背景
下面我将以这个思维导图来总结一下CNI。
简介
Kubernetes 网络模型设计的基础原则是:
- 所有的 Pod 能够不通过 NAT 就能相互访问。
- 所有的节点能够不通过 NAT 就能相互访问。
- 容器内看见的1P 地址和外部组件看到的容器 IP 是一样的。
Kubernetes 的集群里,ip地址是以 Pod 为单位进行分配的,每个 Pod 都拥有一个独立的ip地址。一个 Pod 内部的所有容器共享一个网络栈,即宿主机上的一个网络命名空间,包括它们的ip地址、网络设备、配置等都是共享的。
也就是说,Pod 里面的所有容器能通过 localhost:port 来连接对方。在 Kubernetes 中,提供了一个轻量的通用容器网络接口 CNI (Container Network Interface),专门用于设置和删除容器的网络连通性。容器运行时通过 CNI 调用网络插件来完成容器的网络设置。
分类
- IPAM:IP 地址分配
- 主插件:网卡设置
- bridge:创建一个网桥,并把主机端口和容器端口插入网桥
- ipvlan:为容器添加 ipvlan 网口
- loopback:设置 loopback 网口
- Meta:附加功能
- portmap:设置主机端口和容器端口映射
- bandwidth:利用 Linux Traffic Control 限流
- firewall:通过 iptables 或 firewalld 为容器设置防火墙规则
运行机制
