背景
上篇文章中我写了个代码获取阿里云kafka的ConsumerGroup消息堆积量。这个代码实际用下来虽然可以正确获取到堆积量,过滤到特定的ConsumerGroup,重启pod,发送消息,但是检测是通过crontab来实现的,每十分钟检测一次。
这样就会有个问题,首先检测到了消息堆积大于15万,然后重启了对应pod。然后十分钟后,消息仍然大于15万,导致pod再次发生了重启,消息仍然堆积的话就会循环下去。
解决
我没有开阿里云的ARMS,所以这里有两种方案:
方案1
整体逻辑修改为:第一次大于15万时重启对应的pod,然后第二次检查时如果消息堆积量仍然大于15万就增加2个副本数不重启pod,第三次检查时如果消息堆积量仍然大于15万则发送消息:"对应的pod已重启并扩容,堆积量仍大于15万,请到控制台查看"。
脚本是以定时任务形式运行的,每次执行都是一个独立进程,因此无法在内存中保存状态(即“这是第几次检查”)。所以需要引入持久化状态存储。最简单的方法是使用一个本地文件(例如 JSON 文件)来记录每个consumerGroup连续触发告警的次数。
新增状态处理代码state.go:
import (
"encoding/json"
"fmt"
"io/ioutil"
"os"
"sync"
"time"
)
// 定义一个常量用于状态文件路径
const StateFilePath = "/var/log/kafka-monitor-state.json"
var stateMutex sync.Mutex
// PersistentState 用于存储持久化的告警状态
type PersistentState struct {
// 键为 consumerGroup
LastCheck map[string]AlarmRecord `json:"last_check"`
}
// AlarmRecord 存储特定消费者组的告警信息
type AlarmRecord struct {
// 连续检查到堆积量超标的次数
ConsecutiveCount int `json:"consecutive_count"`
LastActionTime int64 `json:"last_action_time"` // Unix timestamp
}
// LoadState 从文件中加载状态
func LoadState() (*PersistentState, error) {
stateMutex.Lock()
defer stateMutex.Unlock()
data, err := ioutil.ReadFile(StateFilePath)
if os.IsNotExist(err) {
// 文件不存在,返回新的空状态
return &PersistentState{LastCheck: make(map[string]AlarmRecord)}, nil
} else if err != nil {
return nil, fmt.Errorf("读取状态文件失败: %w", err)
}
var state PersistentState
if err := json.Unmarshal(data, &state); err != nil {
return nil, fmt.Errorf("解析状态文件失败: %w", err)
}
// 确保 map 被初始化
if state.LastCheck == nil {
state.LastCheck = make(map[string]AlarmRecord)
}
return &state, nil
}
// SaveState 将状态保存到文件
func SaveState(state *PersistentState) error {
stateMutex.Lock()
defer stateMutex.Unlock()
data, err := json.MarshalIndent(state, "", " ")
if err != nil {
return fmt.Errorf("序列化状态失败: %w", err)
}
// 写入文件,权限设置为 0644
if err := ioutil.WriteFile(StateFilePath, data, 0644); err != nil {
return fmt.Errorf("写入状态文件失败: %w", err)
}
return nil
}修改aliyun.go,当获取到MetricData后,应调用以下新函数来代替简单地循环调用 RestartMatchingPods:
const Threshold = 150000.0 // 定义堆积阈值
// ProcessMetricDataWithStaging 检查并执行分阶段处理动作
func ProcessMetricDataWithStaging(config *Config, metricData []MetricData) error {
state, err := LoadState()
if err != nil {
fmt.Printf("Error loading state: %v. Using fresh state.\n", err)
state = &PersistentState{LastCheck: make(map[string]AlarmRecord)}
}
currentActiveGroups := make(map[string]bool)
// --- 1. 处理当前超标的消费者组 ---
for _, data := range metricData {
if data.Value > Threshold {
consumerGroup := data.ConsumerGroup
prefix := ExtractPrefix(consumerGroup)
record := state.LastCheck[consumerGroup]
// 标记为当前活跃告警
currentActiveGroups[consumerGroup] = true
// 增加连续告警计数
record.ConsecutiveCount++
record.LastActionTime = time.Now().Unix()
switch record.ConsecutiveCount {
case 1:
// 阶段一:重启 Pod
fmt.Printf("ConsumerGroup %s: 首次堆积 (%.0f),执行 Pod 重启...\n", consumerGroup, data.Value)
if err := RestartMatchingPods(config, prefix); err != nil {
fmt.Printf("重启 Pod 失败: %v\n", err)
// 失败不中断流程
}
SendDingTalkNotification(config, consumerGroup, data.Value) // 发送已重启通知
case 2:
// 阶段二:扩容 +2 副本,不重启
fmt.Printf("ConsumerGroup %s: 第二次堆积 (%.0f),执行扩容 +2...\n", consumerGroup, data.Value)
k8sClient.ScaleDeployment(prefix, 2)
// 发送扩容通知
message := fmt.Sprintf("ConsumerGroup (%s) 堆积量 (%.0f) 持续超标,已执行扩容 +2 副本。", consumerGroup, data.Value)
dingtalk.NewDingTalkRobot(config.Dingtalk.WebhookURL, config.Dingtalk.Secret).SendMessage(message)
default:
// 阶段三:第三次及以后,仅发送警告通知
fmt.Printf("ConsumerGroup %s: 连续堆积 (%.0f),发送最终警告...\n", consumerGroup, data.Value)
if record.ConsecutiveCount == 3 {
message := fmt.Sprintf("ConsumerGroup (%s) 堆积量 (%.0f) 连续三次超标。对应的Pod已重启并扩容,请立即查看控制台。", consumerGroup, data.Value)
dingtalk.NewDingTalkRobot(config.Dingtalk.WebhookURL, config.Dingtalk.Secret).SendMessage(message)
}
// 保持计数在 3 或以上,避免重复发送最终警告
