背景
下面我将以这个思维导图来总结一下kubelet。
介绍
kubelet是node的守护神,维护了node上应用的生命周期,让node可以正常运行。
每个节点上都运行一个 kubelet 服务进程,默认监听 10250 端口。
- 接收并执行 master 发来的指令;
- 管理 Pod 及 Pod 中的容器;
- 每个 kubelet 进程会在 API Server 上注册节点自身信息,定期向 master 节点汇报节点的资源使用情况,并通过 cAdvisor监控节点和容器的资源。

节点管理
节点管理主要是节点自注册和节点状态更新:
- kubelet 可以通过设置启动参数 — register-node 来确定是否向 API Server 注册自己;
- 如果 kubelet 没有选择自注册模式,则需要用户自己配置 Node 资源信息,同时需要告知 kubelet集群上的 API Server 的位置;
- kubelet 在启动时通过 API Server 注册节点信息,并定时向 API Server 发送节点新消息,APIServer 在接收到新消息后,将信息写入 etcd。
Pod 管理
获取 Pod 清单方式:
- 文件:启动参数 –config 指定的配置目录下的文件即静态pod。(默认 /etc/Kubernetes/manifests/)。该文件每20秒重新检查一次(可配置)。
ps aux | grep kubelet cat /var/lib/kubelet/config.yaml
- HTTP endpoint (URL):启动参数–manifest-url 设置。每20 秒检查一次这个endpoint(可配置)。
- API Server:通过 API Server 监听 etcd 目录,同步 Pod 清单。
- HTTP Server:kubelet 侦听 HTTP 请求,并响应简单的 API 以提交新的 Pod 清单。

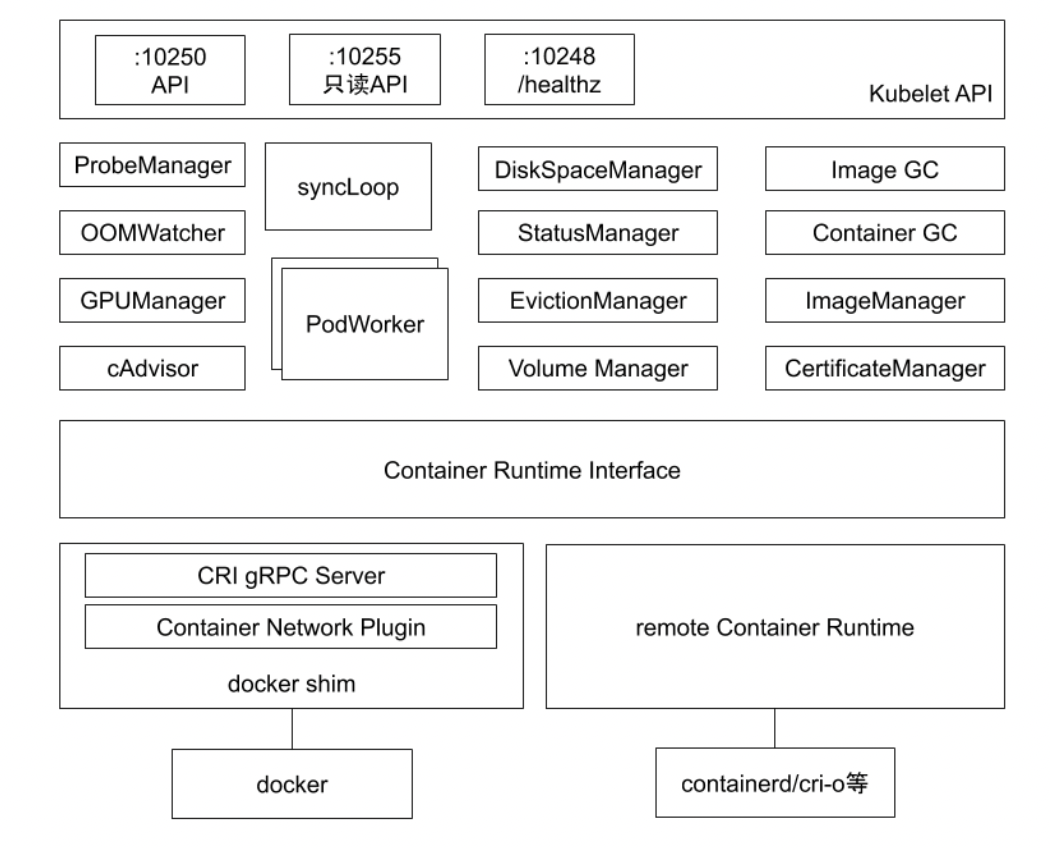
kubelet 架构