CNI是由container runtime直接从 CNI 的配置目录中读取 JSON 格式的可执行文件,文件后缀为".conf" ".conflist" 〞json〞。如果配置目录中包含多个文件,一般情况下,会以名字排序选用第一个配置文件作为默认的网络配置,并加载获取其中指定的 CNI 插件名称和配置参数。
对于容器网络管理,容器运行时一般需要配置两个参数–cni-bin-dir 和–cni-conf-dir。有一种特殊情况,kubelet 使用 Docker 作为容器运行时,是由 kubelet 来查找 CNI 插件的,运行插件来为容器设置网络,这两个参数应该配置在 kubelet 处:
- cni-bin-dir:网络插件的可执行文件所在目录。默认是 /opt/cni/bin。

- cni-conf-dir:网络插件的配置文件所在目录。默认是 /etc/cni/net.d。


插件设计考量
- 容器运行时必须在调用任何插件之前为容器创建一个新的网络命名空间。
- 容器运行时必须决定这个容器属于哪些网络,针对每个网络,哪些插件必须要执行。
- 容器运行时必须加载配置文件,并确定设置网络时哪些插件必须被执行。
- 网络配置采用JSON 格式,可以很容易地存储在文件中。
- 容器运行时必须按顺序执行配置文件里相应的插件。
- 在完成容器生命周期后,容器运行时必须按照与执行添加容器相反的顺序执行插件,以便将容器与网络断开连接。
- 容器运行时被同一容器调用时不能并行操作,但被不同的容器调用时,允许并行操作。
- 容器运行时针对一个容器必须按顺序执行 ADD 和 DEL 操作,ADD 后面总是跟着相应的 DEL。DEL 可能跟着额外的 DEL,插件应该允许处理多个 DEL。