record.ConsecutiveCount = 3
}
state.LastCheck[consumerGroup] = record
}
}
// --- 2. 清理已恢复正常的消费者组状态 ---
for group, record := range state.LastCheck {
if _, isActive := currentActiveGroups[group]; !isActive {
// 如果一个 group 在状态文件中有记录,但本次检查未超标,则重置计数器
if record.ConsecutiveCount > 0 {
fmt.Printf("ConsumerGroup %s 恢复正常,重置计数器。\n", group)
}
delete(state.LastCheck, group)
}
}
// --- 3. 保存新状态 ---
return SaveState(state)
}方案2
使用k8s原生方案:将kafka的消息堆积量作为自定义指标上报到Prometheus,然后配置HPA来根据这个指标自动伸缩Deployment的副本数。
优点:
- 实时性更高: HPA可以每隔几十秒检查一次指标,比10分钟的cron任务更及时。
- 原生支持: 这是k8s解决弹性伸缩问题的标准方法,无需编写复杂的控制逻辑。
- 平滑扩容: 直接增加副本数,不需要再单独写扩容代码。
我选择了方案2。
代码结构
- exporter.go:连接阿里云API,获取kakfa消息堆积数据。
- main.go:创建http server,定义并暴露metrics。
exporter.go
package main
import (
"encoding/json"
"fmt"
openapi "github.com/alibabacloud-go/darabonba-openapi/v2/client"
openapiutil "github.com/alibabacloud-go/openapi-util/service"
util "github.com/alibabacloud-go/tea-utils/v2/service"
"github.com/alibabacloud-go/tea/tea"
credential "github.com/aliyun/credentials-go/credentials"
)
const (
// 定义阿里云API调用所需的各种常量,TargetInstanceID 从 main.go 引入
apiVersion = "2019-01-01"
apiProtocol = "HTTPS"
apiMethod = "POST"
apiAuthType = "AK"
apiStyle = "RPC"
apiPathname = "/"
apiReqBodyType = "json"
apiBodyType = "json"
namespaceKafka = "acs_kafka"
metricName = "message_accumulation"
// ⚠️ 注意: TargetInstanceID 应该从 main.go 中的 Config 结构体获取
)
// MetricData 监控数据结构,包含实例ID、消费者组、堆积量值和时间戳。
type MetricData struct {
InstanceID string `json:"instanceId"`
ConsumerGroup string `json:"consumerGroup"`
Value float64 `json:"value"`
Timestamp int64 `json:"timestamp"`
}
// ClientWrapper 阿里云客户端包装器,包含阿里云客户端实例和区域ID。
type ClientWrapper struct {
client *openapi.Client
regionID string
targetInstanceID string
}
// NewClientWrapper 创建新的客户端包装器。
func NewClientWrapper(accessKeyID, accessKeySecret, regionID string, targetInstanceID string) (*ClientWrapper, error) {
credConf := &credential.Config{
Type: tea.String("access_key"),
AccessKeyId: tea.String(accessKeyID),
AccessKeySecret: tea.String(accessKeySecret),
}
cred, err := credential.NewCredential(credConf)
if err != nil {
return nil, fmt.Errorf("创建凭据失败: %w", err)
}
config := &openapi.Config{
Credential: cred,
Endpoint: tea.String(fmt.Sprintf("metrics.%s.aliyuncs.com", regionID)),
}
client, err := openapi.NewClient(config)
if err != nil {
return nil, fmt.Errorf("创建CMS客户端失败: %w", err)
}
return &ClientWrapper{
client: client,
regionID: regionID,
targetInstanceID: targetInstanceID,
}, nil
}
// baseParams 创建基础API参数。
func baseParams(action string) *openapi.Params {
return &openapi.Params{
Action: tea.String(action),
Version: tea.String(apiVersion),
Protocol: tea.String(apiProtocol),
Method: tea.String(apiMethod),
AuthType: tea.String(apiAuthType),
Style: tea.String(apiStyle),
Pathname: tea.String(apiPathname),
ReqBodyType: tea.String(apiReqBodyType),
BodyType: tea.String(apiBodyType),
}
}
// getMetricData 通过调用DescribeMetricList接口获取Kafka消息堆积监控数据。
func (cw *ClientWrapper) getMetricData() ([]MetricData, error) {
var allMetricData []MetricData
nextToken := ""
// 构造 Dimensions JSON 字符串,使用 cw 中的 targetInstanceID
dimensions := fmt.Sprintf(`{"instanceId":"%s"}`, cw.targetInstanceID)
// 循环获取所有分页数据
for {
params := baseParams("DescribeMetricList")
queries := map[string]interface{}{
"Namespace": namespaceKafka,
"MetricName": metricName,
"Period": "60",
"Length": "100",
"Dimensions": dimensions,
}
if nextToken != "" {
queries["NextToken"] = nextToken
}
request := &openapi.OpenApiRequest{Query: openapiutil.Query(queries)}
resp, err := cw.client.CallApi(params, request, &util.RuntimeOptions{})
if err != nil {
return nil, fmt.Errorf("调用DescribeMetricList失败: %w", err)
}
// 解析当前页数据
pageData, newNextToken, err := cw.parseMetricData(resp)
if err != nil {
return nil, err
}
allMetricData = append(allMetricData, pageData...)
