_name }}
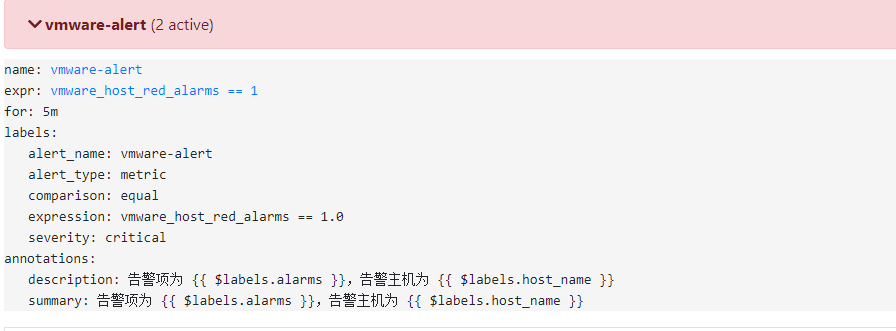
查看告警信息
