核心是使用reindex来进行同步。
同集群数据同步
查看源索引设置
GET onoffline_message_index/_settings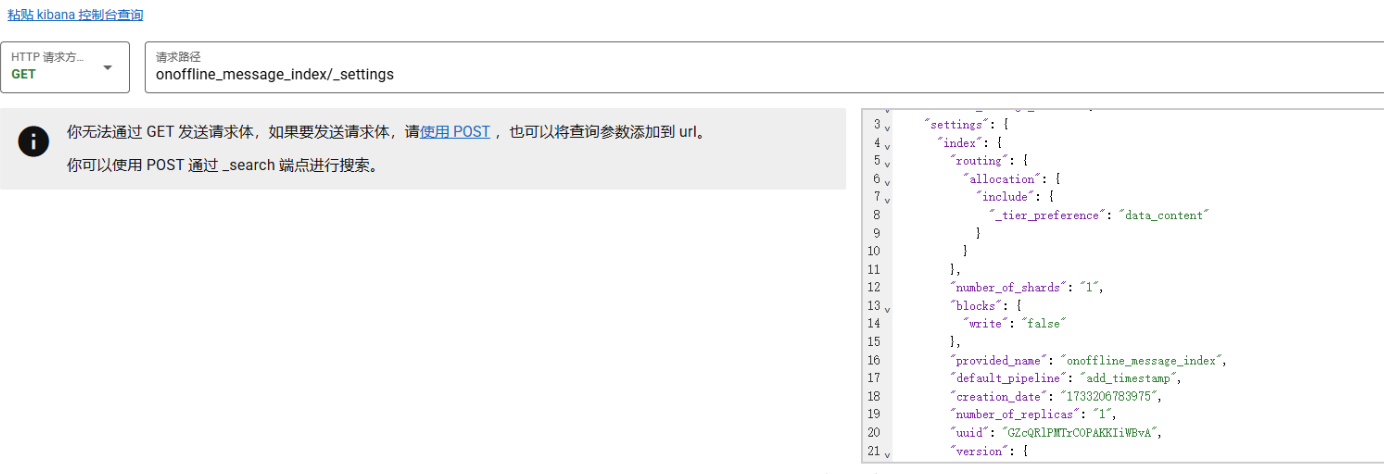
查看源索引mapping
GET onoffline_message_index/_mapping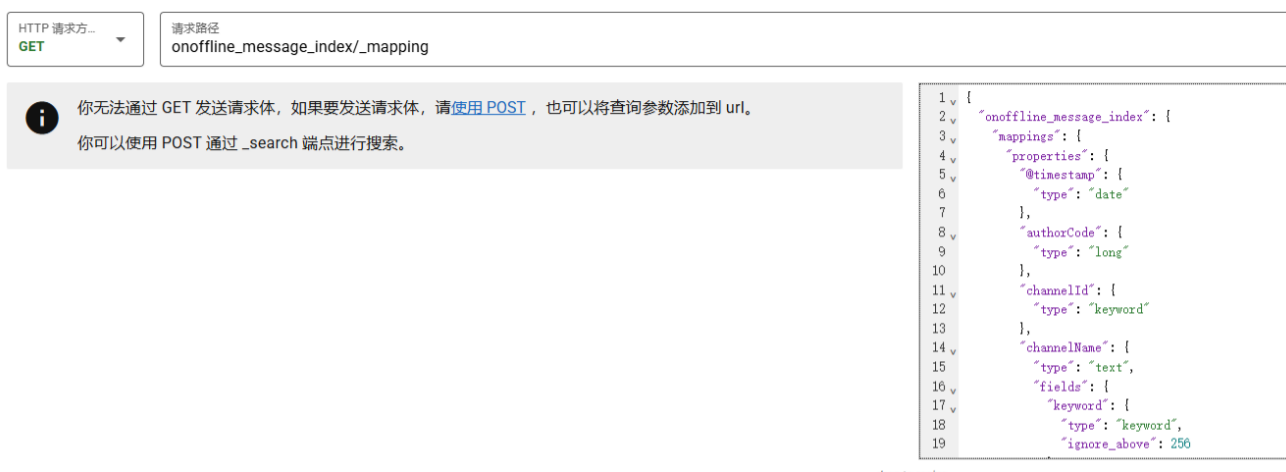
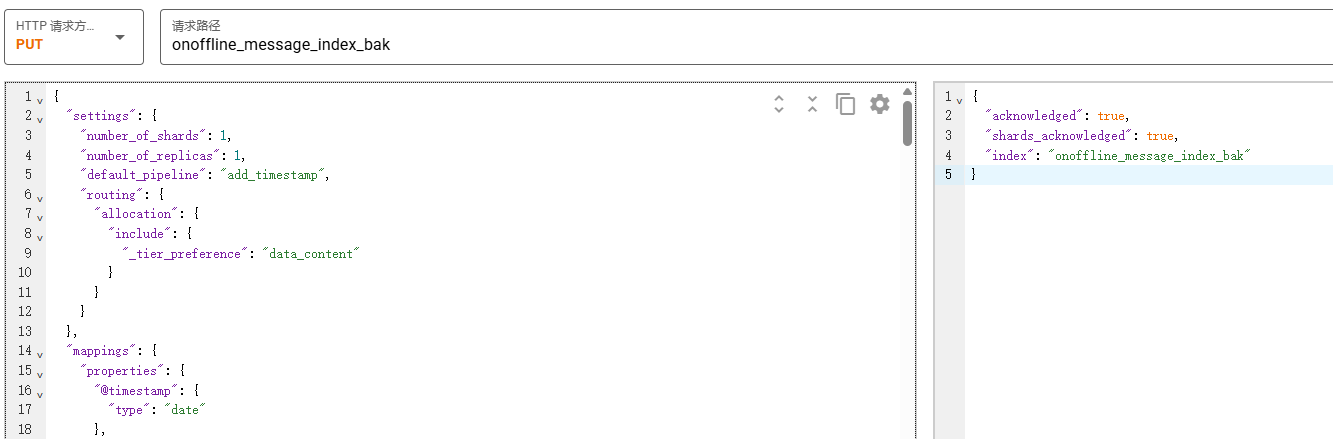
创建目标索引
根据上面的查到的设置和mapping做对应修改。
"blocks": { "write": "false" } 表示允许写入,这是默认状态,因此在创建命令中可以省略。
uuid, creation_date, version.created, provided_name 等属性是 Elasticsearch 在索引创建时自动生成的。
PUT onoffline_message_index_bak
{
"settings": {
"number_of_shards": 1,
"number_of_replicas": 1,
"default_pipeline": "add_timestamp",
"routing": {
"allocation": {
"include": {
"_tier_preference": "data_content"
}
}
}
},
"mappings": {
"properties": {
"@timestamp": {
"type": "date"
},
"id": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