if newNextToken == "" {
break
}
nextToken = newNextToken
}
// 数据清洗:只保留每个Group最新的那个点
latestMap := make(map[string]MetricData)
for _, m := range allMetricData {
key := m.InstanceID + "|" + m.ConsumerGroup
if exist, ok := latestMap[key]; ok {
if m.Timestamp > exist.Timestamp {
latestMap[key] = m
}
} else {
latestMap[key] = m
}
}
var result []MetricData
for _, m := range latestMap {
result = append(result, m)
}
return result, nil
}
// parseMetricData 解析监控数据
func (cw *ClientWrapper) parseMetricData(resp map[string]interface{}) ([]MetricData, string, error) {
body, ok := resp["body"].(map[string]interface{})
if !ok {
return nil, "", fmt.Errorf("API响应格式错误: body字段不是map")
}
if success, ok := body["Success"].(bool); ok && !success {
code, _ := body["Code"].(string)
msg, _ := body["Message"].(string)
return nil, "", fmt.Errorf("API返回错误: %s - %s", code, msg)
}
nextToken, _ := body["NextToken"].(string)
datapointsStr, ok := body["Datapoints"].(string)
if !ok || datapointsStr == "" {
return []MetricData{}, nextToken, nil
}
// 定义内部结构,严格匹配 API 返回的 JSON
type CloudMonitorDatapoint struct {
InstanceID string `json:"instanceId"`
ConsumerGroup string `json:"consumerGroup"`
Timestamp int64 `json:"timestamp"`
Value float64 `json:"Value"`
Maximum float64 `json:"Maximum"`
Average float64 `json:"Average"`
}
var points []CloudMonitorDatapoint
if err := json.Unmarshal([]byte(datapointsStr), &points); err != nil {
return nil, "", fmt.Errorf("解析 Datapoints JSON失败: %w", err)
}
var result []MetricData
for _, p := range points {
val := p.Value
if val == 0 {
val = p.Maximum
}
if val == 0 {
val = p.Average
}
result = append(result, MetricData{
InstanceID: p.InstanceID,
ConsumerGroup: p.ConsumerGroup,
Value: val,
Timestamp: p.Timestamp,
})
}
return result, nextToken, nil
}
main.go
package main
import (
"fmt"
"net/http"
"os"
"strings"
"time"
"github.com/prometheus/client_golang/prometheus"
"github.com/prometheus/client_golang/prometheus/promhttp"
)
// ----------------------------------------------------------------------
// 定义配置
// ----------------------------------------------------------------------
const (
// Exporter 监听端口
ExporterPort = 9876
// 指标采集周期 (例如:每 1 分钟)
CollectInterval = 1 * time.Minute
// 定义过滤目标后缀
TargetConsumerGroupSuffix = "docking_analog"
)
// Config 结构体 (用于封装配置)
type Config struct {
AccessKeyID string
AccessKeySecret string
RegionID string
TargetInstanceID string
}
// ----------------------------------------------------------------------
// Prometheus 指标定义
// ----------------------------------------------------------------------
var kafkaLagGauge = prometheus.NewGaugeVec(
prometheus.GaugeOpts{
Name: "kafka_consumer_message_accumulation",
Help: "Kafka consumer group message accumulation (lag).",
},
// 将 instance_id 和 consumer_group 作为 Prometheus 标签
[]string{"instance_id", "consumer_group"},
)
// ----------------------------------------------------------------------
// 指标收集和设置的核心逻辑
// ----------------------------------------------------------------------
// collectAndSetMetrics 周期性调用 Aliyun API 并更新 Prometheus 指标
func collectAndSetMetrics(cw *ClientWrapper) {
fmt.Printf("--- [%s] 开始调用 Aliyun CMS API 收集指标 ---\n", time.Now().Format("15:04:05"))
// 1. 调用已有的函数获取所有消费者组的堆积数据
allMetricData, err := cw.getMetricData()
if err != nil {
fmt.Printf("❌ 指标收集失败: %v\n", err)
return
}
// 2. 重置所有指标,避免保留已消失的 Group 的数据
kafkaLagGauge.Reset()
// 3. 更新 Prometheus GaugeVec
activeGroups := 0
for _, m := range allMetricData {
// 核心过滤逻辑:检查 ConsumerGroup 是否以 "docking_analog" 结尾
if !strings.HasSuffix(m.ConsumerGroup, TargetConsumerGroupSuffix) {
continue // 如果不匹配,跳过当前数据点
}
// 只有满足过滤条件的数据才会被设置到 Prometheus
if m.Value > 0 {
kafkaLagGauge.With(prometheus.Labels{
"instance_id": m.InstanceID,
"consumer_group": m.ConsumerGroup,
}).Set(m.Value)
activeGroups++
}
}
fmt.Printf("✅ 成功更新 %d 个活跃且符合过滤条件的消费者组的指标。\n", activeGroups)
}
// ----------------------------------------------------------------------
// Exporter 启动函数
// ----------------------------------------------------------------------
func startExporter(config *Config) {
// 1. 初始化 Aliyun 客户端
cw, err := NewClientWrapper(config.AccessKeyID, config.AccessKeySecret, config.RegionID, config.TargetInstanceID)
if err != nil {
fmt.Printf("❌ 初始化 Aliyun 客户端失败: %v\n", err)
os.Exit(1)
}
// 2. 注册 Prometheus 指标
prometheus.MustRegister(kafkaLagGauge)
// 3. 启动定时器,周期性调用 API
ticker := time.NewTicker(CollectInterval)
collectAndSetMetrics(cw) // 立即执行一次指标收集
go func() {
for {
select {
case <-ticker.C:
collectAndSetMetrics(cw)
}
}
}()
// 4. 启动 HTTP 服务器,暴露 /metrics 接口
http.Handle("/metrics", promhttp.Handler())
listenAddr := fmt.Sprintf(":%d", ExporterPort)
fmt.Printf("🔥 Prometheus Exporter 启动,监听地址: http://0.0.0.0%s/metrics\n", listenAddr)
if err := http.ListenAndServe(listenAddr, nil); err != nil {
fmt.Printf("❌ HTTP 服务器启动失败: %v\n", err)
os.Exit(1)
}
}
// ----------------------------------------------------------------------
// Main 函数
// ----------------------------------------------------------------------
func main() {
// 从环境变量读取配置
cfg := &Config{
// 从 K8s Deployment/Secret 注入的环境变量中读取
AccessKeyID: os.Getenv("ACCESS_KEY_ID"),
AccessKeySecret: os.Getenv("ACCESS_KEY_SECRET"),
RegionID: os.Getenv("REGION_ID"),
TargetInstanceID: os.Getenv("TARGET_INSTANCE_ID"),
}
if cfg.AccessKeyID == "" || cfg.AccessKeySecret == "" || cfg.RegionID == "" || cfg.TargetInstanceID == "" {
fmt.Println("❌ 错误: 环境变量未设置。请确保 K8s Deployment 正确注入了 AK/SK/RegionID/InstanceID。")
os.Exit(1)
}
startExporter(cfg)
}
采用了从环境变量中获取ak,sk等信息,而不是写死,这样会更安全。
构建二进制文件
# 使用 CGO_ENABLED=0 进行静态编译,确保最终镜像中不依赖C库
go build -ldflags="-s -w" -o kafka-exporter main.go exporter.goDockerfile
scratch不是一个可以下载的普通Docker镜像,而是一个Docker保留名称,代表一个完全空白的基础镜像。它不包含任何文件系统层、操作系统、库文件或配置。它的唯一作用是作为Dockerfile的 FROM指令的起点,用于构建最小化的镜像.
