环境
rabbitmq版本:3.8.35,部署方式是pod。节点重启后集群中原来的节点没有自动删除,需要手动删除。

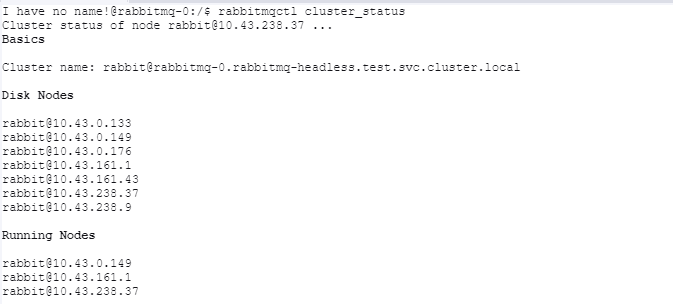
步骤
之前介绍过怎么添加节点,现在介绍下怎么删除某个节点。
由于我这里是pod,未运行的节点比如rabbit@10.43.0.133是pod的ip,但是pod已经被删除了,所以无法到pod中执行rabbitmqctl stop_app和rabbitmqctl reset命令来踢出集群。这时就需要使用rabbitmqctl forget_cluster_node命令。
rabbitmqctl forget_cluster_node rabbit@10.43.0.133
rabbitmqctl forget_cluster_node rabbit@10.43.0.176
rabbitmqctl forget_cluster_node rabbit@10.43.161.43
rabbitmqctl forget_cluster_node rabbit@10.43.238.9
rabbitmqctl cluster_status

备注
上面的情况中,集群中有正常的节点。
-
如果所有节点都挂了,并且首节点无法启动,比如node1,node2,node3,node1无法启动。
-
还有一种情况,集群中节点按照 node3、node1、node2 的顺序关闭,此时如果要启动集群,就要先启动node2节点。如果最后一个关闭的节点node2最终由于某些异常而无法启动,这时必须先踢除node2,集群才能启动。这时就需要使用
--offline参数。

下面是启动集群的步骤:
[root@node1 ~]#rabbitmqctl forget_cluster_node rabbit@node2 –offline
[root@node1 ~]# rabbitmq-server -detached
[root@node1 ~]# rabbitmqctl start_app
[root@node3 ~]# rabbitmq-server -detached
[root@node3 ~]# rabbitmqctl start_app
[root@node3 ~]#rabbitmqctl cluster_status
Cluster status of node rabbit@node3 ...
Basics
Cluster name: rabbit@node3
Disk Nodes
rabbit@node1
rabbit@node3
Running Nodes
rabbit@node1
rabbit@node3--offline 参数使节点从脱机节点上移除。使用场景主要是在所有节点脱机,且最后一个节点无法联机时,从而防止整个集群启动。在其他情况不应该使用,否则会导致不一致。如果不添加这个参数,就需要保证node2节点中的rabbitmq服务处于运行状态。
节点类型
官方文档:https://www.rabbitmq.com/clustering.html#cluster-node-types
在使用rabbitmqctl cluster_status命令来查看集群状态时,可以看到有Disk Nodes,Running Nodes。
rabbitmq中的每一个节点,不管是单机版rabbitmq服务或者是集群版rabbitmq服务中的节点,要么是内存节点,要么是磁盘节点。
- 内存节点:内存节点将所有的队列、 交换器、绑定关系、用户、权限和 vhost 的元数据定义都存储在内存中。
- 磁盘节点:磁盘节点则将这些信息存储到磁盘中。
单机版的rabbitmq服务,节点类型必须是磁盘类型的节点,否则当重启rabbitmq之后,所有关于系统的配置信息都会丢失。不过在集群版rabbitmq服务中,可以选择部分节点配置为内存节点,这样可以获得更高的性能。
然而, 由于持久化队列的数据 总是存储在磁盘上,所已内存节点只会对资源管理(如添加删除队列,交换机,vhost等)的性能加以提升,对于生产和消费消息的速度不会有任何提升。
如果只有一个磁盘节点,而且该节点刚好崩溃了,那么集群可以继续发送或者接收消息。但是,它不能执行创建队列、交换器、绑定关系、创建用户、更改权限、添加或删除集群节点的操作,直到将该磁盘节点类型的节点恢复到 RabbitMQ 集群中。所以在建立集群的时候应该保证有两个或者两个以上的磁盘节点类型的节点存在。
在内存节点类型的节点重启后,它们会连接到预先配置的磁盘节点类型的节点,下载当前集群元数据的副本。当在集群中添加内存节点类型的节点时,确保通知 RabbitMQ 集群中所有的磁盘节点类型的节点。
操作步骤
将node2节点加入node1节点的时候可以指定node2节点的类型为内存节点:
[root@node2 rabbitmq]# rabbitmqctl stop_app
[root@node2 rabbitmq]#rabbitmqctl join_cluster rabbit@node1 --ram
[root@node2 rabbitmq]# rabbitmqctl start_app
[root@node2 rabbitmq]# rabbitmqctl cluster_status
Cluster status of node rabbit@node2 ...
Basics
Cluster name: rabbit@node2
Disk Nodes
rabbit@node1
rabbit@node3
RAM Nodes
rabbit@node2如果集群已经搭建好了,那么也可以使用rabbitmqctl change_cluster_node_type {disc, ram}命令来切换节点的类型,其中:
- disc:表示磁盘节点
- ram:表示内存节点
将上面node2节点由内存节点转变为磁盘节点:
[root@node2 rabbitmq]# rabbitmqctl stop_app
[root@node2 rabbitmq]# rabbitmqctl change_cluster_node_type disc
[root@node2 rabbitmq]# rabbitmqctl start_app
[root@node2 rabbitmq]# rabbitmqctl cluster_status
Cluster status of node rabbit@node2 ...
Basics
Cluster name: rabbit@node2
Disk Nodes
rabbit@node1
rabbit@node2
rabbit@node3