。。。
}
}
}
}
}
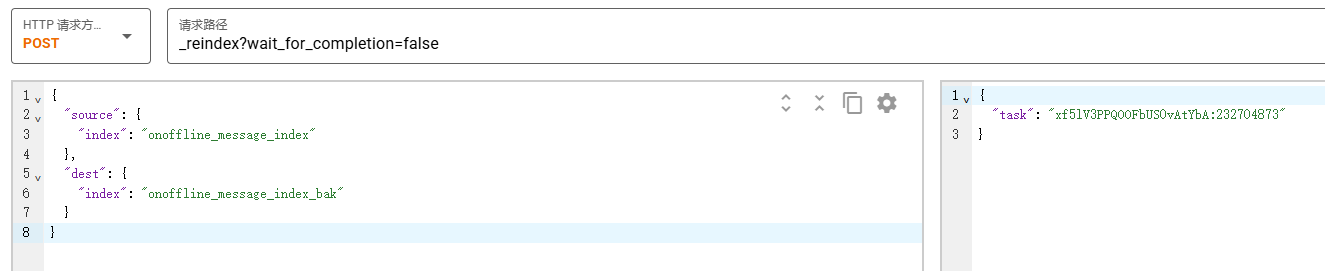
数据同步
POST _reindex?wait_for_completion=false
{
"source": {
"index": "onoffline_message_index"
},
"dest": {
"index": "onoffline_message_index_bak"
}
}执行后,Elasticsearch 会立即返回一个任务ID,而不是等待任务完成。
查看任务的详细状态和进度
GET _tasks/xf5lV3PPQOOFbUS0vAtYbA:232704873
GET _tasks?detailed=true&actions=*reindex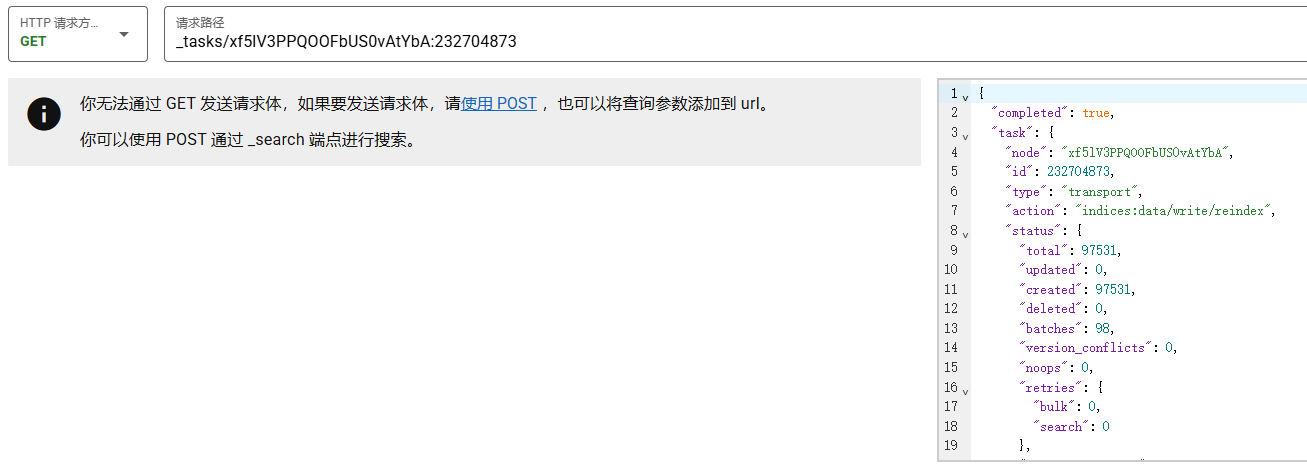
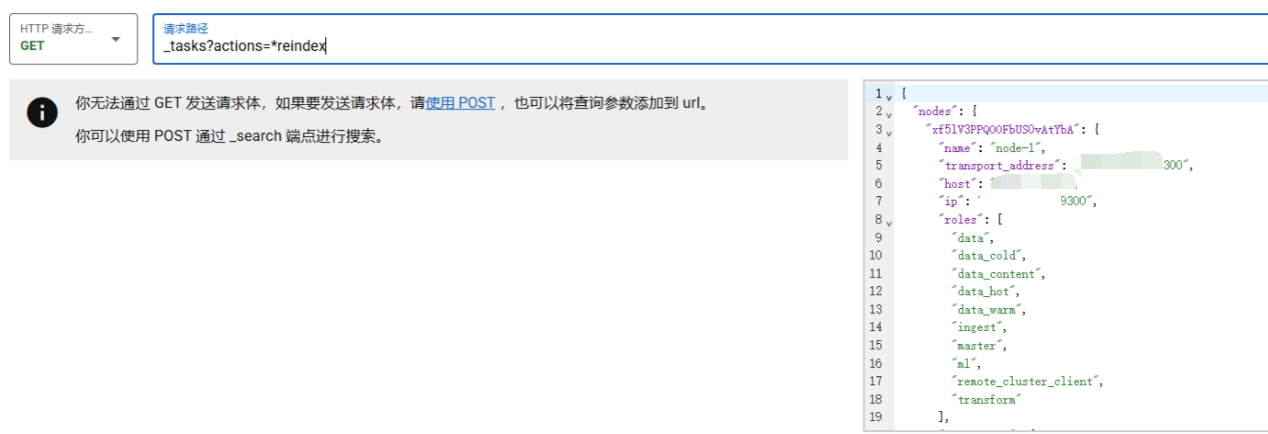
同步完成。

如果想取消任务:
POST _tasks/xf5lV3PPQOOFbUS0vAtYbA:232704873/_cancel跨集群数据同步
环境1:es docker 7.10.1 test index,同步到环境2:es k8s pod 7.10.2 test index。
方法:Reindex from Remote
使用环境2 es的 _reindex API 从环境1 es拉取数据。前提是两个环境可以互访。
配置白名单
环境2中执行:
PUT _cluster/settings
{
"persistent": {
"reindex.remote.whitelist": "1.2.3.4:9200"
}
}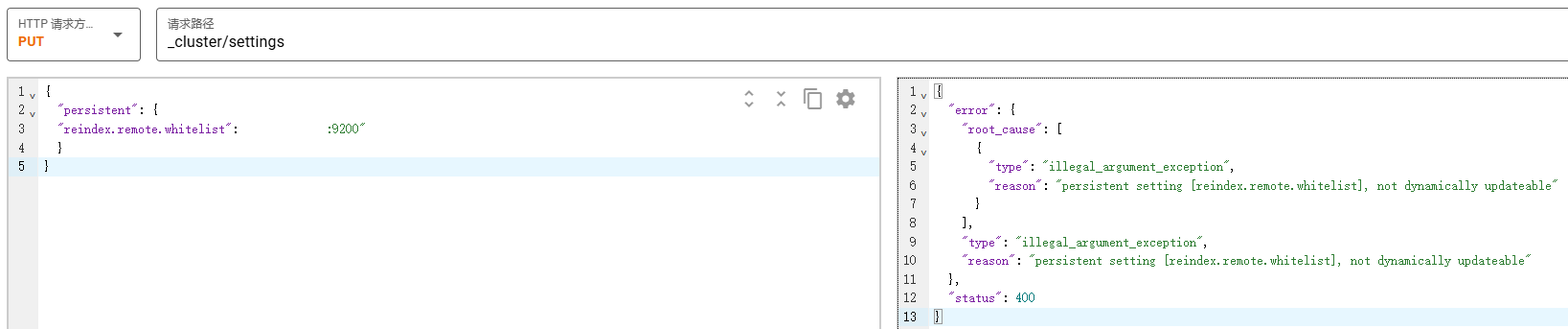