# 使用最小的 Alpine 镜像,仅仅为了获取证书文件
FROM alpine:3.19 AS certs
# 最终的运行镜像,体积最小
FROM scratch
# 复制证书,确保 HTTPS (Aliyun API) 调用正常
COPY --from=certs /etc/ssl/certs/ca-certificates.crt /etc/ssl/certs/
# 设置时区(可选,方便日志时间戳)
ENV TZ Asia/Shanghai
# 复制你本地已经构建好的静态二进制文件
COPY kafka-exporter /kafka-exporter
# 暴露 Exporter 端口 (与 main.go 中定义的 9876 保持一致)
EXPOSE 9876
# 容器启动时执行的命令
CMD ["/kafka-exporter"]
构建镜像:
docker build -t kafka-exporter .推送到你的镜像仓库。
部署到k8s中
创建secret:
kubectl create secret generic aliyun-secrets --from-literal=accessKeyID="xxx" --from-literal=accessKeySecret="xxx"deploy.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: aliyun-kafka-exporter
labels:
app: aliyun-kafka-exporter
spec:
replicas: 1
selector:
matchLabels:
app: aliyun-kafka-exporter
template:
metadata:
labels:
app: aliyun-kafka-exporter
spec:
containers:
- name: kafka-exporter
image: kafka-exporter:latest # 替换为你推送的镜像地址
imagePullPolicy: IfNotPresent
ports:
- containerPort: 9876
name: metrics
env:
# 1. 从 Secret 注入 Access Key 和 Secret Key
- name: ACCESS_KEY_ID
valueFrom:
secretKeyRef:
name: aliyun-secrets # 引用上面创建的 Secret
key: accessKeyID
- name: ACCESS_KEY_SECRET
valueFrom:
secretKeyRef:
name: aliyun-secrets
key: accessKeySecret
# 2. 直接设置其他配置,如 RegionID 和 InstanceID
- name: REGION_ID
value: "cn-hangzhou"
- name: TARGET_INSTANCE_ID
value: "alikafka_pre-cn-xxx"
# 3. K8s 健康检查,确保 Exporter 存活
readinessProbe:
httpGet:
path: /metrics
port: 9876
initialDelaySeconds: 5
periodSeconds: 10
livenessProbe:
httpGet:
path: /metrics
port: 9876
initialDelaySeconds: 15
periodSeconds: 20
svc.yaml
apiVersion: v1
kind: Service
metadata:
name: aliyun-kafka-exporter-service
labels:
app: aliyun-kafka-exporter
spec:
selector:
app: aliyun-kafka-exporter
ports:
- name: metrics
protocol: TCP
port: 9876
targetPort: 9876
k apply -f deploy.yaml
k apply -f svc.yaml
k get secret,svc,deploy | grep aliyun
添加target
修改prometheus.yml或者添加ServiceMonitor:
- job_name: 'kafka-exporter'
scrape_interval: 30s
metrics_path: /metrics
static_configs:
- targets: ['10.0.0.179:9876'] # kafka-exporter的Service和端口
labels:
group: 'kafka-exporter'重启prometheus。查看target:

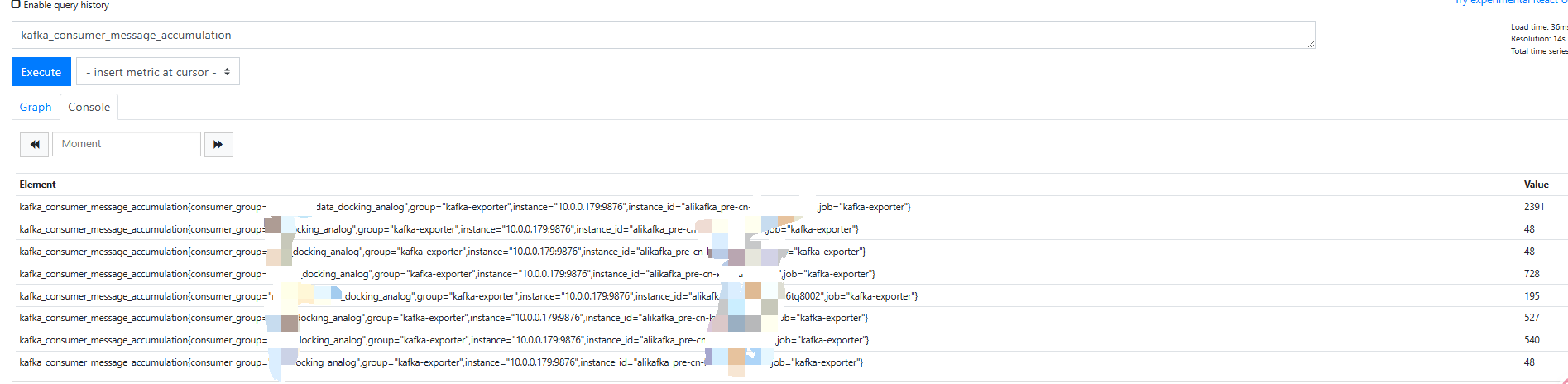
查看metrics
curl 10.0.0.179:9876/metrics | grep kafka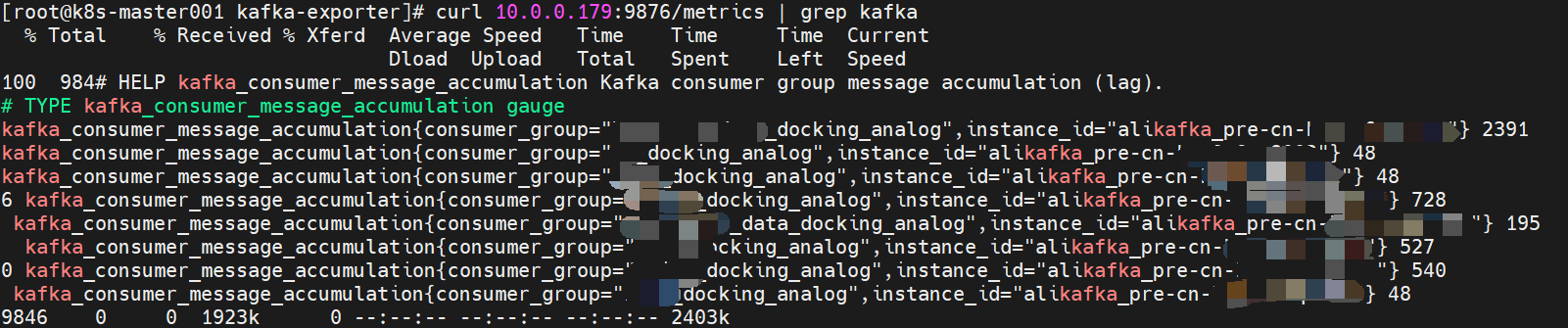
添加hpa
- 总堆积量大于10万时,扩容1个副本,大于15万时再扩容一个副本。
- 总堆积量小于5万时,缩容到2个副本。
- 最多5个副本。
使用Value而不是AverageValue:
- Value:适合全局性、总量型指标(如:消息队列总堆积数、整个服务的总QPS、总请求数)。
