背景
下面我将以这个思维导图来总结一下kube-controller-manager。

前文介绍的kube-scheduler,一边要watch pod和node的状态变化,一边要watch用户提交的requests信息作出决策,最后把结果回写到apiserver中,它也是一个controller loop。kube-scheduler其实是一个特殊的kube-controller-manager。
apiserver是一个声明式的系统,就是你给我一个应用的期望状态,我根据这个期望去做一些配置,让这个应用最终达到你的期望状态,这个就是kube-controller-manager实现的。是k8s的大脑。
工作流程
code-generator
针对任何的api对象,都可以通过code-generator来生成。它可以生成Deepcopy,Conversion,Clientset等。Clientset用来定义我如何访问这个api对象,比如create,delete,get,list,watch等。
流程
-
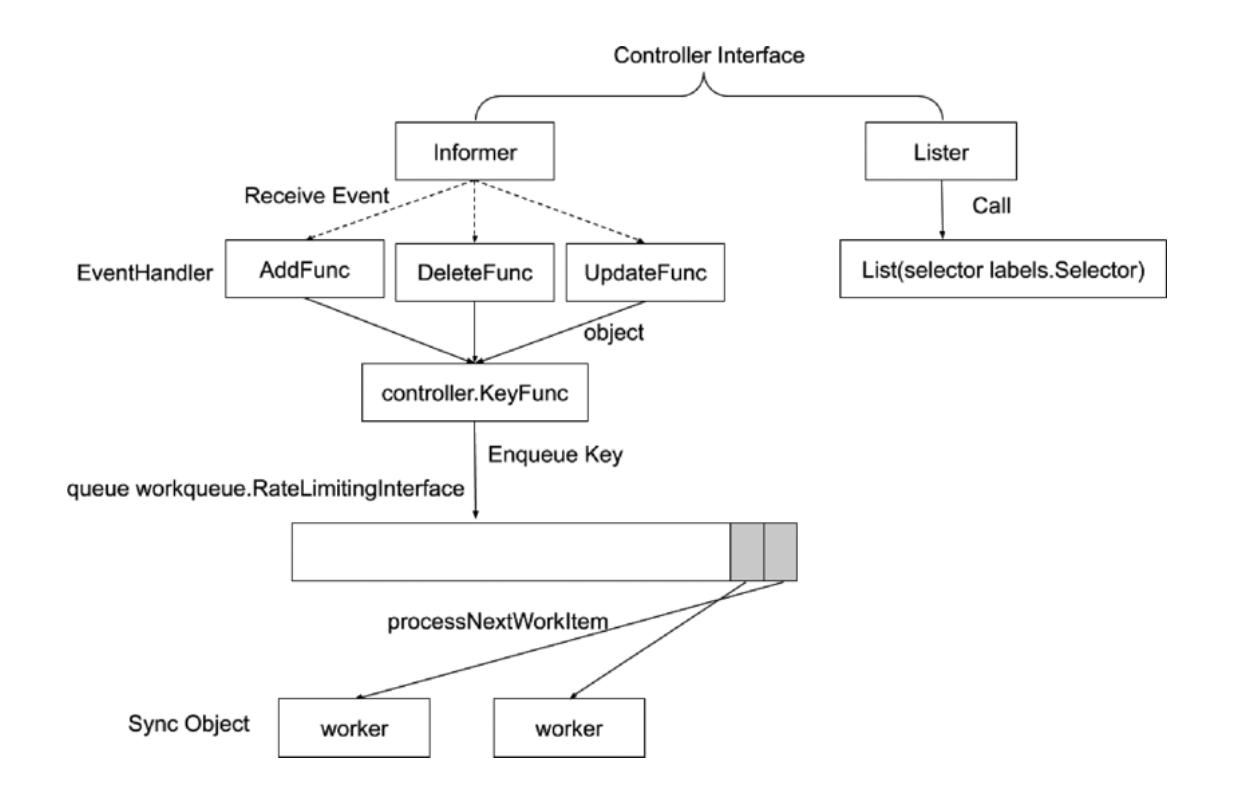
针对kube-controller-manager,code-generator生成了Informer和Lister。这两个统称为Controller Interface。
-
去apiserver获取任何一个对象的时候,有两种方式,一种是get,一种是watch。针对这两种方式,Controller Interface就分为了
- informer:有新的事件推送给用户,是一个消息通知接口。它有三种event。
- addFunc:一个对象第一次出现的时候
- deleteFunc:删除对象
- updateFunc:对象存在要变更属性
- lister:获取当前的状态
- informer:有新的事件推送给用户,是一个消息通知接口。它有三种event。
-
三种event要去注册EventHandler,event是一个完整的对象,大部分的控制器会去拿到这个对象的KeyFunc(对象的namespace+name),然后把这个key通过RateLimitinglnterface放到队列里面。
-
其实就是一个生产者消费者模型,通过一些线程获取key数据并放到一个队列里,再通过一些worker线程去消费数据。k8s默认是5个worker线程。
-
worker从队列里取到的只是一个key,并不是对象的完整数据。完整数据要通过lister接口去获取。lister会在本地缓存一份对象的数据,再有新数据的时候就不用和apiserver通信,直接从本地获取。
为什么放到队列里的不是对象的完整数据
如果有一个对象频繁变更,如果把对象的完整信息放到队列里,首先队列需要的内存空间会很大,其次假如对象要变更10次,那么worker也要变更10次。而使用对象的key,不管有多少次变更event,推送到队列里的只有一个key,worker线程通过lister接口获取这个对象的最终状态,worker只需要根据这个最终状态变更1次即可。
控制器协同工作原理
k8s是一个微服务管理系统,不同的组件负责不同的职责。
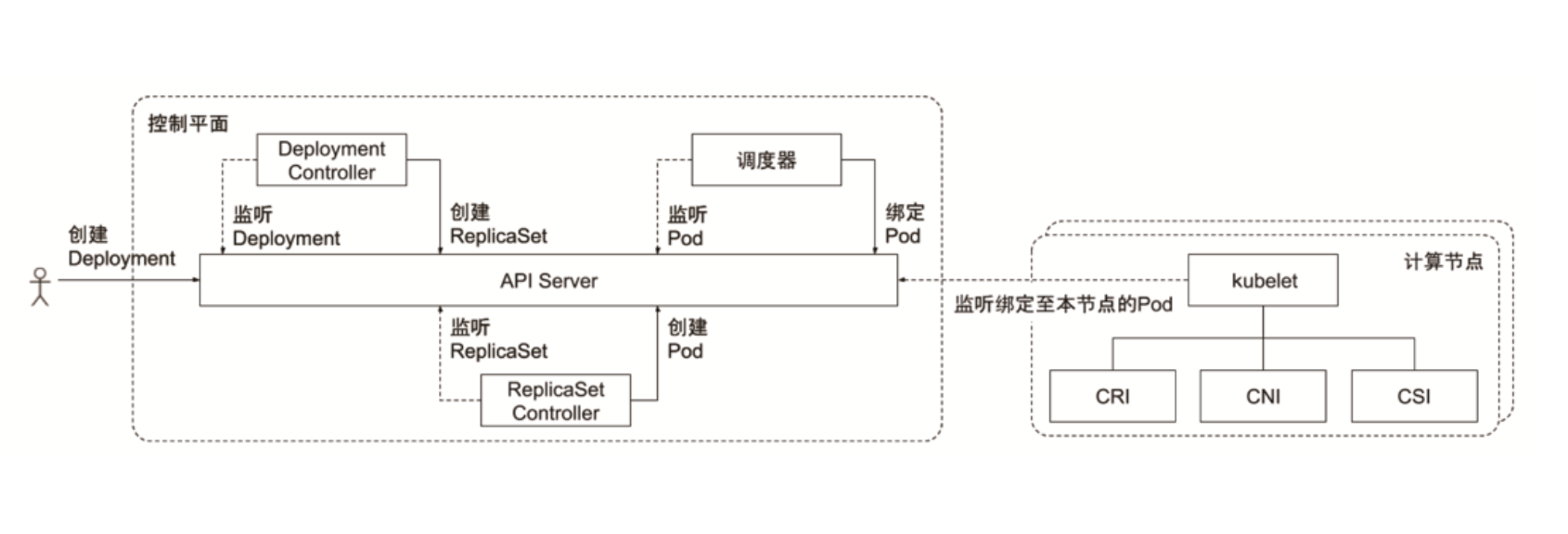
以下图的deployment为例,用户创建一个deployment。
- deployment是一种部署策略,定义了需要什么样的pod,副本数是多少。
- deployment controller watch到deployment,创建一个replicaset副本集。
- replicaset controller watch到replicaset,创建pod副本集。
- 调度器发现pod还没有调度,开始调度pod,把pod和node绑定。
- kubelet监听本节点上的pod,如果调度的节点和本节点的FQDN.Hostname一致,就会启动pod。
- kubelet调用CSI为容器配置存储。
- kubelet调用CNI为容器配置网络。
- kubelet调用CRI启动容器。
实践
k get deploy -o yaml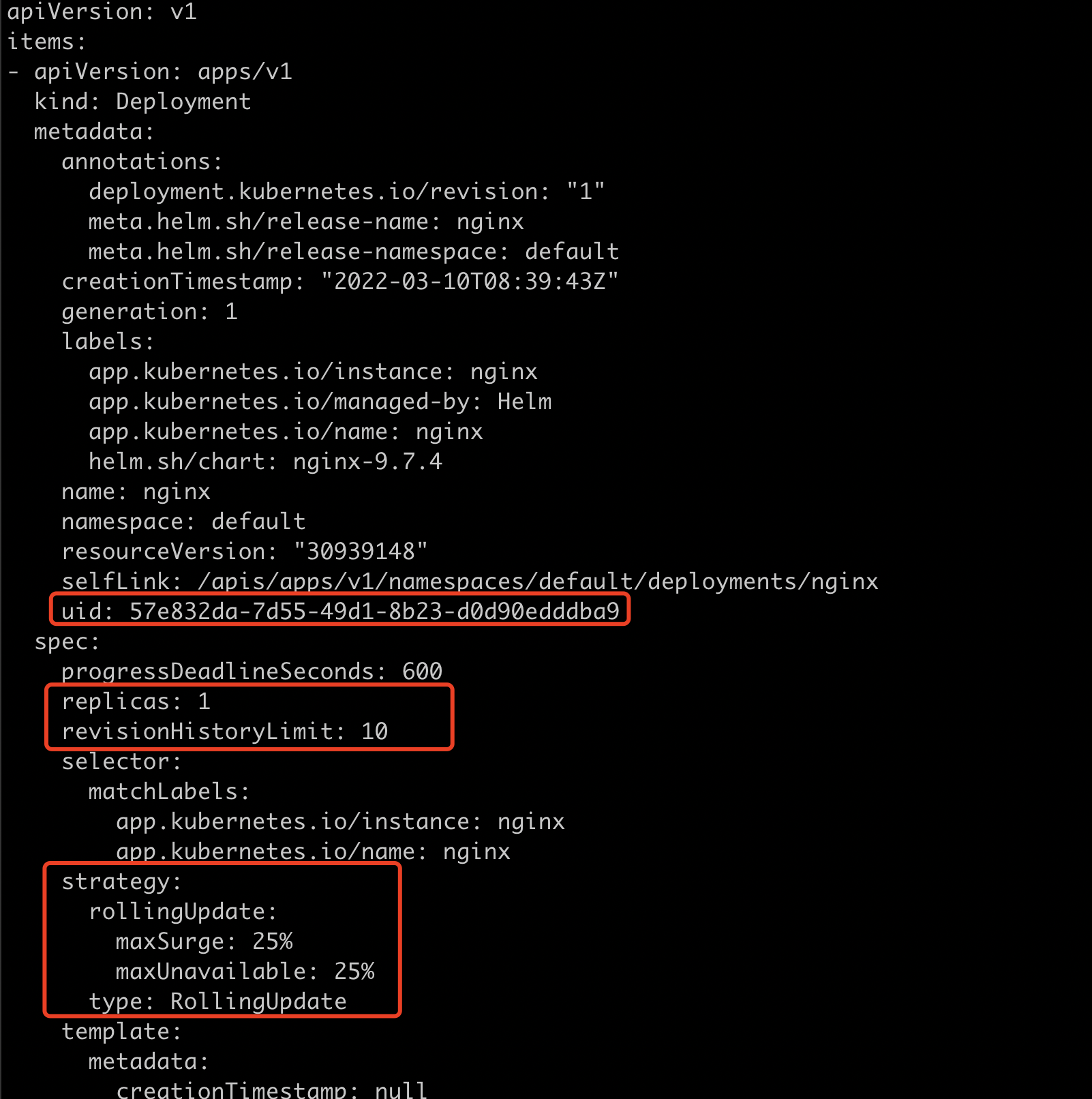
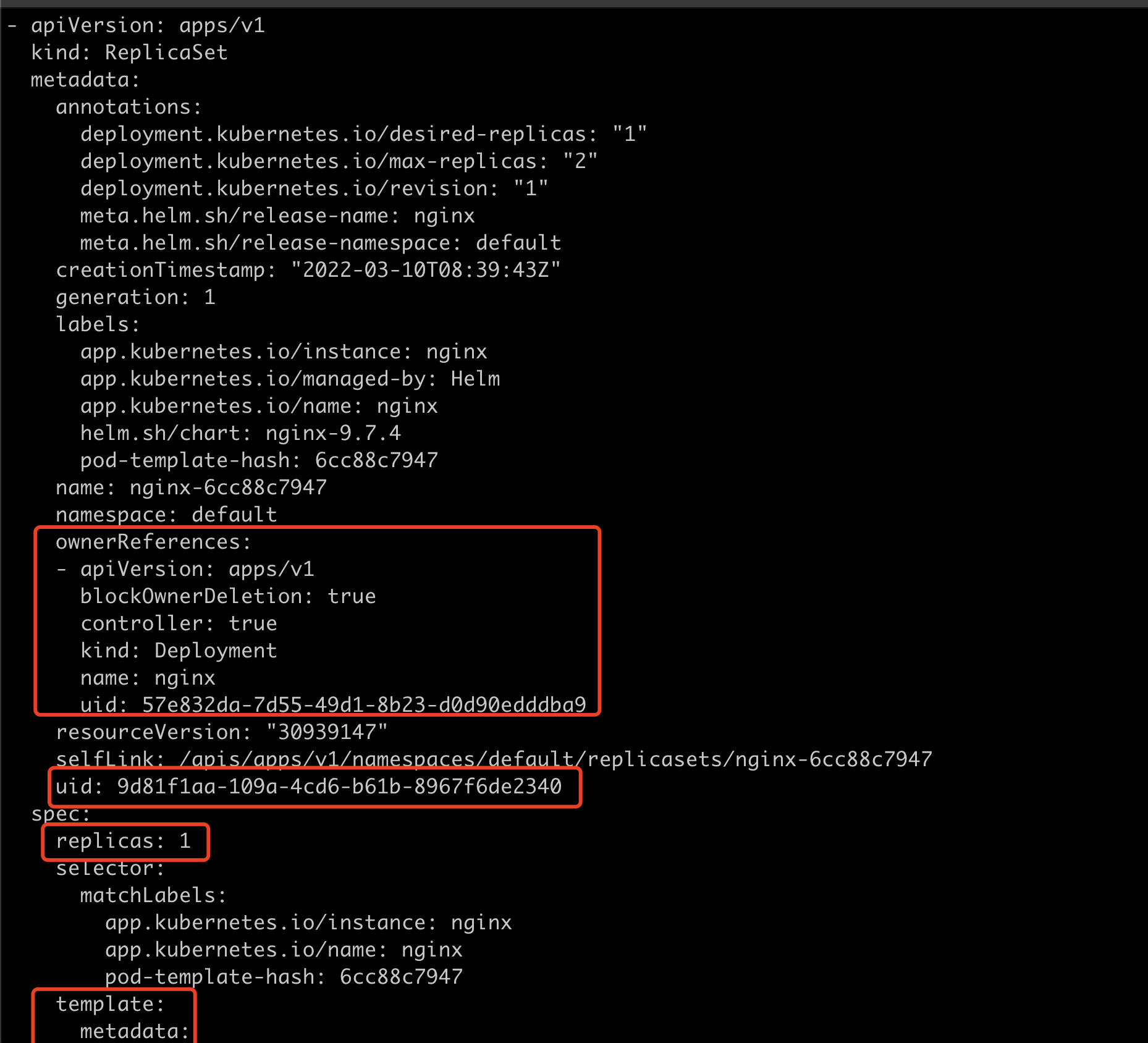
k get rs -o yaml可以看到metadata有一个ownerReferences属性,代表着它的父辈是谁。这里就是nginx的deployment。uid也是deployment的uid。
k get po -o yaml可以看到pod的ownerReferences中,指向的是nginx的rs。
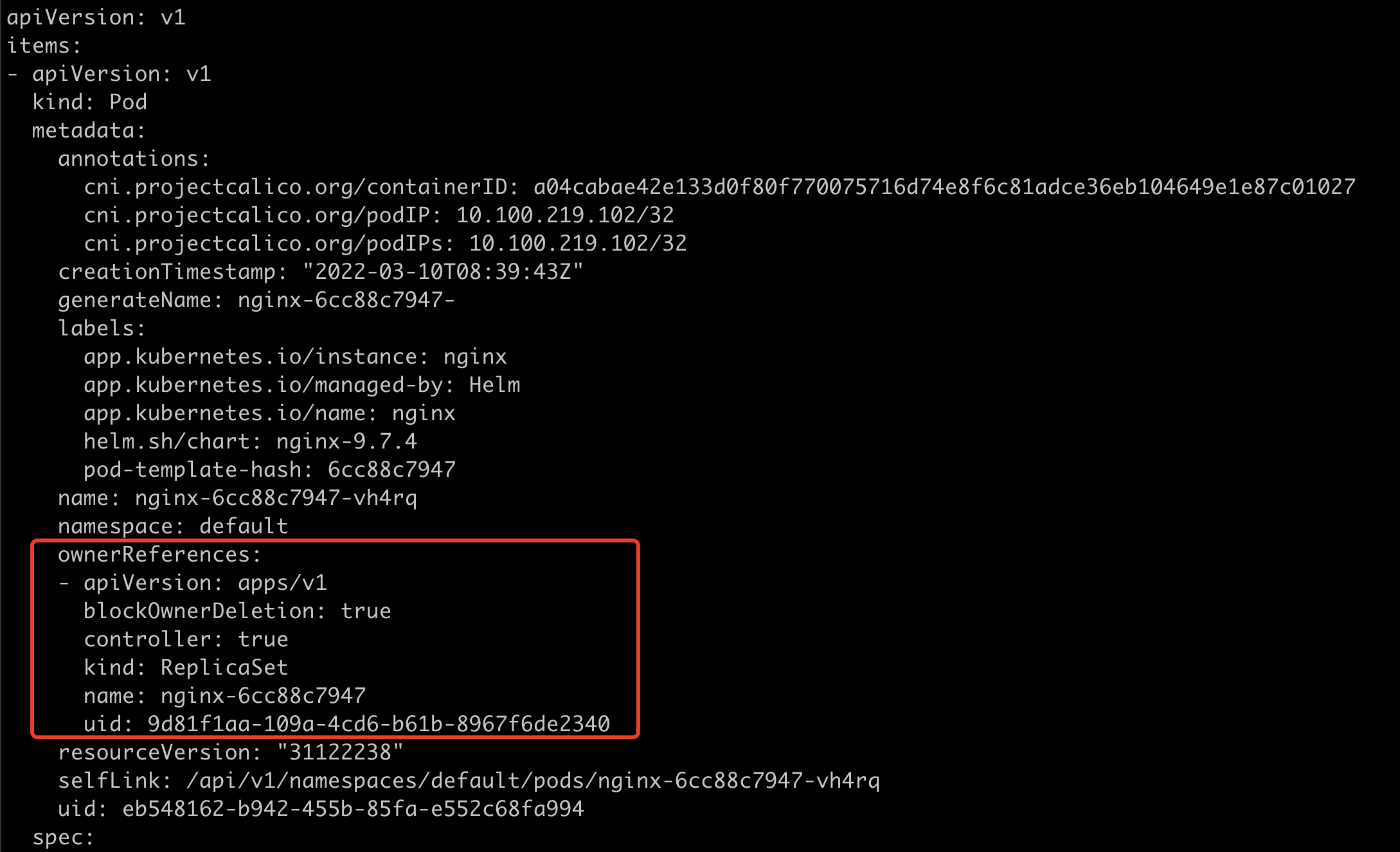
pod的命名规则
nginx pod名字是nginx-6cc88c7947-vh4rq,6cc88c7947是pod模版的hash值,即上图中rs的metadata中“pod-template-hash: 6cc88c7947”。hash值发生了改变,代表着需要重新部署应用。
然后会以这个generateName为前缀:“generateName: nginx-6cc88c7947-”,如果generateName填好了,k8s就会在其后面随机生成一个字符串vh4rq放在后面,这样就保证了pod名字唯一。

Informer的工作机制
- informer会和apiserver有一个长连接,通过list和watch。
- apiserver的rest调用返回给客户端的是序列化的json字符串。reflector通过反射机制解析json tag,这样就能知道这个json对应的是哪个对象。简而言之就是reflector把json的字符串转换成了go语言的对象。
- informer内部维护了一个delta fifo 先进先出的队列,reflector把对象放进队列中。
- 取出来的对象放到indexer中,存储对象和key到一个线程安全的store中。
- 在添加对象的同时,event会触发事件,注册event的handler。
- handler把对象的key放到workqueue队列中。
- worker的线程去获取key。
- worker从indexer中根据key获取对象的完整数据。
- 根据对象的完整数据做一些配置管理。

controller
- Job Controller: 处理 job。
- Pod AutoScaler:处理 Pod 的自动缩容/扩容。
- RelicaSet:依据 Replicaset Spec 创建 Pod。
- Service Controller: 为 LoadBalancer type 的 service 创建 LB VIP。
- ServiceAccount Controller: 确保 serviceaccount 在当前 namespace 存在。
- StatefulSet Controller:处理 statefulset 中的 Pod。
- Volume Controller: 依据 PV spec 创建 volume。
- Resource quota Controller:在用户使用资源之后,更新状态。
- Namespace Controller:保证 namespace 删除前该 namespace 下的所有资源都先被删除。
- Replication Controller:创建RC 后,负责创建 Pod。
- Node Controller:维护 node 状态,处理 evict 请求等。
- Daemon Controller:依据 damonset 创建 Pod。
- Deployment Controller:依据 deployment spec 创建 replicaset。
- Endpoint Controller:依据 service spec 创建 endpoint,依据 podip 更新 endpoint。
- Garbage Collector:通过ownerReferences处理级联删除,它的内部会有一个Graph Builder,构建一个父子关系图。比如删除 deployment 时它会去扫描自己的Graph Builder,看有没有对象的ownerReferences是这个deployment,所以也会删除对应的 replicaset 以及 Pod。
- CronJob Controller:处理 cronjob。
Cloud Controller Manager
什么时候需要 cloud controller manager?
cloud Controller Manager 自 Kubernetes1.6 开始,从 kube-controller-manager 中分离出来,主要因为 Cloud Controller Manager 往往需要跟企业云做深度集成。
与 Kubernetes 核心管理组件一起升级是一件费时费力的事。
通常 cloud controller manager 需要:
- 认证授权:企业 cloud 往往需要认证信息,Kubernetes要与 cloud API通信,需要获取 cloud系统里的 ServiceAccount;
- cloud controller manager 本身作为一个用户态的 component,需要在 Kubernetes 中有正确的RBAC 设置,获得资源操作权限;
- 高可用:需要通过 leader election 来确保 cloud controller manager 高可用。
Cloud Controller Manager 的配置
Cloud Controller Manager 是从老版本的 API Server 分离出来的。
- kube-apiserver 和 kube-controller-manager 中一定不能指定 cloud-provider,否则会加载内置的 cloud controller manager。
- kubelet 要配置 –cloud-provider=external。
Cloud Controller Manager 主要支持:
- Node controller:访问 cloud APl,来更新 node 状态;在 cloud 删除该节点以后,从Kubernetes 删除 node;
- service controller: 负责配置为 loadbalancer 类型的服务配置 LB VIP;
- Route Controller:在 cloud 环境配置路由;
- 可以自定义任何需要的 Cloud Controller。
需要定制的 Cloud Controller
- Ingress controller;
- Service Controller;
- RBAC controller;
- Account controller。
建议
保护好 controller manager 的 kubeconfig:
- 此 kubeconfig 拥有所有资源的所有操作权限,防止普通用户通过 kubectl exec kube-controller-manager cat 获取该文件。
确保 scheduler 和 controller 的高可用
Leader Election
- k8s提供基于 configmap 和 endpoint 的 leader election 类库。
- k8s采用leader election 模式启动应用组件后,会创建对应 endpoint,并把当前的leader 信息 annotate 到 endponit 上。
流程
- 假如集群有3个master,每个master上都跑了控制器。控制器在启动前都会去尝试获取一把锁。这个锁就是k8s对象(cm或者ep)。
- 下面的ep配置中,所有的scheduler实例都会以kube-scheduler的名字获取这把锁,看这个ep是否存在,如果存在,就把自己的身份信息更新进去。
- 当要调度的时候,首先要看ep中的holderldentity是否和当前节点名字一致,如果一样才能进行调度。同时leader也要不停的renew,leaseDurationSeconds 如果在15秒内没有来续约,就会认为leader失效,其他standby就会去获取锁。
- 不一致节点就会一直watch这把锁,直到租约失效。
apiversion: v1
kind: Endpoints
metadata:
annotations:
control-plane.alpha.kubernetes.io/leader:
"{"holderldentity" "master","leaseDurationSeconds":15,"acquireTime":"2022-03-
05T17:31:29Z","renewTime":"2022-03-07T07:18:39Z","leaderTransitions":0""
creationTimestamp: 2022-03-05T17:31:29Z
name: kube-scheduler
namespace: kube-System
resourceVersion: "138930"
selfLink: /api/v1/namespaces/kube-system/endpoints/kube-scheduler
uid: 2d12578d-38f7-11e8-8df0-0800275259e5
subsets: null