- 容器必须由 ContainerID 来唯一标识,需要存储状态的插件需要使用网络名称、容器ID 和网络接口组成的主key 用于索引。
- 容器运行时针对同一个网络、同一个容器、同一个网络接口,不能连续调用两次ADD 命令。
CNI plugin
ContainerNetworking 组维护了一些 CNI 插件,包括网络接口创建的 bridge、 ipvlan、 loopback、macvlan、 ptp、 host-device 等,P 地址分配的 DHCP、 host-local 和 static,其他的Flannel、tunning、 portmap、 firewall等。
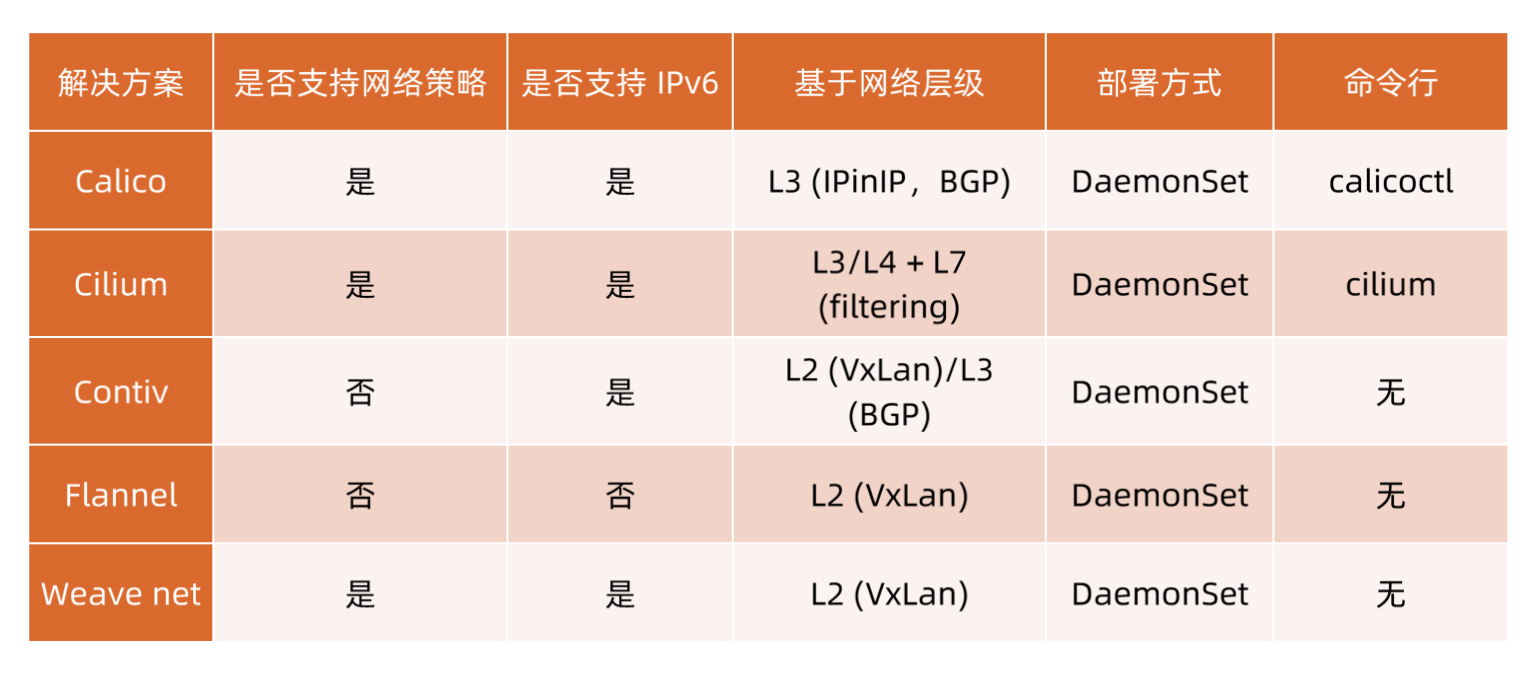
社区还有些第三方网络策略方面的插件,例如 Calico、Cilium 和 Weave 等。
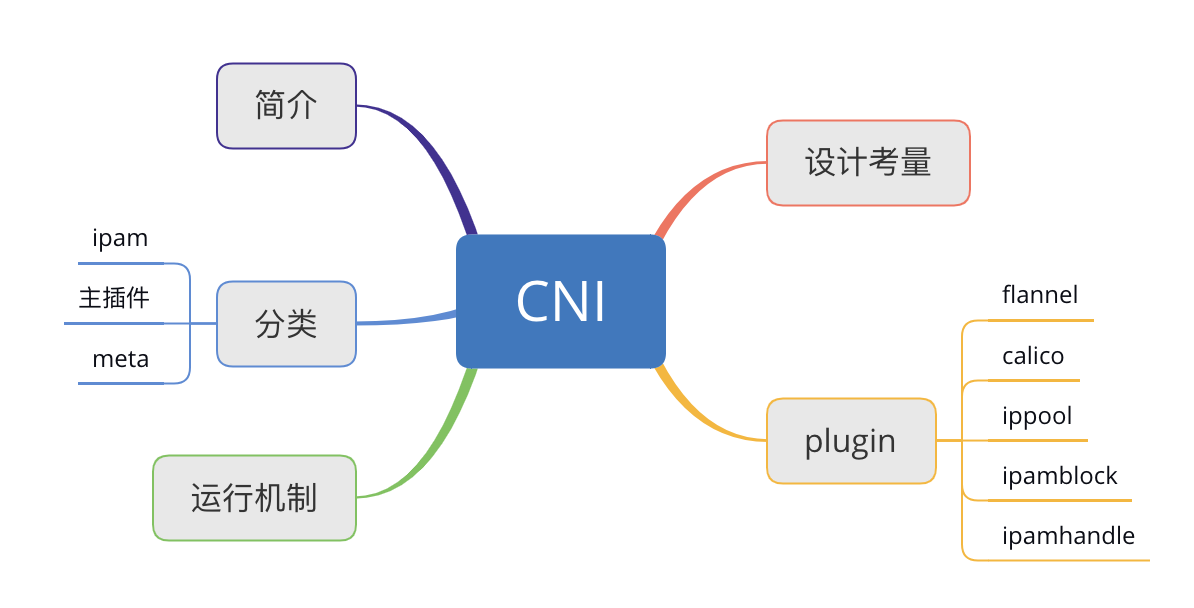
Flannel
Flannel 是由 Coreos 开发的项目,是 CNI 插件早期的入门产品,简单易用。
Flannel 使用 Kubernetes 集群的现有 etcd 集群来存储其状态信息,从而不必提供专用的数据存储,只需要在每个节点上通过daemonset运行 flanneld 来守护进程。
每个节点都被分配一个子网,为该节点上的 Pod 分配|P 地址。
同一主机内的Pod 可以使用网桥进行通信,而不同主机上的 Pod 将通过 flanneld 将其流量封装在UDP 数据包中。
由于要经过vxlan加封和解封装,所以它的效率不是很高。
原理
flanneld会在每个节点上启动一个vxlan设备,所有的请求都会经过这个设备封装。在原始的tcp包加上一个vxlan的udp的包头,外层udp的源地址就变成了node的地址,这样就可以跨主机通信了。
calico
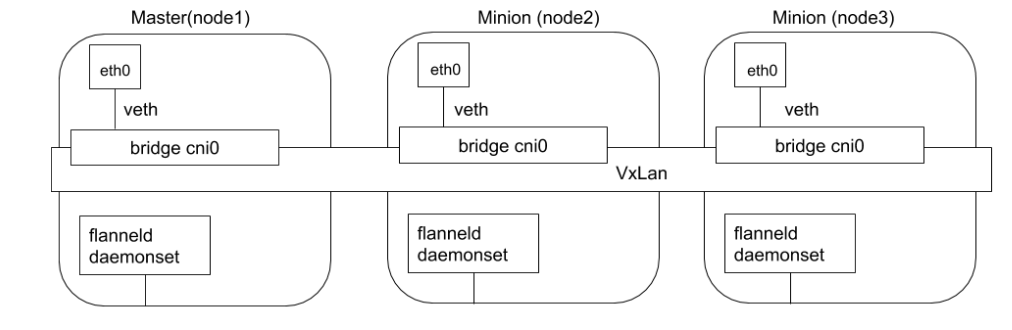
Calico 以其性能、灵活性和网络策略而闻名,不仅涉及在主机和 Pod 之间提供网络连接,而且还涉及网络安全性和策略管理。
对于同网段通信,基于第3层,Calico 使用 BGP路由协议在主机之间通信,使用 BGP 意味着数据包在主机之间移动时不需要额外的封装。
对于跨网段通信,基于IPinIIP 使用虚拟网卡设备 tunl0,用一个 IP 数据包封装另一个 IP 数据包,外层 IP 数据包头的源地址为隧道入口设备的 IP 地址,目标地址为隧道出口设备的IP 地址。
网络策略是 Calico 最受欢迎的功能之一,使用 ACLS 协议和 kube-proxy 来创建 iptables 过滤规则,从而实现隔离容器网络的目的。
此外,Calico 还可以与服务网格 Istio 集成,在服务网格层和网络基础结构层上解释和实施集群中工作负载的策略。这意味着你可以配置功能强大的规则,以描述 Pod 应该如何发送和接收流量,提高安全性及加强对网络环境的控制。
原理
calico也是以daemonset运行在node上。felix agent是配置防火墙规则的;bird是做路由交换的,进程启动后node可以模拟成一个路由器,这样就可以通过路由协议进行通信;confd是做配置推送的。
查看bird配置
即查看bgp的配置。
k exec -it calico-node-9lv4g -n calico-system cat /etc/calico/confd/config/bird.cfg
calico vxlan
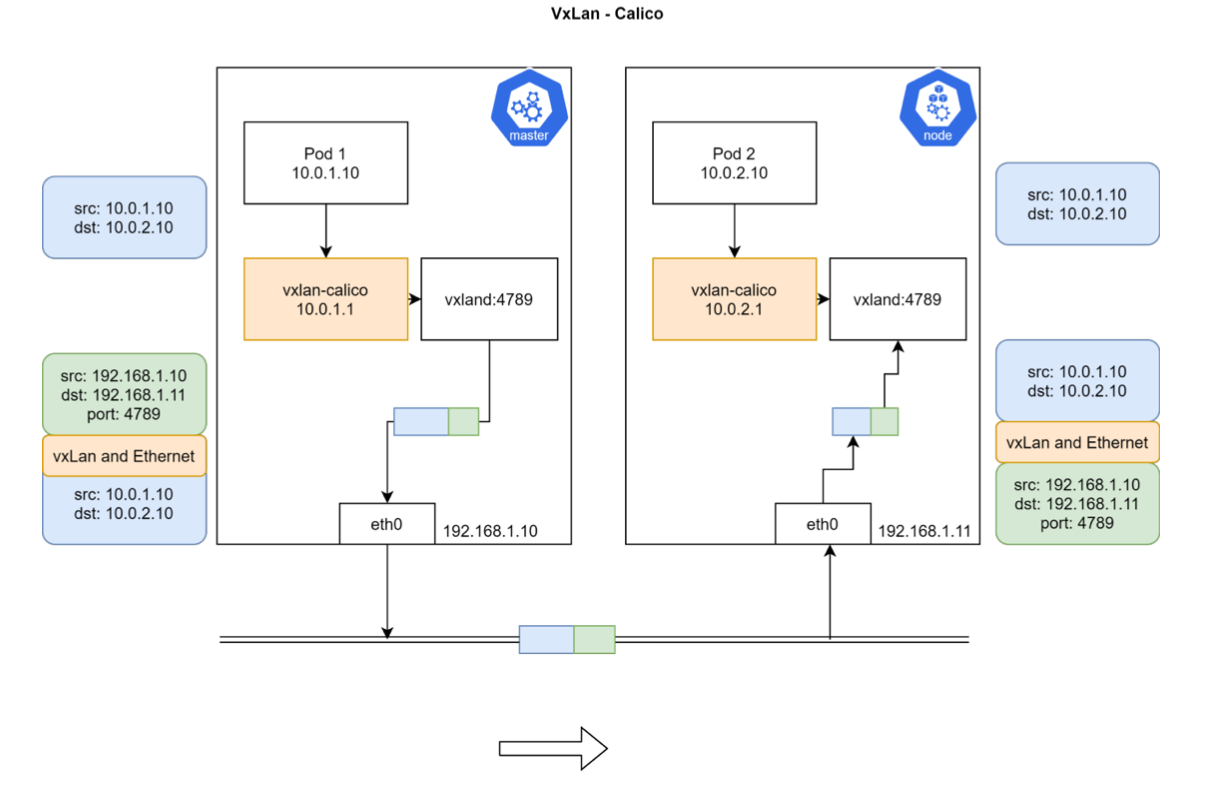
calico 初始化
查看calico-node部署情况
k get po -n calico-system
k get ds -n calico-system
查看calico-node的ds
k get ds calico-node -n calico-system可以看到calico-node有initcontainer,容器命令是/opt/cni/bin/install,配置了volume,通过hostpath的方式把cni插件和配置文件mount到容器中。同时,这些文件是构建在镜像中的,calico-node容器启动时就会把这些文件拷贝到主机上,这样containerd就能调用cni插件了。
initcontainers
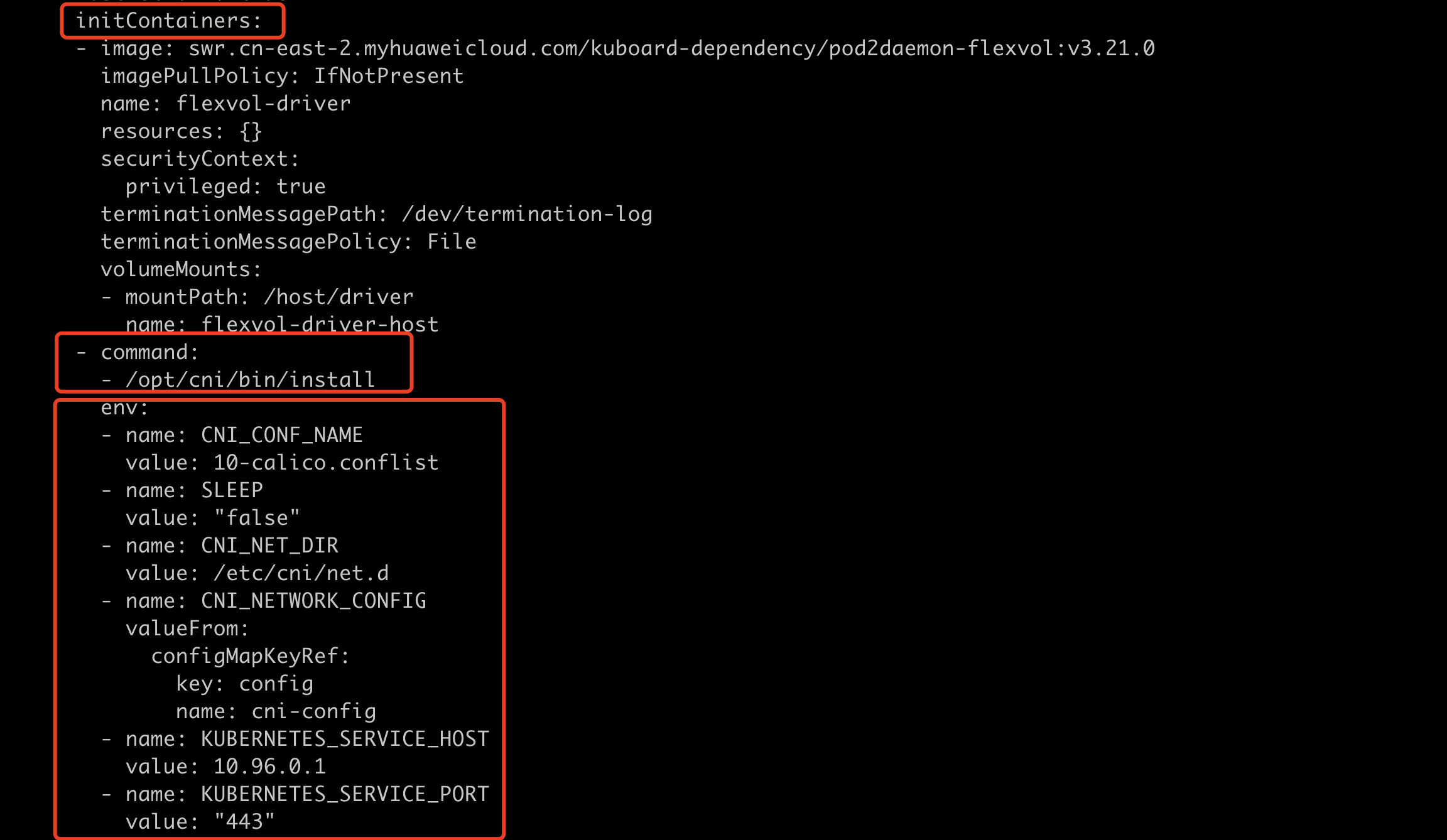
volumeMounts
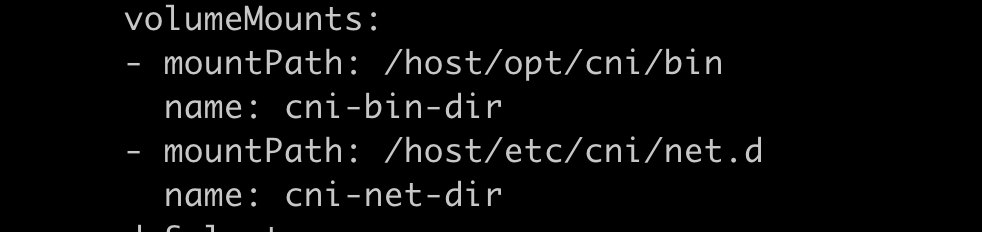
volume
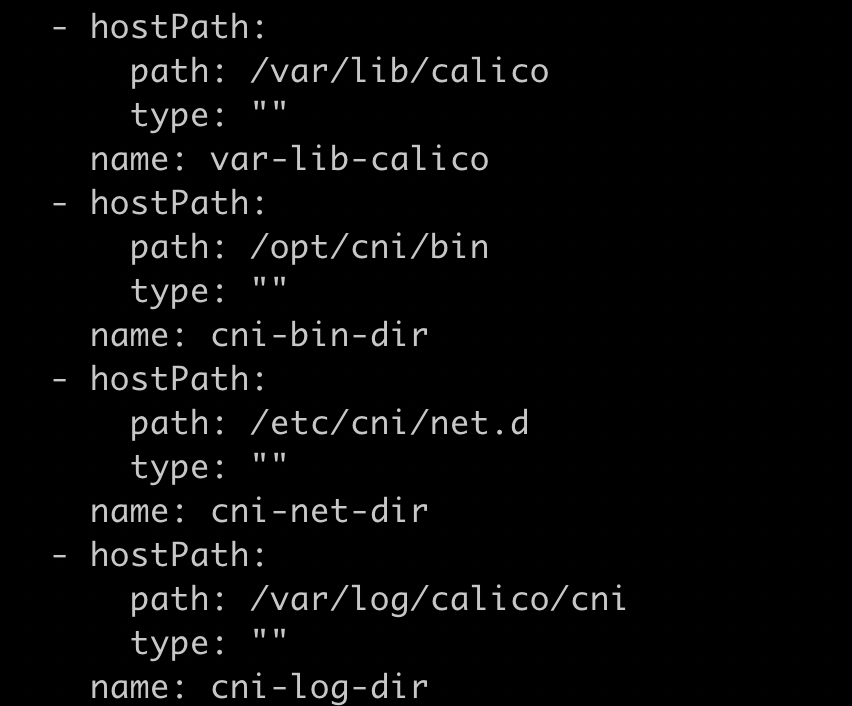
calico配置文件
cd /etc/cni/net.d/
cat 10-calico.conflist
{
"name": "k8s-pod-network",
"cniVersion": "0.3.1", # CNI的版本
"plugins": [ # plugin列表
{
"type": "calico", # plugin类型,主插件
"datastore_type": "kubernetes",
"mtu": 0,
"nodename_file_optional": false,
"log_level": "Info",
"log_file_path": "/var/log/calico/cni/cni.log",
"ipam": { "type": "calico-ipam", "assign_ipv4" : "true", "assign_ipv6" : "false"}, # ipam类型calico-ipam
"container_settings": {
"allow_ip_forwarding": false
},
"policy": {
"type": "k8s"
},
"kubernetes": { # calico要和apiserver通信
"k8s_api_root":"https://10.96.0.1:443",
"kubeconfig": "/etc/cni/net.d/calico-kubeconfig"
}
},
{
"type": "bandwidth", # meta plugin,开启限流
"capabilities": {"bandwidth": true}
},
{"type": "portmap", "snat": true, "capabilities": {"portMappings": true}}
]
}crd
k get crd | grep calico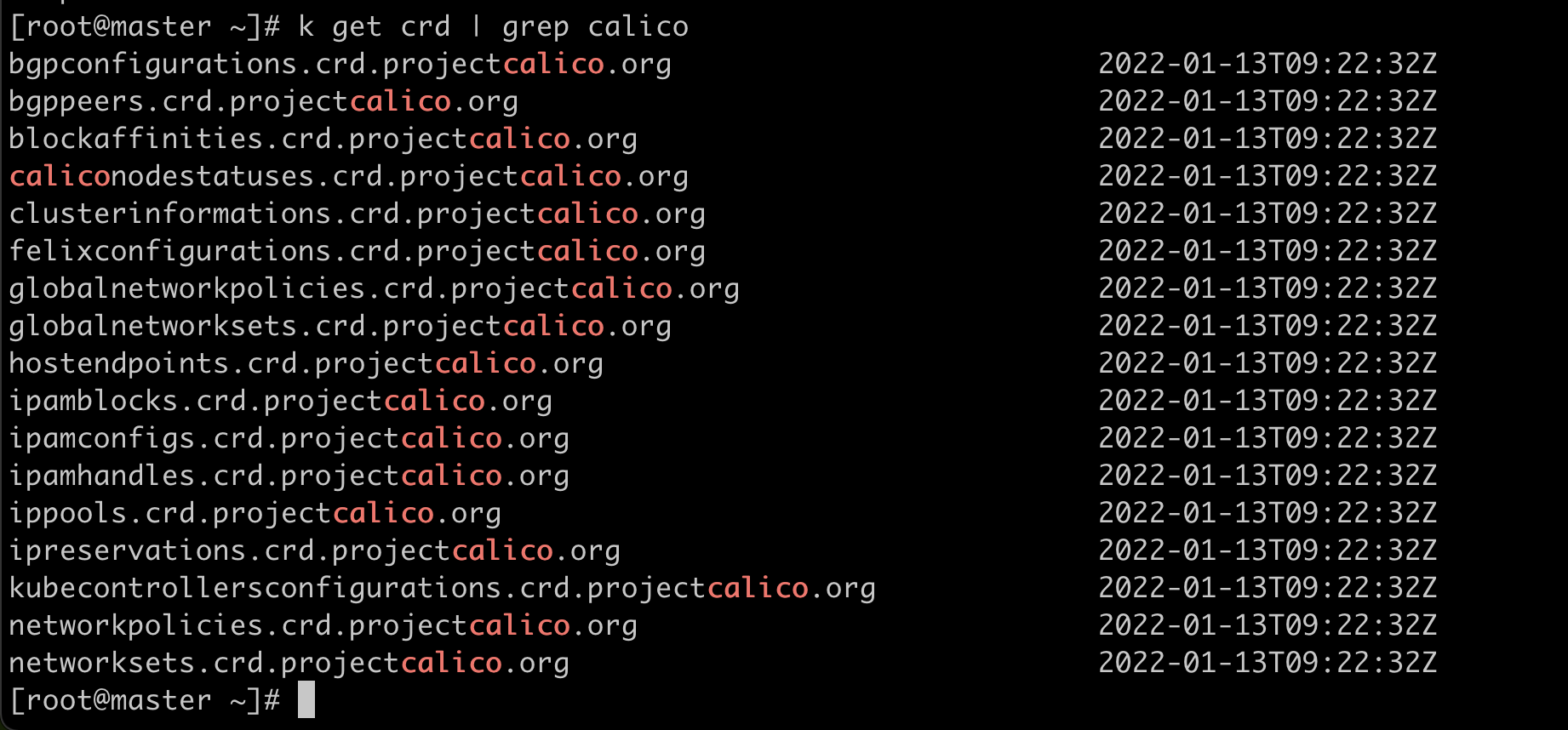
IPPool
IPPool 用来定义集群的IP地址段。
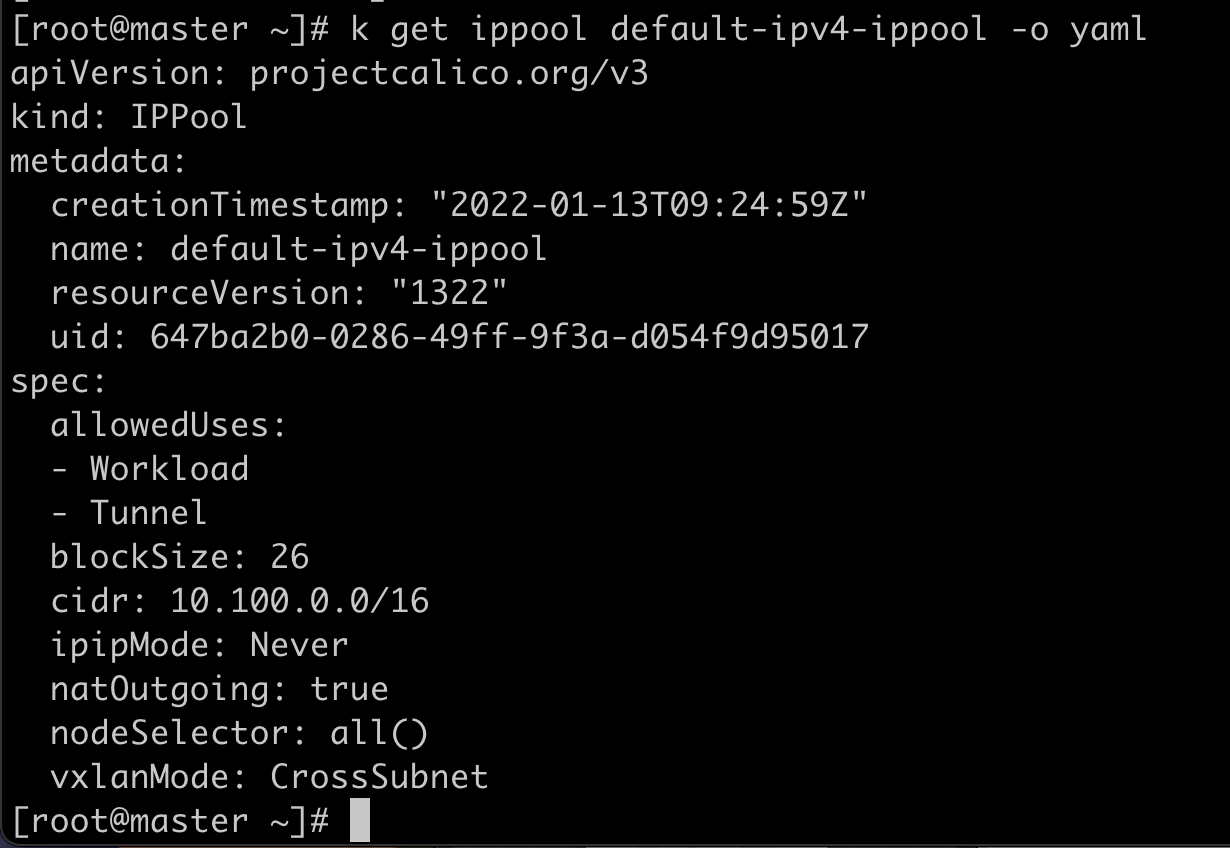
也可以用calicoctl来查看。
calicoctl get ipPool --allow-version-mismatch
calicoctl ipam show --allow-version-mismatch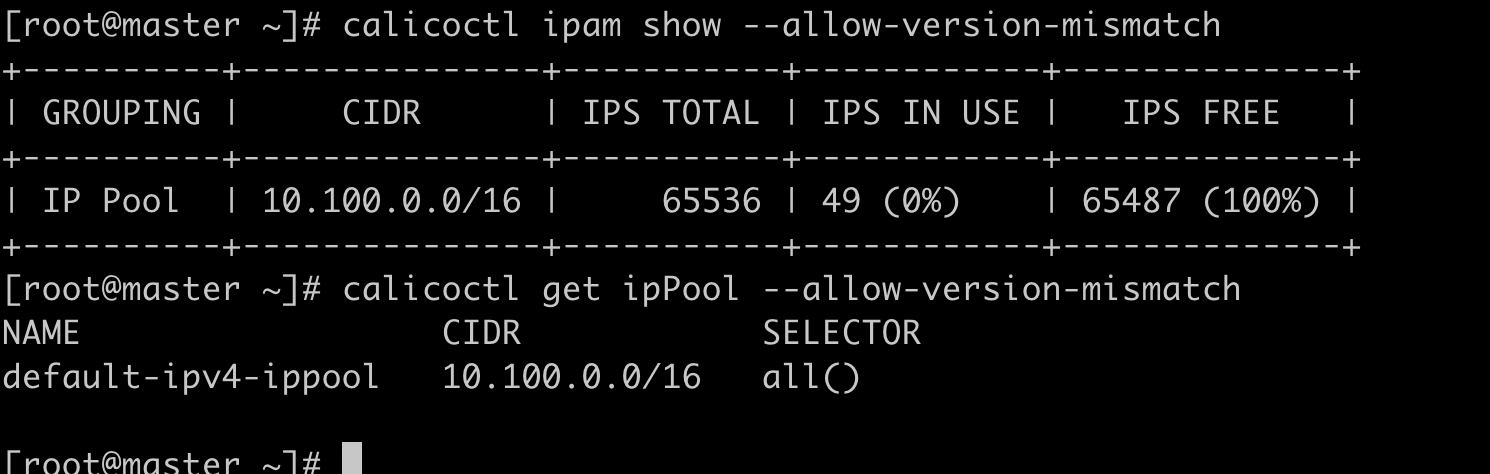
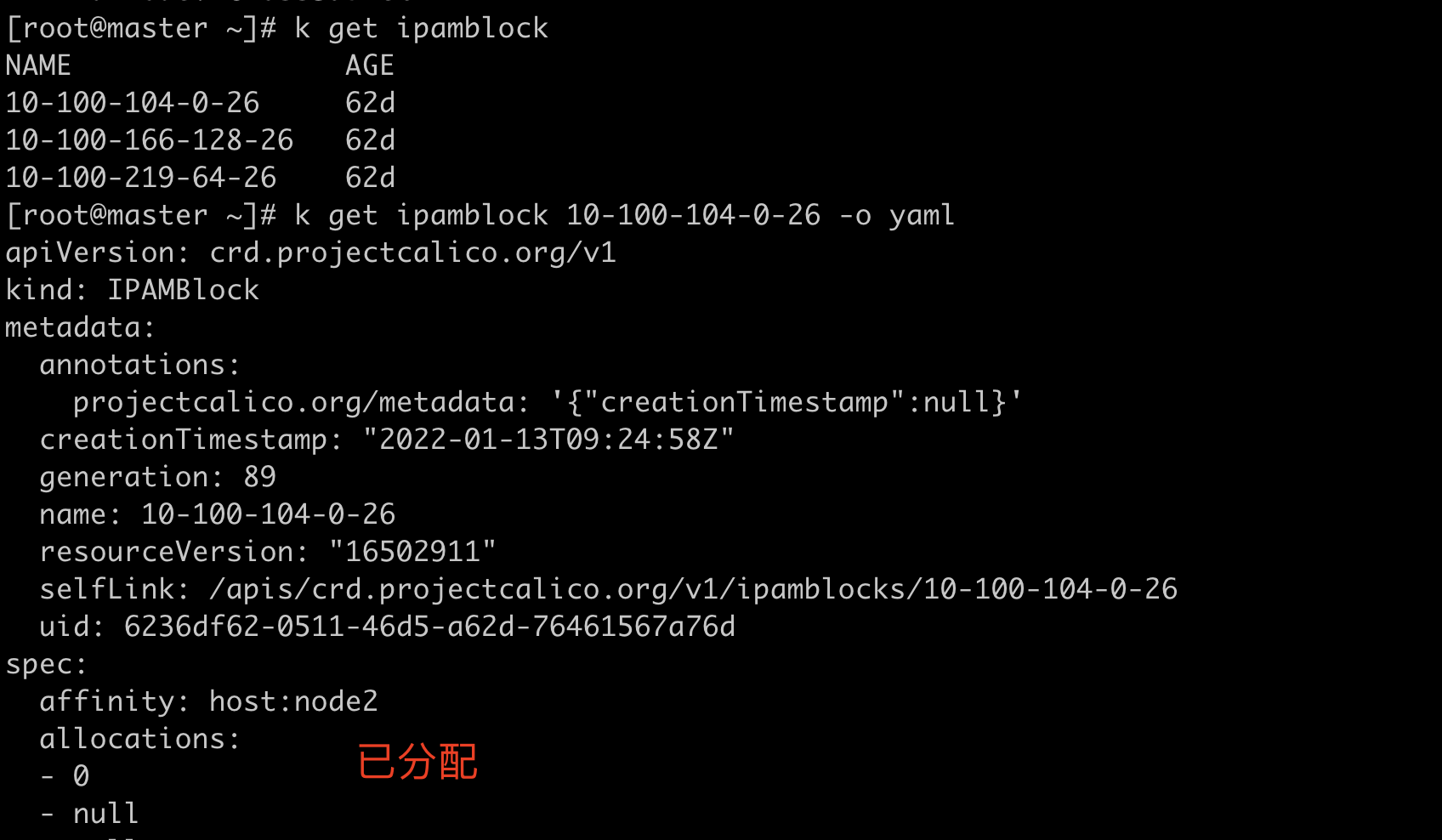
IPAMBlock
IPAMBlock 用来定义每个主机预分配的IP段。
affinity表明是哪个node。这样路由的时候calico就知道往哪个node上转发,即calico知道下一跳是哪个node。
handle_id和secondry表明是哪个pod。
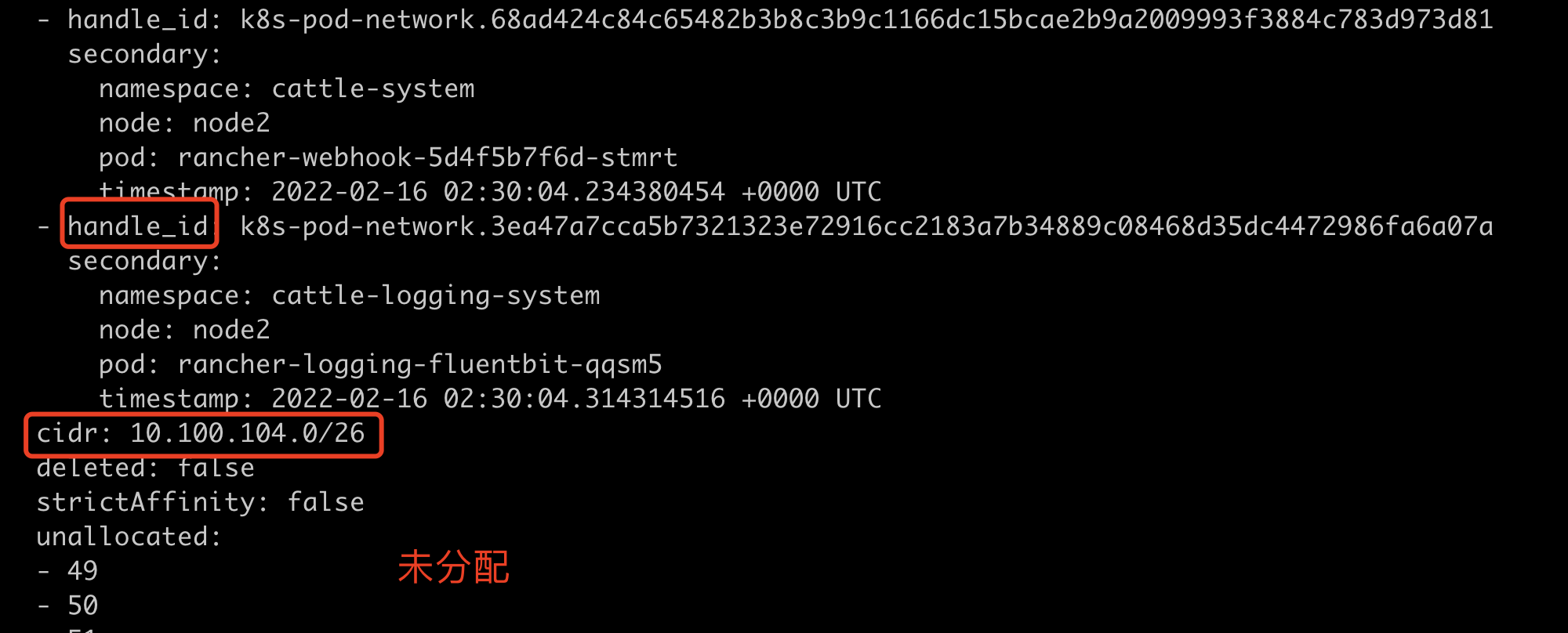
IPAMHandle
IPAMHandle 用来记录IP分配的具体细节。
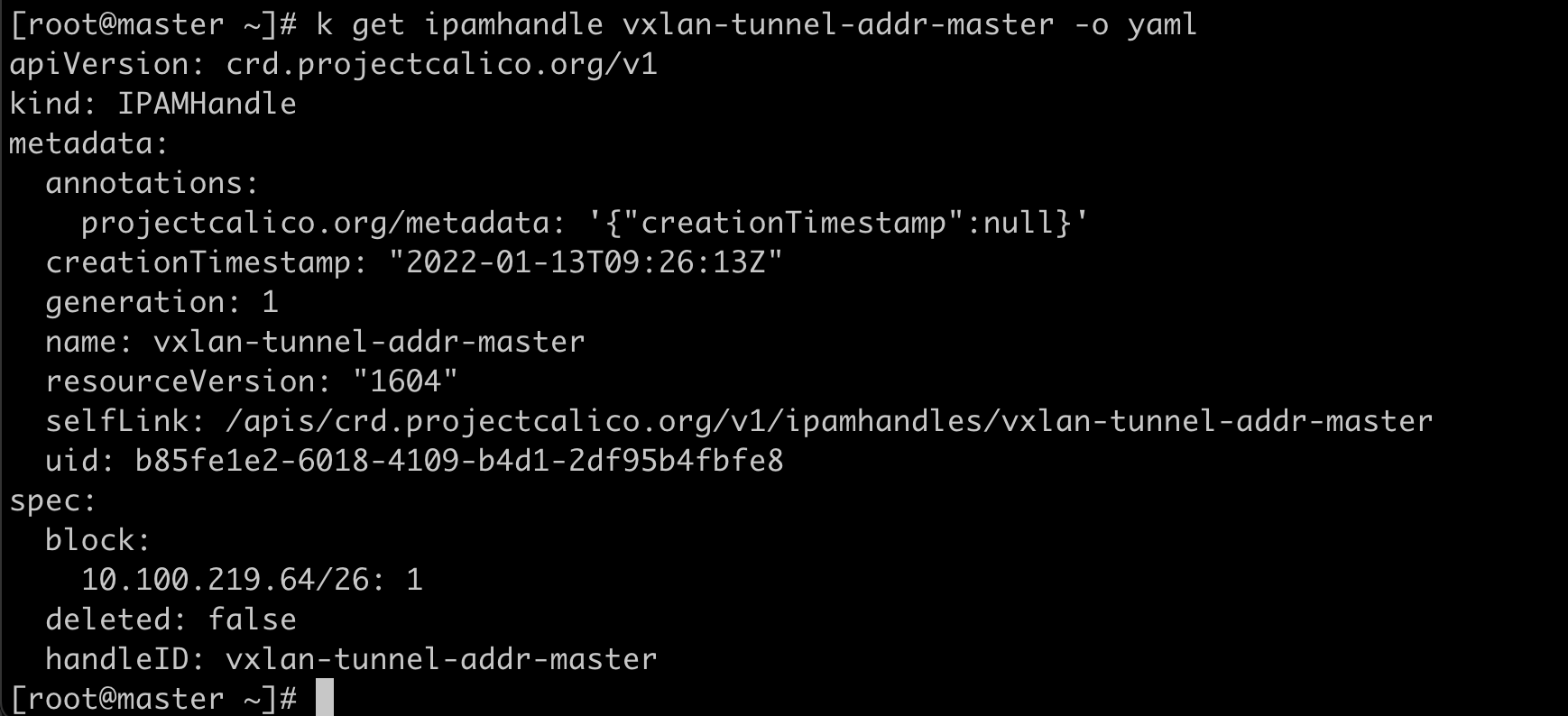
CNI插件对比
大型集群,calico的BGP可以采用 RR模式(route reflector)路由反射器模式,即多个节点上报给一个主节点,然后多个主节点之间组成一个mesh网络进行通信。
实践
创建pod,并查看ip分配情况。
k get po
查看nginx进程的pid
crictl ps | grep nginx
crictl inspect 5ed0e8a0350fb | grep pid
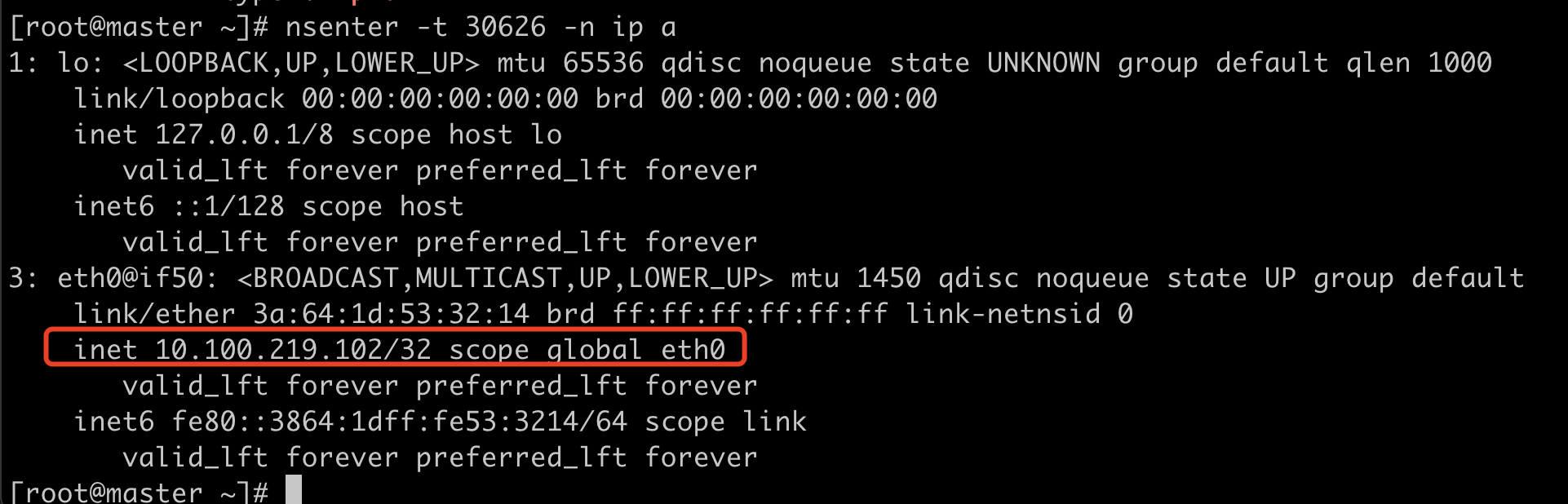
进入pid的网络namespace
nsenter -t 30626 -n ip a可以看到有2个网卡,lo网卡就是/opt/cni/bin/loopback配置的,eth0@if50网卡就是calico配置的。
查看容器内的路由
nsenter -t 30626 -n ip route可以看到默认路由下一跳通过eth0发送到169.254.1.1。

查看169.254.1.1设备信息
nsenter -t 30626 -n arping 169.254.1.1可以看到169.254.1.1和 [EE:EE:EE:EE:EE:EE] 这个mac地址绑定。

查看主机网卡信息
ip a可以看到所有cali开头的网卡的mac地址都是ee:ee:ee:ee:ee:ee。
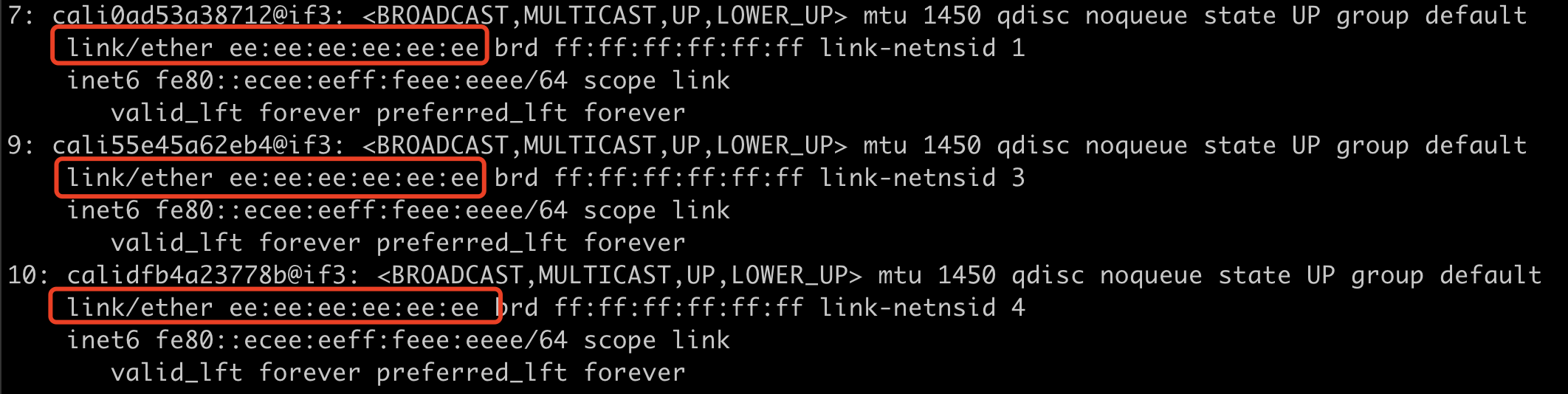
无论calico运行在哪种模式,容器内都是通过eth0和外部的cali网卡进行通信的。这样容器内部的任何请求都会被外部的cali网卡处理。也就是容器内部的默认路由都是虚拟的,就是外部的veth-pair口。