- AverageValue:适合与Pod个体负载强相关的指标(如:每个Pod的CPU使用率、内存使用量、每个Pod处理的连接数)。
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: kafka-consumer-hpa
namespace: your-namespace # 替换为你的命名空间
spec:
scaleTargetRef:
# 替换为你的消费者 Deployment 名称
apiVersion: apps/v1
kind: Deployment
name: my-kafka-consumer-deployment
# 最小副本数设置为 2,以满足堆积量低于 5 万时的要求
minReplicas: 2
# 最大副本数
maxReplicas: 5
behavior:
scaleUp:
# 扩容稳定窗口:120秒内持续满足扩容条件才扩容。
stabilizationWindowSeconds: 120
policies:
- type: Pods
value: 1 # 每次扩容最多增加 1 个副本
periodSeconds: 30
scaleDown:
# 缩容稳定窗口:300秒内(默认值,如果未指定)持续满足缩容条件才缩容。
# 增加这个窗口可以防止缩容震荡(默认是 300s,这里保持默认或可自定义)
stabilizationWindowSeconds: 300
# policies:
# - type: Percent
# value: 50 # 每次缩容最多减少 50% 的副本
# periodSeconds: 30
# 🚨 注意:如果 'selectPolicy' 没有被禁用,系统会使用默认或你指定的缩容策略。
# 默认策略是每 3 分钟缩减 1 个副本。我们保持默认即可实现缩容。
metrics:
# 使用 Pods 自定义指标来监控消息堆积量
- type: Pods
pods:
metricName: kafka_consumer_message_accumulation
target:
type: Value
value: 50000我这里有多个符合的ConsumerGroup,所以需要分别创建对应的hpa。
创建完成后,查看hpa,我这里报错了:unable to get metric kafka_consumer_message_accumulation: unable to fetch metrics from custom metrics API: no custom metrics API (custom.metrics.k8s.io) registered
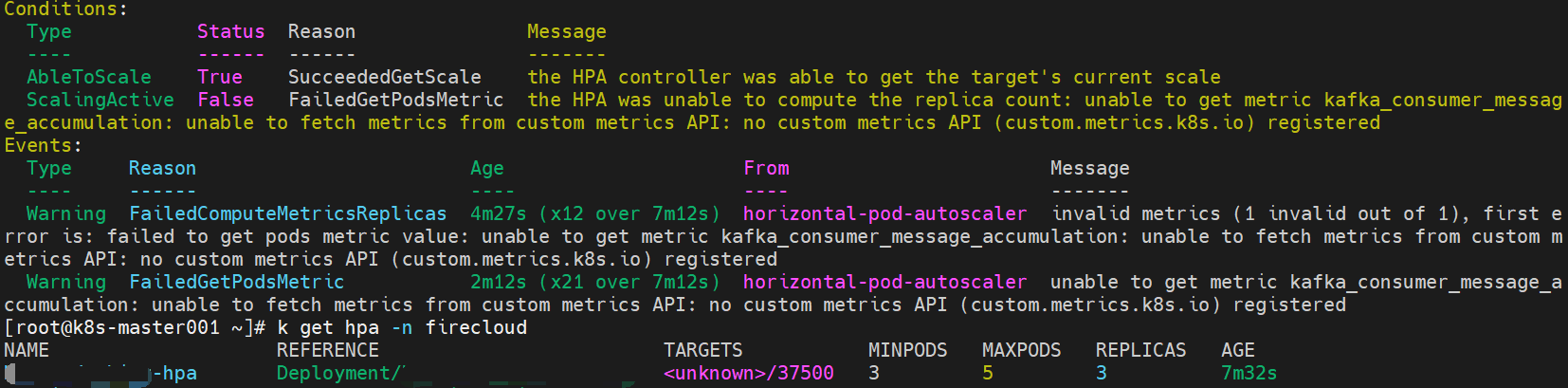

出现这个报错的原因是集群内找不到处理你的自定义指标请求的组件。需要部署Prometheus Adapter,它可以将Prometheus存储的自定义指标(如消息堆积量)转换成k8s能够理解的格式,并暴露给custom.metrics.k8s.ioAPI。
部署Prometheus Adapter
添加repo:
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
helm repo update
helm pull prometheus-community/prometheus-adapter
tar xvf prometheus-adapter-5.2.0.tgz
vim values.yaml
# 修改镜像
image:
repository: lbbi/prometheus-adapter
# if not set appVersion field from Chart.yaml is used
tag: "v0.9.1"
helm install prometheus-adapter -n firecloud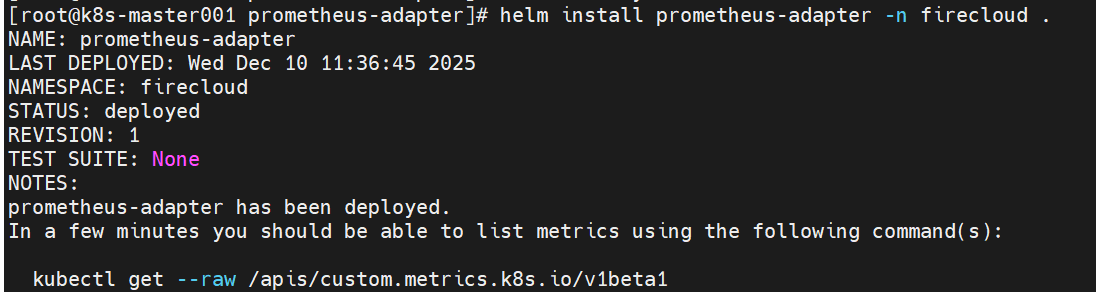

部署好后,adapter日志中能看到报错:"HTTP" verb="GET" URI="/apis/custom.metrics.k8s.io/v1beta1/namespaces/firecloud/pods/%2A/kafka_consumer_message_accumulation?labelSelector=app%3Dxxx" latency="28.14132ms" userAgent="kube-controller-manager/v1.20.11 (linux/amd64) kubernetes/27522a2/horizontal-pod-autoscaler" audit-ID="dfa96002-84fe-46e2-aba7-379772e80da0" srcIP="192.168.8.64:55252" resp=404
custom.metrics.k8s.io/v1beta1 API已经存在,并已经注册上,HPA请求的特定指标找不到返回404。
HPA请求中包含了labelSelector:app=xxx,意味着prometheus-adapter的规则不能够正确处理这个选择器,并将其映射到Prometheus数据上。
所以需要修改prometheus-adapter的规则,添加kafka_consumer_message_accumulation这个metrics的配置:
vim value.yaml
rules:
default: true
custom:
- seriesQuery: '{__name__="kafka_consumer_message_accumulation"}'
# 告诉 Adapter 这是一个 Pods 级别的指标
resources:
# 使用 <<.Resource>> 模板,让 Adapter 自动处理 Namespace 和 Pod 标签
template: <<.Resource>>
# 定义暴露给 HPA 的指标名称
name:
matches: "^kafka_consumer_message_accumulation$"
as: "kafka_consumer_message_accumulation"
# PromQL 查询:计算目标 Deployment 下所有 Pod 的指标总和
metricsQuery: |
sum(
kafka_consumer_message_accumulation{
# 使用 <<.LabelSelector>> 来应用 HPA 自动传入的标签
job="aliyun-kafka-exporter", # 替换为你 Prometheus 抓取 Exporter 的 job 名称
<<.LabelSelector>>
}
) by (pod)
helm upgrade prometheus-adapter -n firecloud .升级完成后,hpa报错:the HPA was unable to compute the replica count: unable to get external metric firecloud/kafka_consumer_message_accumulation/nil: unable to fetch metrics from external metrics API: the server could not find the metric kafka_consumer_message_accumulation for,同时adapter返回404。
解决
经多次测试,
- 需要把hpa的metrics类型修改为
External,因为kafka_consumer_message_accumulation这个metrics是和pod无关的,是一个外部metrics。 - 然后我这里有多个
ConsumerGroup,metrics的name就不能全都用kafka_consumer_message_accumulation,因为这样的话只能获取到第一个ConsumerGroup的值,第二个ConsumerGroup的值会和第一个一致。 - prometheus-adapter的配置文件也需要添加external的配置,每个
ConsumerGroup单独一个配置,然后在metricsQuery中过滤不同的ConsumerGroup。
prometheus-adapter的配置如下:
rules:
default: true
custom: []
existing:
external:
- seriesQuery: 'kafka_consumer_message_accumulation{consumer_group="cust_docking_analog"}'
resources:
# 通过 template 定义一个虚拟关联,或者明确它是全局的
template: <<.Resource>>
# 即使指标本身不带 namespace 标签,为了让 HPA 能在任何 namespace 下找到它,必须设置为 true,因为 HPA 在 namespaced 路径下寻找
namespaced: true
name:
matches: "^kafka_consumer_message_accumulation$"
# 通过as重命名
as: "cust_message_accumulation"
metricsQuery: sum(kafka_consumer_message_accumulation{consumer_group="cust_docking_analog"})
- seriesQuery: 'kafka_consumer_message_accumulation{consumer_group="cd_docking_analog"}'
resources:
template: <<.Resource>>
namespaced: true
name:
matches: "^kafka_consumer_message_accumulation$"
as: "cd_message_accumulation"
metricsQuery: sum(kafka_consumer_message_accumulation{consumer_group="cd_docking_analog"})hpa配置如下:
metrics:
- type: External
external:
metric:
name: cust_message_accumulation
target:
type: Value
value: 50000重启prometheus-adapter后,hpa可以正常可以获取到值了。

只要下面的命令正常输出,hpa就一定可以获取到数据:
kubectl get --raw "/apis/external.metrics.k8s.io/v1beta1" | jq .