报错了,需要修改es的配置文件。
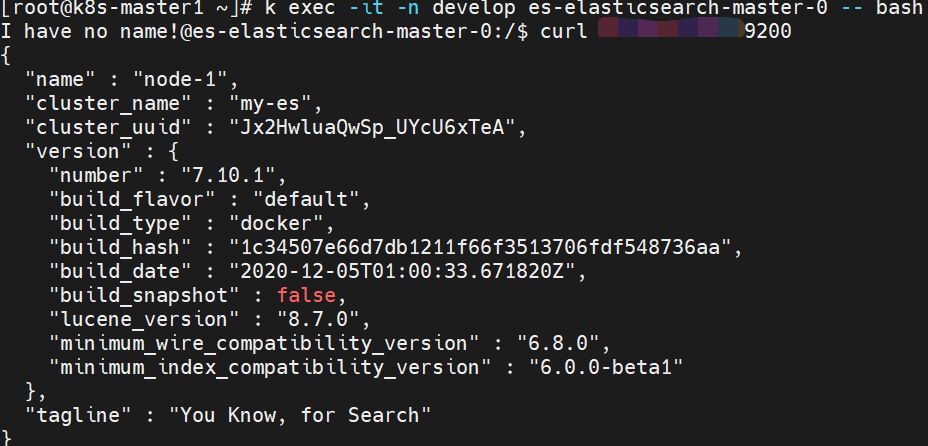
环境2的es是helm部署的,没有映射配置文件。进入pod内查看elasticsearch.yml:
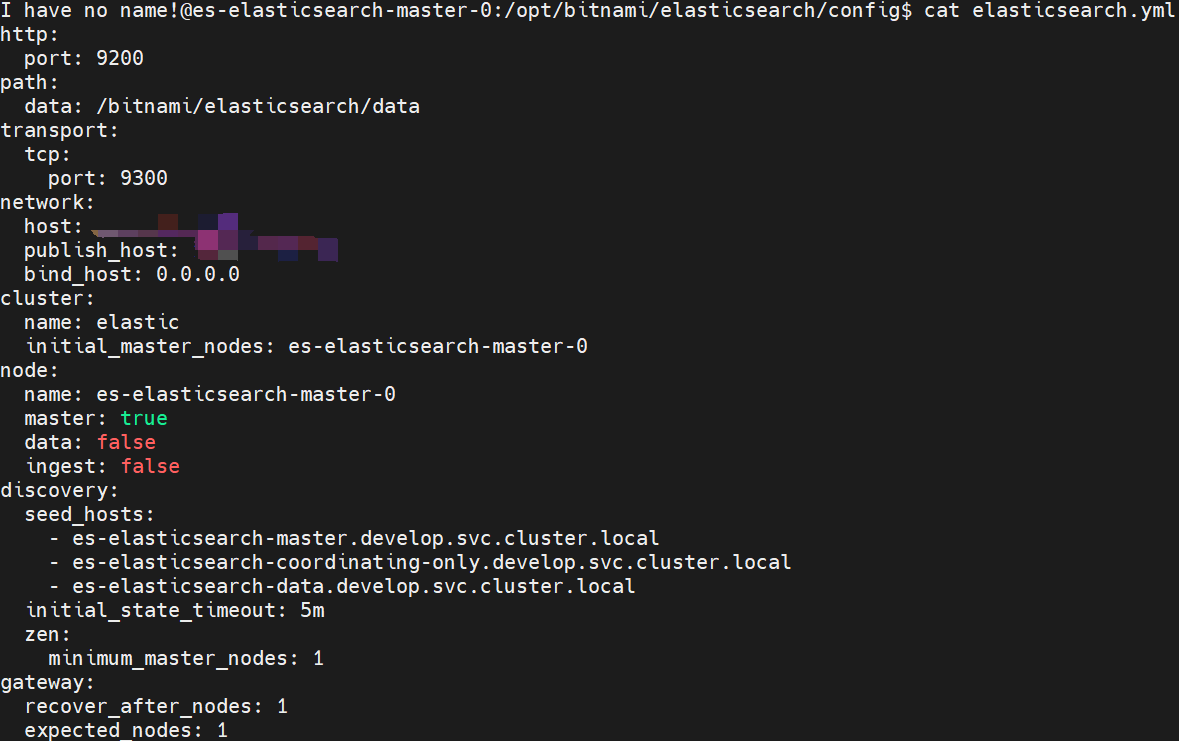
保存配置文件为es-cm.yml,并修改network中的host为pod的ip地址,手动保存配置文件的话不能固定ip,所以需要用环境变量注入。
es-cm.yaml
http:
port: 9200
path:
data: /bitnami/elasticsearch/data
transport:
tcp:
port: 9300
network:
host: ${NETWORK_PUBLISH_HOST}
publish_host: ${NETWORK_PUBLISH_HOST}
bind_host: 0.0.0.0
cluster:
name: elastic
initial_master_nodes: es-elasticsearch-master-0
node:
name: es-elasticsearch-master-0
master: true
data: false
ingest: false
discovery:
seed_hosts:
- es-elasticsearch-master.develop.svc.cluster.local
- es-elasticsearch-coordinating-only.develop.svc.cluster.local
- es-elasticsearch-data.develop.svc.cluster.local