- API:10250负责和客户端交互,10255负责只读,10248负责自身的探活。
- ProbeManager:livenessProbe,readnessProbe,startupProbe,由kubelet发起负责node上的pod的探活。
- OOMWatcher:监听进程是否触发了OOM并上报给kubelet。
- GPUManager:管理node上的GPU。
- CAdvisor:内嵌于kubelet,基于cgroup获取node上运行的应用资源情况。
- DiskSpaceManager:检测pod的磁盘空间大小。
- StatusManager:管理node的状态。
- EvictionManager:检测node资源使用情况,当到达一定水位时,它会按照既定策略把低优先级的pod驱逐掉。
- Volume Manager:负责pod的存储。
- Image GC:扫描node上不活跃的镜像,把这些镜像删除掉。
- Container GC:清除Exited状态的容器。
- ImageManager:负责镜像管理。
- CertificateManager:kubelet是可以签证书的,负责证书管理。
- syncLoop:watch api对象。
- PodWorker:当syncLoop接收到pod变更通知,PodWorker就会去处理这些事件。比如看pod是否启动,如果没有就会把pod通过CRI启动。
- CRI:容器运行时接口。可以通过kubelet的启动命令指定。
- docker shim:基于docker,目前最新版已被k8s废弃。
- remote container runtime:基于containerd或者cri-o。


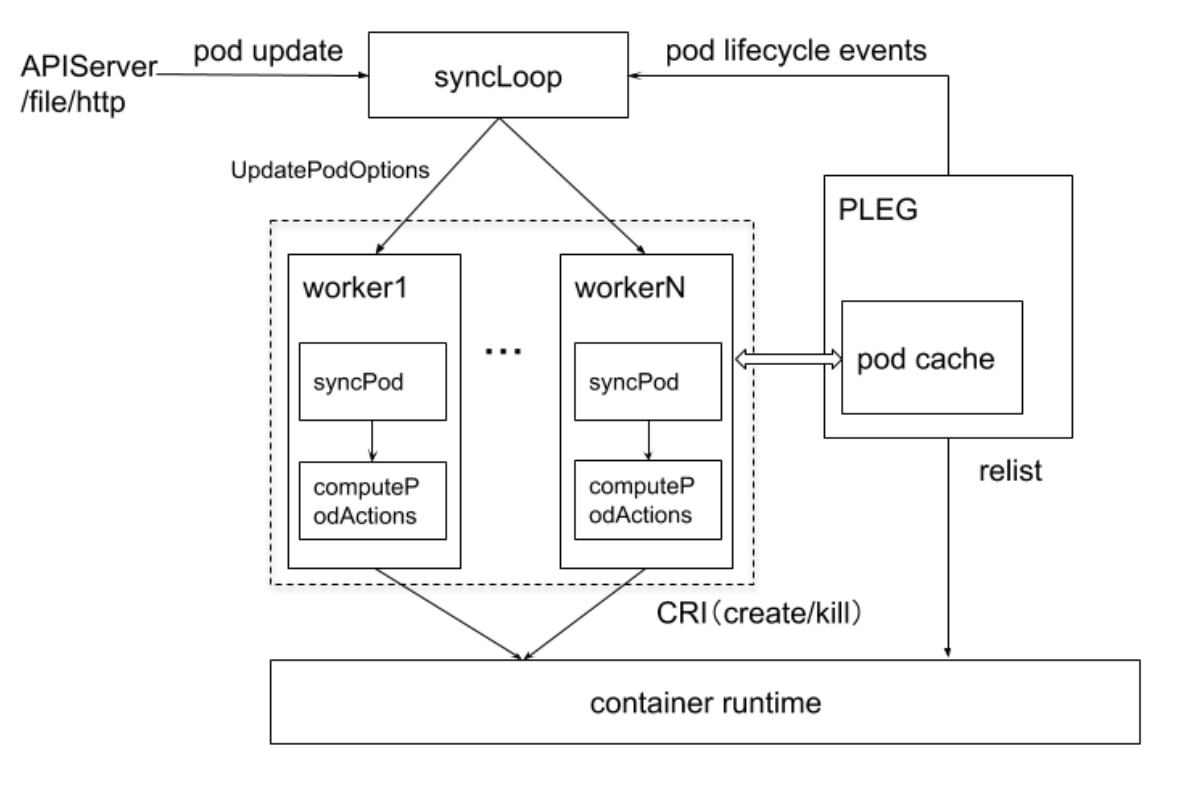
kubelet管理Pod的核心流程
- 通过apiserevr监听pod的状态变化即 pod update或者add事件。
- sycnLoop接收到事件后,会把事件存到UpdatePodOptions中。
- 不同的worker都会从队列中获取pod变更事件的清单。
- 针对每一个pod都会进行syncPod,然后会执行computePodActions,即对于这个pod需要执行什么行为。它会对比node上已经启动的容器进程,如果pod是新的,就会create,如果已经存在了,就会delete或者update。
- 通过CRI启动或者删除pod。
- PLEG:上报pod的状态信息。维护了一个本地的pod cache,定期的向CRI发起一个relist的操作来获取当前node上的正在运行的pod清单。最后再通过pod lifecycle events上报给apiserver。
注意
这里可以清晰的看到,如果runtime挂了,relist操作就会失败,pod状态无法上报,k8s就会认为这个node挂了,导致pod驱逐。
如果node上的容器进程过多,比如exited状态容器过多,relist就会一直遍历这些容器,导致耗时过长,没有在规定的时间内返回pod状态信息,PLEG就会超时,导致node状态变为Unknown,pod驱逐。
pod启动流程
我环境用的是containerd,这里也以containerd为例介绍pod的启动流程。
- 用户发送创建pod请求到apiserver。
- apiserver收到请求后会把对象存储到etcd中。存储完成后会返回给apiserver。
- scheduler 是watch apiserver的,watch到这个pod创建事件,找到一个合适的node完成调度,绑定pod。
- apiserver再把pod的信息存储到etcd中。
- kubelet watch到node上绑定的pod,首先会去启动SandboxContainer。
- containerd调用cni的插件去创建pod,即配置网络。
- cni插件把pod的ip返回给containerd,再返回给kubelet。
- kubelet调用containerd拉取镜像,创建主容器,启动主容器。
- kubelet上报pod状态给apiserver。
- apiserver再把pod状态存储到etcd中。

SandboxContainer
kubelet启动容器的时候,启动的是多个容器进程。
比如这里的nginx pod,不仅有一个nginx主容器,还有一个pause容器,这个pause容器,在k8s中就叫做SandboxContainer。pause是一个永远sleep,不会退出,不消耗任何资源的进程。
nerdctl -n k8s.io ps | grep nginx | grep -v ingress
为什么要有SandboxContainer
容器技术依靠的是namespace,cgroup,rootfs。容器启动后可以和某个网络namespace关联,就可以有独立的网络配置。容器本身进程可能不稳定,如果每一次容器退出都需要重新配置网络,就会对系统产生一定的压力,效率也不高。SandboxContainer就可以提供一个底座,让容器退出也不会更改其网络存储等配置。
某些容器进程启动是需要网络就绪的,比如java进程,或者某些需要获取第三方token的进程。这样就需要一个额外的容器来提前启动网络。把主容器的网络namespace挂载在这个sandbox即可。
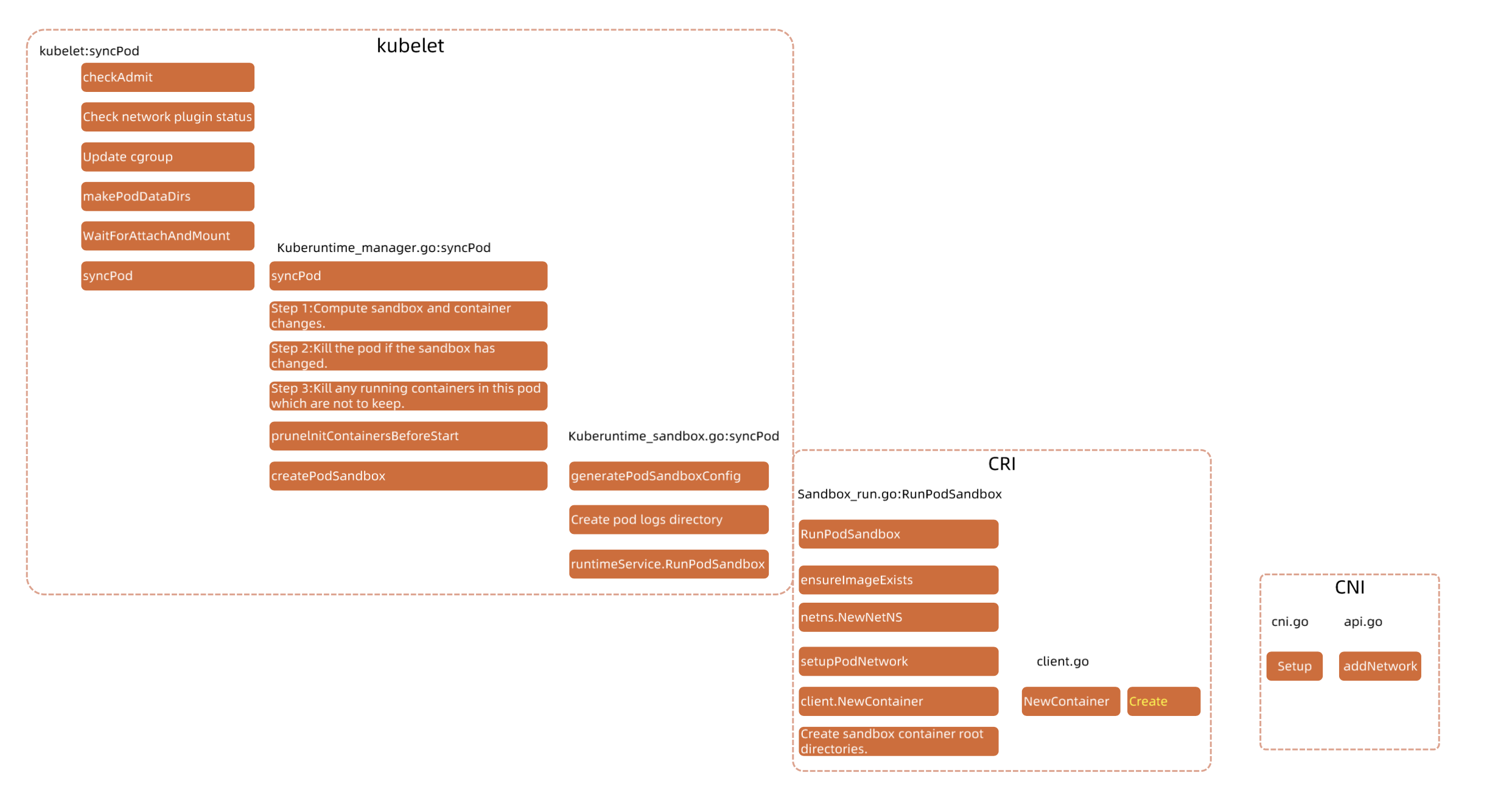
kubelet 启动 Pod 的流程
这里是更详细的pod启动流程图。
- 首先会做一个准入:看pod的资源需求是否满足node上的资源状况。
- 检查网络插件状态:如果cni挂了,pod是起不来的。
- 配置pod的cgroup。
- 创建pod数据目录。
- 等待pod存储就绪,这里就通过CSI来attach and mount pod的存储目录。
- syncPod:计算sandbox和容器的变化,如果发生了变化,就需要重新启动容器了。即上文中的ComputePodActions。
- 如果是创建pod:首先会生成sandbox的配置文件,然后创建数据目录,然后再创建sandbox。
- sandbox通过grpc接口调用CRI创建pod,过程中再调用CNI创建网络。
- 其他流程都是一致的。