kubectl get --raw "/apis/external.metrics.k8s.io/v1beta1/namespaces/firecloud/cust_message_accumulation" | jq .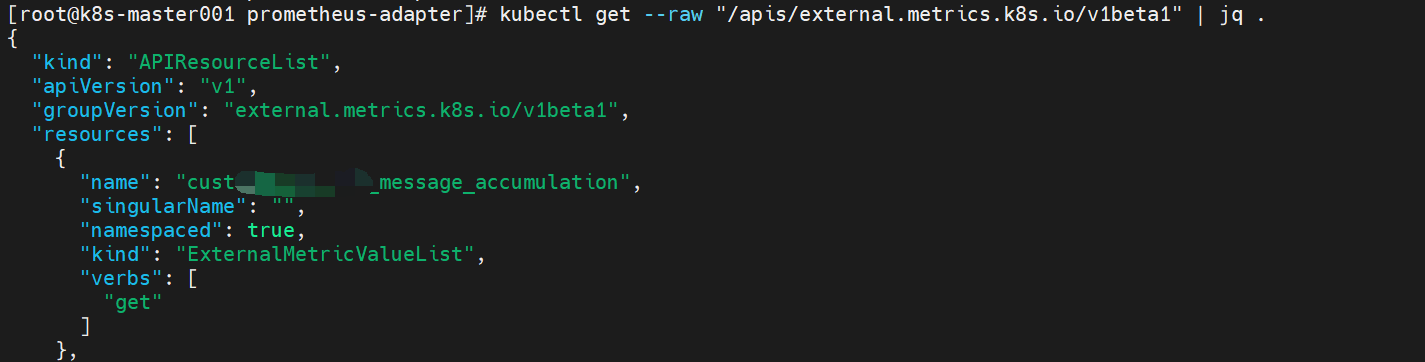
添加告警规则,当消息堆积量大于18万时发送告警消息:
- name: kafka-message-alert
rules:
- alert: KafkaMessageAccumulation
expr: kafka_consumer_message_accumulation{job="kafka-exporter"} > 180000
for: 2m
labels:
severity: critical
annotations:
summary: "消费者组 {{ $labels.consumer_group }} 消息堆积量过高"
description: "当前ConsumerGroup [{{ $labels.consumer_group }}] 堆积量为 {{ $value | humanize }}。对应的服务已扩容,消息仍然堆积,请到控制台查看。"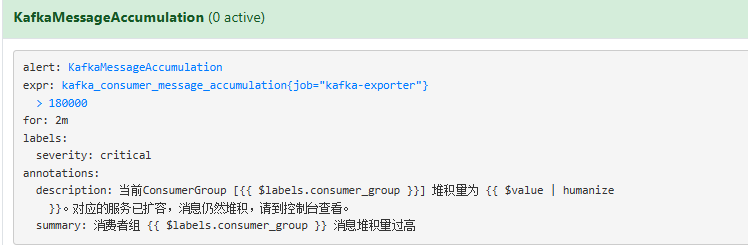
更新
上面的代码会有问题,当监控指标值为0时,Prometheus会停止暴露该指标,导致指标消失。为解决这个问题,需要在暴露指标的源头中始终输出指标值,即使值为0。
hpa也会报错:invalid metrics (1 invalid out of 1), first error is: failed to get external metric cd_message_accumulation: unable to get external metric cd_message_accumulation/nil: no metrics returned from external metrics API
整体思路是添加一个记忆机制(seenConsumerGroups):
- 使用 sync.Map 记录所有曾经出现过的符合条件的 ConsumerGroup
- 即使某次阿里云调用没有返回某个组的数据(堆积为0),我们仍然会在 Prometheus 中为该组设置指标值为0
然后始终设置指标值:
- 移除了原来的 if m.Value > 0 条件判断
- 无论值是多少,都会设置指标:有数据时用实际值,无数据时用0
修改后的代码如下:
exporter.go
// 修改 ClientWrapper 结构体,使 TargetInstanceID 可公开访问
type ClientWrapper struct {
client *openapi.Client
regionID string
TargetInstanceID string // 改为大写,使外部可访问
}
// NewClientWrapper 创建新的客户端包装器。
func NewClientWrapper(accessKeyID, accessKeySecret, regionID string, targetInstanceID string) (*ClientWrapper, error) {
credConf := &credential.Config{
Type: tea.String("access_key"),
AccessKeyId: tea.String(accessKeyID),
AccessKeySecret: tea.String(accessKeySecret),
}
cred, err := credential.NewCredential(credConf)
if err != nil {
return nil, fmt.Errorf("创建凭据失败: %w", err)
}
config := &openapi.Config{
Credential: cred,
Endpoint: tea.String(fmt.Sprintf("metrics.%s.aliyuncs.com", regionID)),
}
client, err := openapi.NewClient(config)
if err != nil {
return nil, fmt.Errorf("创建CMS客户端失败: %w", err)
}
return &ClientWrapper{
client: client,
regionID: regionID,
TargetInstanceID: targetInstanceID, // 存储实例ID
}, nil
}
// getMetricData 通过调用DescribeMetricList接口获取Kafka消息堆积监控数据。
func (cw *ClientWrapper) getMetricData() ([]MetricData, error) {
var allMetricData []MetricData
nextToken := ""
// 构造 Dimensions JSON 字符串,使用 cw 中的 targetInstanceID
dimensions := fmt.Sprintf(`{"instanceId":"%s"}`, cw.TargetInstanceID)
// 循环获取所有分页数据
for {
params := baseParams("DescribeMetricList")
queries := map[string]interface{}{
"Namespace": namespaceKafka,
"MetricName": metricName,
"Period": "60",
"Length": "1000", // 增加每次获取的数量
"Dimensions": dimensions,
}
if nextToken != "" {
queries["NextToken"] = nextToken
}
request := &openapi.OpenApiRequest{Query: openapiutil.Query(queries)}
resp, err := cw.client.CallApi(params, request, &util.RuntimeOptions{})
if err != nil {
return nil, fmt.Errorf("调用DescribeMetricList失败: %w", err)
}
// 解析当前页数据
pageData, newNextToken, err := cw.parseMetricData(resp)
if err != nil {
return nil, err
}
allMetricData = append(allMetricData, pageData...)