initial_state_timeout: 5m
zen:
minimum_master_nodes: 1
gateway:
recover_after_nodes: 1
expected_nodes: 1
# 添加白名单
reindex.remote.whitelist: ["1.2.3.4:9200"]创建cm:
k create cm es-master-config -n test --from-file=elasticsearch.yml=./es-cm.yml修改statefulset,添加环境变量和挂载configmap配置文件。
containers:
- env:
- name: NODE_NAME
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: metadata.name
- name: NETWORK_PUBLISH_HOST
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: status.podIP
- name: ELASTICSEARCH_PUBLISH_HOST
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: status.podIP
- name: ELASTICSEARCH_BIND_HOST
value: 0.0.0.0
- name: ELASTICSEARCH_TRANSPORT_PUBLISH_HOST
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: status.podIP
volumeMounts:
- mountPath: /bitnami/elasticsearch/data
name: data
- mountPath: /opt/bitnami/elasticsearch/config/elasticsearch.yml
name: config
subPath: elasticsearch.yml
volumes:
- configMap:
defaultMode: 420
name: es-master-config
name: configpod启动后,查看配置文件已更新。
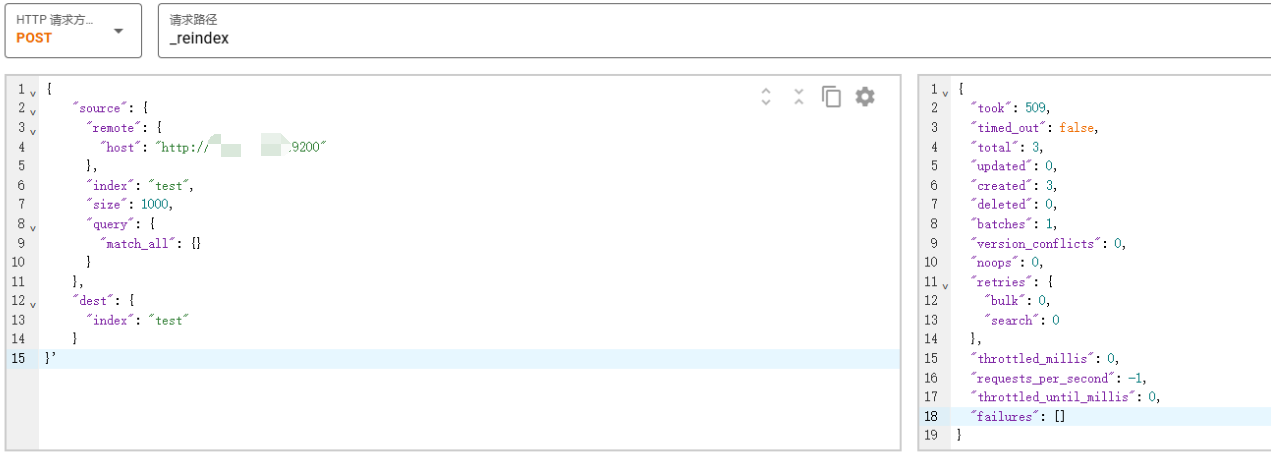
在环境2 es中执行命令:把环境1 es的test index同步到环境2 es的test index。
POST:_reindex
{
"source": {
"remote": {
"host": "http://1.2.3.4:9200"
},
"index": "test",
"size": 1000,
"query": {
"match_all": {}
}
},
"dest": {
"index": "test"
}
}'
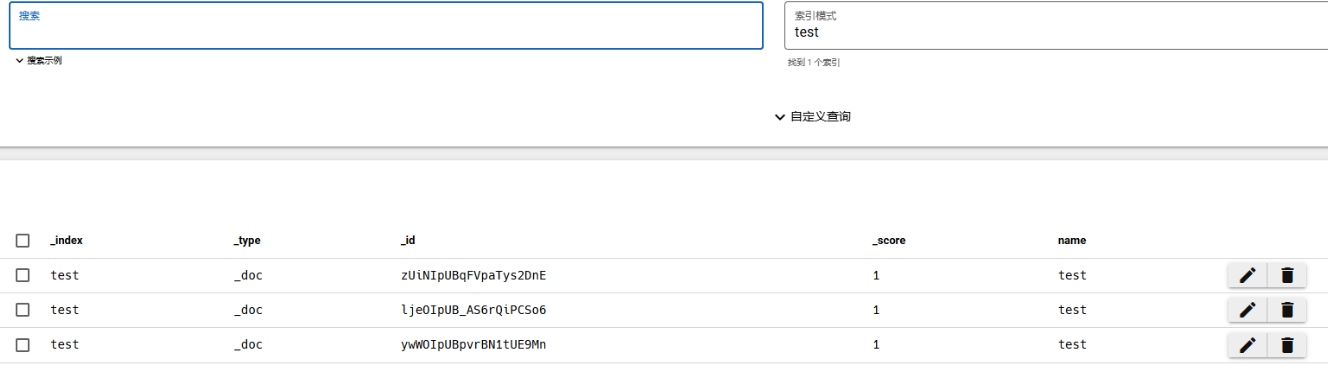
命令执行成功,查看test index,同步成功。
断点续传和执行超时问题
假如test index数量有50万,如果直接执行的话:
- 耗时:耗时取决于文档大小、网络带宽、源集群和目标集群的读写性能。假设每个文档1KB,50万条数据就是约500MB。即使网络和集群性能良好,这个过程也需要数分钟甚至更长时间。
- 超时:无论是客户端(如Kibana Dev Tools、curl)还是Elasticsearch服务器端都有默认的超时设置。一个HTTP请求长时间不返回,客户端会提前断开连接,导致任务失败。
- 断点续传:原生的 _reindex API 本身不提供简单的“断点续传”功能。如果任务在运行了80%后失败,重新执行上述命令会从头开始,而不是从80%继续。
解决方案:异步任务与切片
https://www.elastic.co/docs/reference/elasticsearch/rest-apis/reindex-indices
方案一:异步执行(基础方案)
最简单的改进是使用 wait_for_completion=false 参数让 reindex 任务在后台异步执行。这样客户端提交请求后会立即返回一个任务ID,而不是等待任务完成。
POST:_reindex?wait_for_completion=false {
"source": {
"remote": {
"host": "http://1.2.3.4:9200"
},
"index": "test",
"size": 1000,
"query": {
"match_all": {}
}
},
"dest": {
"index": "test"
}
}'
返回:
{
"task" : "aBcDeFgH:iJkLmNoPqRsTuVwXyZ"
}- 优点:解决了客户端超时问题。
- 缺点:如果任务本身在服务器端执行失败(例如网络抖动),仍然需要全量重试。
方案二:异步 + 切片(推荐的最佳方案)
这是处理大量数据最可靠、最快速的方法。slices 参数会将一个大的 reindex 任务自动拆分成多个并行执行的子任务。
工作原理:
- 拆分:根据切片数(如 slices: 5),将数据拆分成多个“片”。
- 并行:每个切片独立地从源索引读取数据并写入目标索引。
- 容错:单个切片失败不会影响其他切片。重试时只需重试失败的切片即可(通过任务API管理),实现了“类断点续传”的功能。
POST _reindex?wait_for_completion=false
{
"source": {
"remote": {
"host": "http://10.0.10.169:9200"
},
"index": "test",
"size": 1000, // 每次scroll请求的大小,可根据网络调整
"slices": 5 // 核心参数:设置切片数量
},
"dest": {
"index": "test"
}
}
返回
{
"task" : "aBcDeFgH:iJkLmNoPqRsTuVwXyZ"
}如何设置 slices 数量?
- 推荐值:设置为源索引的主分片数量。这是最有效的拆分方式。
- 查询主分片数:
GET test/_settings?filter_path=**.number_of_shards - 最大值:可以设置得比主分片数多,但收益会递减。通常不建议超过 10。
优点:
- 大幅提升速度:多个切片并行工作,充分利用集群资源和网络带宽。
- 增强可靠性:局部失败只需重试局部,避免了全量重试的浪费。
- 易于监控和管理:可以通过任务API监控每个子切片的进度。
处理失败:
- 如果整个任务或某个切片失败,响应中会包含失败信息。
- 你可以选择重试整个任务,或者更精细地重试失败的特定切片(这需要更底层的操作,通常直接重试整个任务更简单,但因为用了切片,重试速度也很快)。
验证数据完整性:
任务显示完成后,检查两个索引的文档数是否一致。
GET test/_count
GET source_index/_count # 在源集群上执行