if newNextToken == "" {
break
}
nextToken = newNextToken
}
// 数据清洗:只保留每个Group最新的那个点
latestMap := make(map[string]MetricData)
for _, m := range allMetricData {
key := m.InstanceID + "|" + m.ConsumerGroup
if exist, ok := latestMap[key]; ok {
if m.Timestamp > exist.Timestamp {
latestMap[key] = m
}
} else {
latestMap[key] = m
}
}
// 转换为切片返回
var result []MetricData
for _, m := range latestMap {
result = append(result, m)
}
return result, nil
}main.go
package main
import (
"fmt"
"net/http"
"os"
"strings"
"sync"
"time"
"github.com/prometheus/client_golang/prometheus"
"github.com/prometheus/client_golang/prometheus/promhttp"
)
// ----------------------------------------------------------------------
// 定义配置
// ----------------------------------------------------------------------
const (
// Exporter 监听端口
ExporterPort = 9876
// 指标采集周期 (例如:每 1 分钟)
CollectInterval = 1 * time.Minute
// 定义过滤目标后缀
TargetConsumerGroupSuffix = "docking_analog"
)
// Config 结构体 (用于封装配置)
type Config struct {
AccessKeyID string
AccessKeySecret string
RegionID string
TargetInstanceID string
}
// ----------------------------------------------------------------------
// Prometheus 指标定义
// ----------------------------------------------------------------------
var (
kafkaLagGauge = prometheus.NewGaugeVec(
prometheus.GaugeOpts{
Name: "kafka_consumer_message_accumulation",
Help: "Kafka consumer group message accumulation (lag).",
},
// 将 instance_id 和 consumer_group 作为 Prometheus 标签
[]string{"instance_id", "consumer_group"},
)
// 记录所有出现过的 ConsumerGroup(符合后缀条件)
seenConsumerGroups sync.Map
seenGroupsMutex sync.RWMutex
)
// ----------------------------------------------------------------------
// 指标收集和设置的核心逻辑
// ----------------------------------------------------------------------
// collectAndSetMetrics 周期性调用 Aliyun API 并更新 Prometheus 指标
func collectAndSetMetrics(cw *ClientWrapper) {
fmt.Printf("--- [%s] 开始调用 Aliyun CMS API 收集指标 ---\n", time.Now().Format("15:04:05"))
// 1. 调用已有的函数获取所有消费者组的堆积数据
allMetricData, err := cw.getMetricData()
if err != nil {
fmt.Printf("❌ 指标收集失败: %v\n", err)
return
}
// 2. 创建当前批次数据的映射,用于快速查找
currentBatch := make(map[string]float64)
for _, m := range allMetricData {
// 只处理符合条件的 ConsumerGroup
if strings.HasSuffix(m.ConsumerGroup, TargetConsumerGroupSuffix) {
currentBatch[m.ConsumerGroup] = m.Value
}
}
// 3. 更新已见过的 ConsumerGroup 列表
seenGroupsMutex.Lock()
for group := range currentBatch {
seenConsumerGroups.Store(group, true)
}
seenGroupsMutex.Unlock()
// 4. 更新 Prometheus GaugeVec
activeGroups := 0
// 遍历所有曾经出现过的符合条件的 ConsumerGroup
seenConsumerGroups.Range(func(key, value interface{}) bool {
consumerGroup := key.(string)
lagValue, exists := currentBatch[consumerGroup]
// 关键:即使当前批次没有数据(值为0),也设置指标
// 如果阿里云没有返回该组的数据,我们假设其堆积量为0
if !exists {
lagValue = 0.0
}
// 始终设置指标值,无论是否为0
kafkaLagGauge.With(prometheus.Labels{
"instance_id": cw.TargetInstanceID, // 注意:这里需要大写字段
"consumer_group": consumerGroup,
}).Set(lagValue)
activeGroups++
return true
})
fmt.Printf("✅ 成功更新 %d 个符合条件的消费者组的指标。\n", activeGroups)
}
// ----------------------------------------------------------------------
// Exporter 启动函数
// ----------------------------------------------------------------------
func startExporter(config *Config) {
// 1. 初始化 Aliyun 客户端
cw, err := NewClientWrapper(config.AccessKeyID, config.AccessKeySecret, config.RegionID, config.TargetInstanceID)
if err != nil {
fmt.Printf("❌ 初始化 Aliyun 客户端失败: %v\n", err)
os.Exit(1)
}
// 2. 注册 Prometheus 指标
prometheus.MustRegister(kafkaLagGauge)
// 3. 启动定时器,周期性调用 API
ticker := time.NewTicker(CollectInterval)
// 首次收集(带延迟,确保客户端已初始化)
go func() {
time.Sleep(5 * time.Second)
collectAndSetMetrics(cw)
}()
go func() {
for range ticker.C {
collectAndSetMetrics(cw)
}
}()
// 4. 启动 HTTP 服务器,暴露 /metrics 接口
http.Handle("/metrics", promhttp.Handler())
listenAddr := fmt.Sprintf(":%d", ExporterPort)
fmt.Printf("🔥 Prometheus Exporter 启动,监听地址: http://0.0.0.0%s/metrics\n", listenAddr)
if err := http.ListenAndServe(listenAddr, nil); err != nil {
fmt.Printf("❌ HTTP 服务器启动失败: %v\n", err)
os.Exit(1)
}
}
// ----------------------------------------------------------------------
// Main 函数
// ----------------------------------------------------------------------
func main() {
// 从环境变量读取配置
cfg := &Config{
// 从 K8s Deployment/Secret 注入的环境变量中读取
AccessKeyID: os.Getenv("ACCESS_KEY_ID"),
AccessKeySecret: os.Getenv("ACCESS_KEY_SECRET"),
RegionID: os.Getenv("REGION_ID"),
TargetInstanceID: os.Getenv("TARGET_INSTANCE_ID"),
}
if cfg.AccessKeyID == "" || cfg.AccessKeySecret == "" || cfg.RegionID == "" || cfg.TargetInstanceID == "" {
fmt.Println("❌ 错误: 环境变量未设置。请确保 K8s Deployment 正确注入了 AK/SK/RegionID/InstanceID。")
os.Exit(1)
}
startExporter(cfg)
}
重新构建二进制包,再构建镜像,推送,更新deployment镜像:
CGO_ENABLED=0 go build -ldflags="-s -w" -o kafka-exporter main.go exporter.go
docker build -t kafka-exporter:stable .
docker push kafka-exporter:stable
k edit deploy aliyun-kafka-exporter
查看日志: