背景
下面我将以这个思维导图来总结一下kube-scheduler。
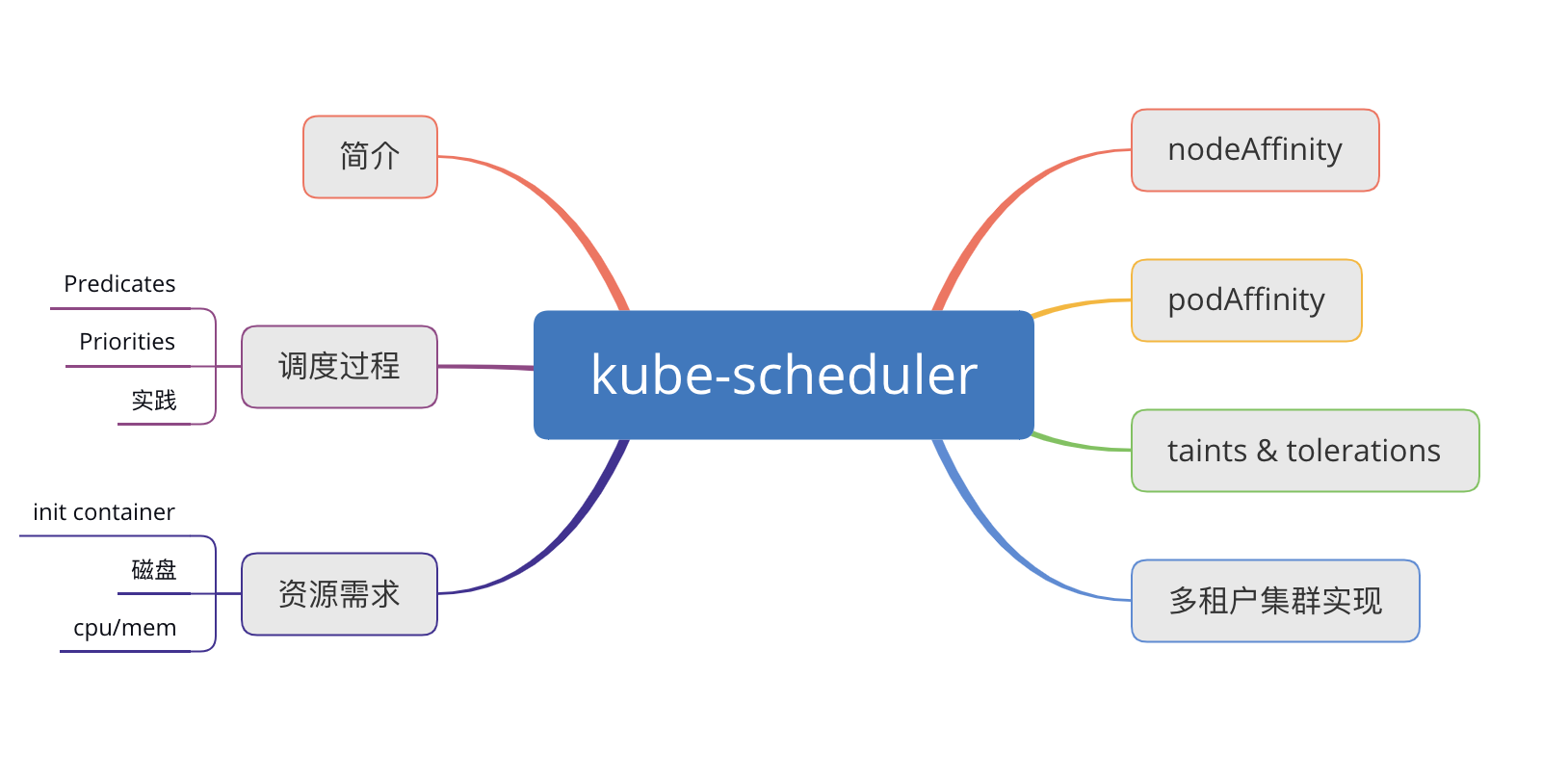
简介
kube-scheduler 负责把 pod 调度到node上,它监听 kube-apiserver,查询node的健康,资源状况,然后根据调度策略为这些 Pod 分配节点(更新 pod 的 NodeName 字段)。
kube-scheduler 会有集群所有节点的计算资源的全局视图,也会读取pod的配置信息。
调度器需要充分考虑诸多的因素:
- 公平调度:同一优先级会公平,高的优先级也可以插队(见下方优先级调度)
- 资源高效利用:用户申请资源时都会超量申请
- Qos:支持超卖,满足pod的基本需求
- affinity 和 anti-affinity
- 数据本地化 (data locality):pod所需的镜像在别的node上已经存在了,就可以直接调度到这个node上,节省磁盘资源。
- 内部负载干扰 (inter-workload interference)
- deadlines。
调度过程
kube-scheduler 调度分为两个阶段,predicate 和 priority:
- predicate:过滤不符合条件的节点;(filter)
- priority:优先级排序,选择优先级最高的节点。(score)
predicate


当然也可以编写自己的策略。
工作原理
当pod在调度的时候,就会遍历调度插件,最后得到一个或者多个符合要求的node,谁最合适,就需要下面的priority。
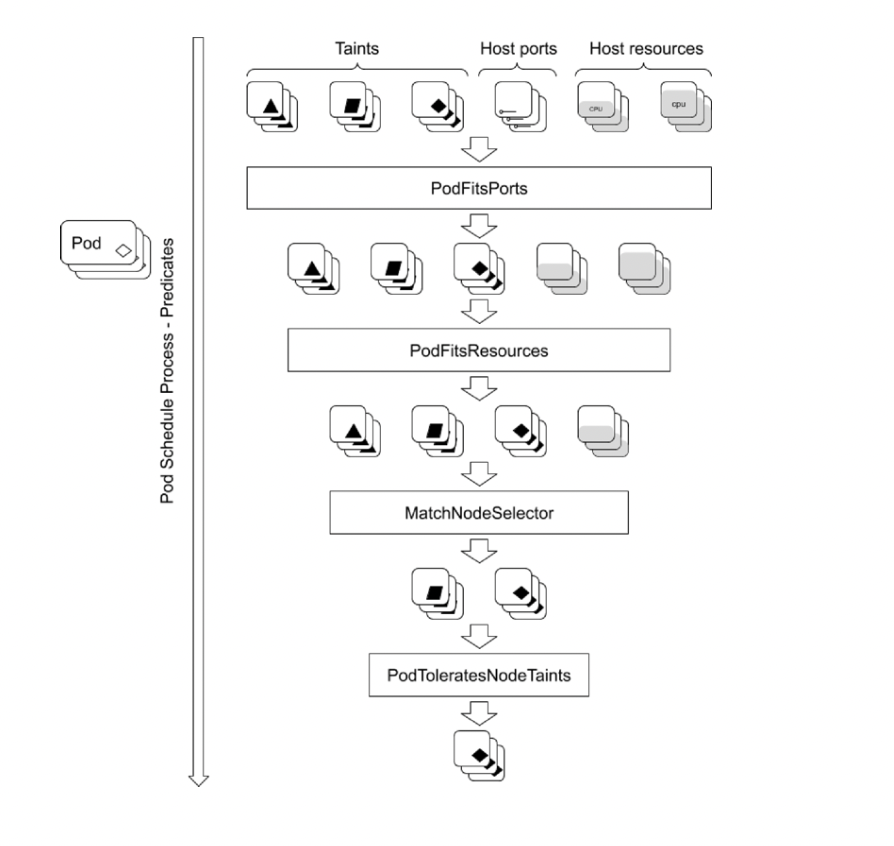
priority


资源需求
cpu/mem
CPU
- requests
Kubernetes 调度 Pod 时,会判断当前节点正在运行的 Pod 的 CPU Request 的总和,再加上当前调度 Pod 的 CPU request,计算其是否超过节点的 CPU 的可分配资源。最小资源。m是cpu的单位,1000m就是1个cpu。 - limits
配置 cgroup 以限制资源上限。实际需求资源和cgroup中的limits资源不一致,就达到了超卖的效果。比如机器有4个cpu,如果按照limits去调度只能调度4个pod,但是如果按照reques 100m调度就可以调度40个pod。
内存
- requests
判断节点的剩余内存是否满足 Pod 的内存请求量,以确定是否可以将 Pod 调度到该节点。 - limits
配置 cgroup 以限制资源上限。
实践
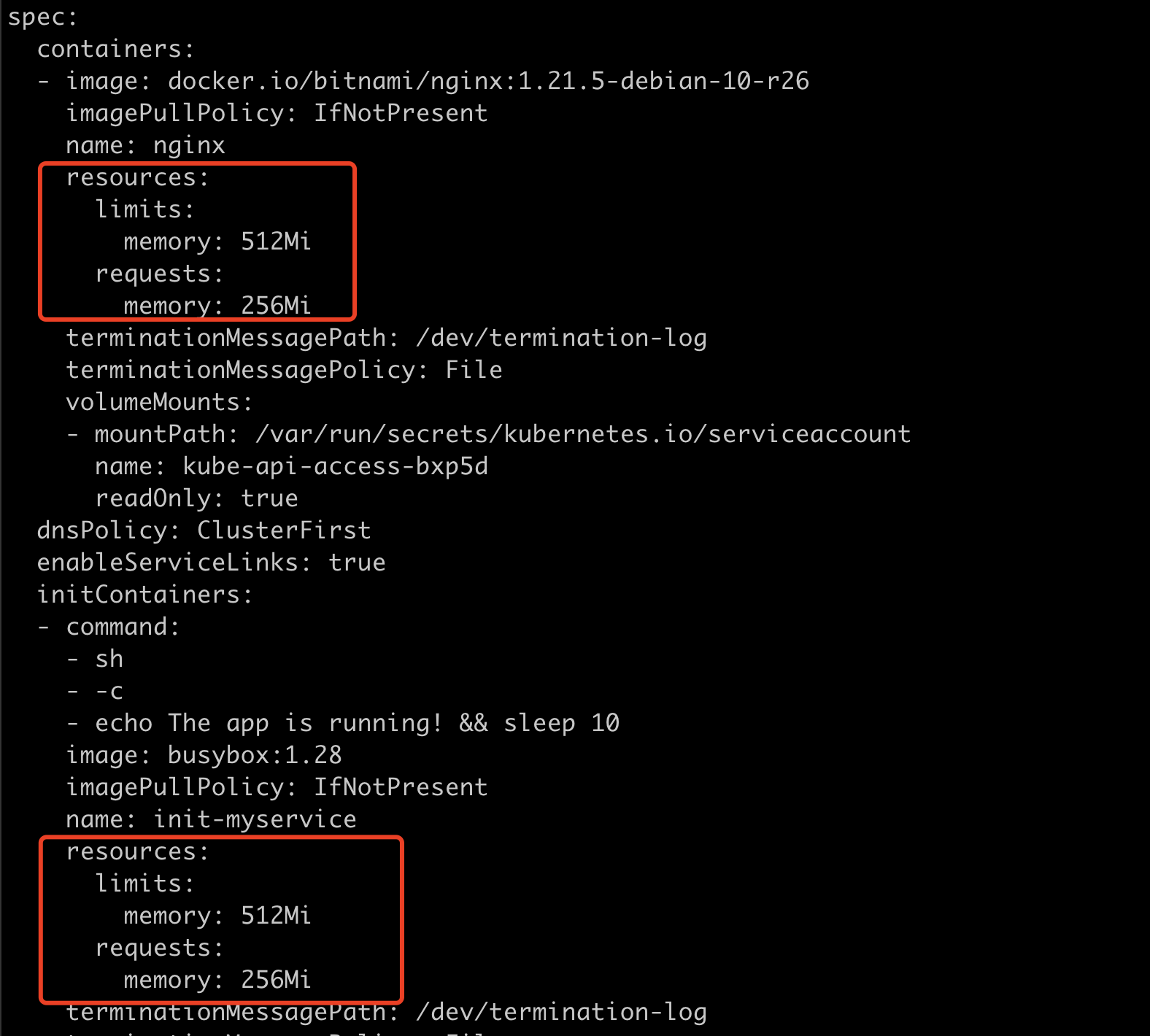
部署nginx-deployment,添加resources的limits和requests。
cat nginx-deploy.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
resources:
limits:
memory: 1Gi
cpu: 1
requests:
memory: 256Mi
cpu: 100m
k apply -f nginx-deploy.yaml
k get po -o yaml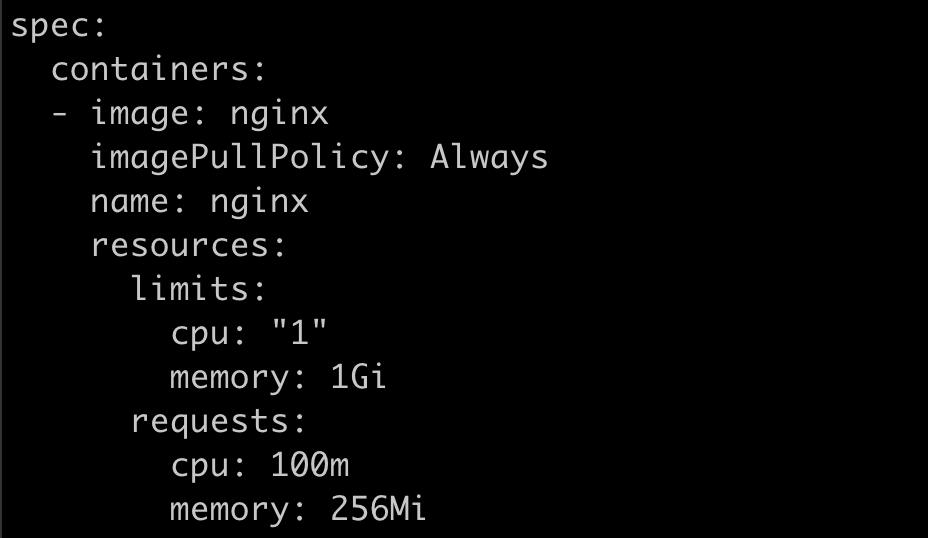
修改yaml中requests和limits的cpu为100。查看pod处于pending状态。

查看报错原因是没有足够的cpu。

磁盘
容器临时存储 (ephemeral storage) 包含日志和可写层数据,可以通过定义 Pod Spec 中的 limits.ephemeral-storage 和 requests.ephemeral-storage 来申请。
Pod 调度完成后,计算节点对临时存储的限制不是基于 cgroup 的,而是由 kubelet 定时获取容器的日志和容器可写层的磁盘使用情况,如果超过限制,则会对 Pod 进行驱逐。
init container
init容器在主容器前运行,负责完成一些初始化工作。比如istio中就会负责完成iptables的配置;主容器需要认证token,init容器就会去获取token然后保存到本地目录,再把volume挂载到主容器,这样主容器就可以使用这个token了。
当 kube-scheduler 调度带有多个 init 容器的 Pod 时,只计算 cpu.request 最多的 init 容器,而不是计算所有的 init 容器总和。
由于多个 init 容器按顺序执行,并且执行完成立即退出,所以申请最多的资源 init 容器中的所需资源,即可满足所有 init 容器需求。
kube-scheduler 在计算该节点被占用的资源时,init 容器的资源依然会被纳入计算。因为 init容器在特定情况下可能会被再次执行,比如由于更换镜像而引起 Sandbox 重建时。
limit range
有些时候用户不想定义pod需要多少资源,又希望给一个默人资源;或者希望一个namespace中的pod都有一个limits,这时就可以使用LimitRange。
实践
创建limitrange。
cat limitrange.yaml
apiVersion: v1
kind: LimitRange
metadata:
name: mem-limit-range
spec:
limits:
- default:
memory: 512Mi
defaultRequest:
memory: 256Mi
type: Container
k apply -f limitrange.yaml
k get limtrange
启动一个不带资源限制的nginx pod。
cat nginx-without-resource.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
k apply -f nginx-without-resource.yaml
k get po -o yamlpod已经带了resources。
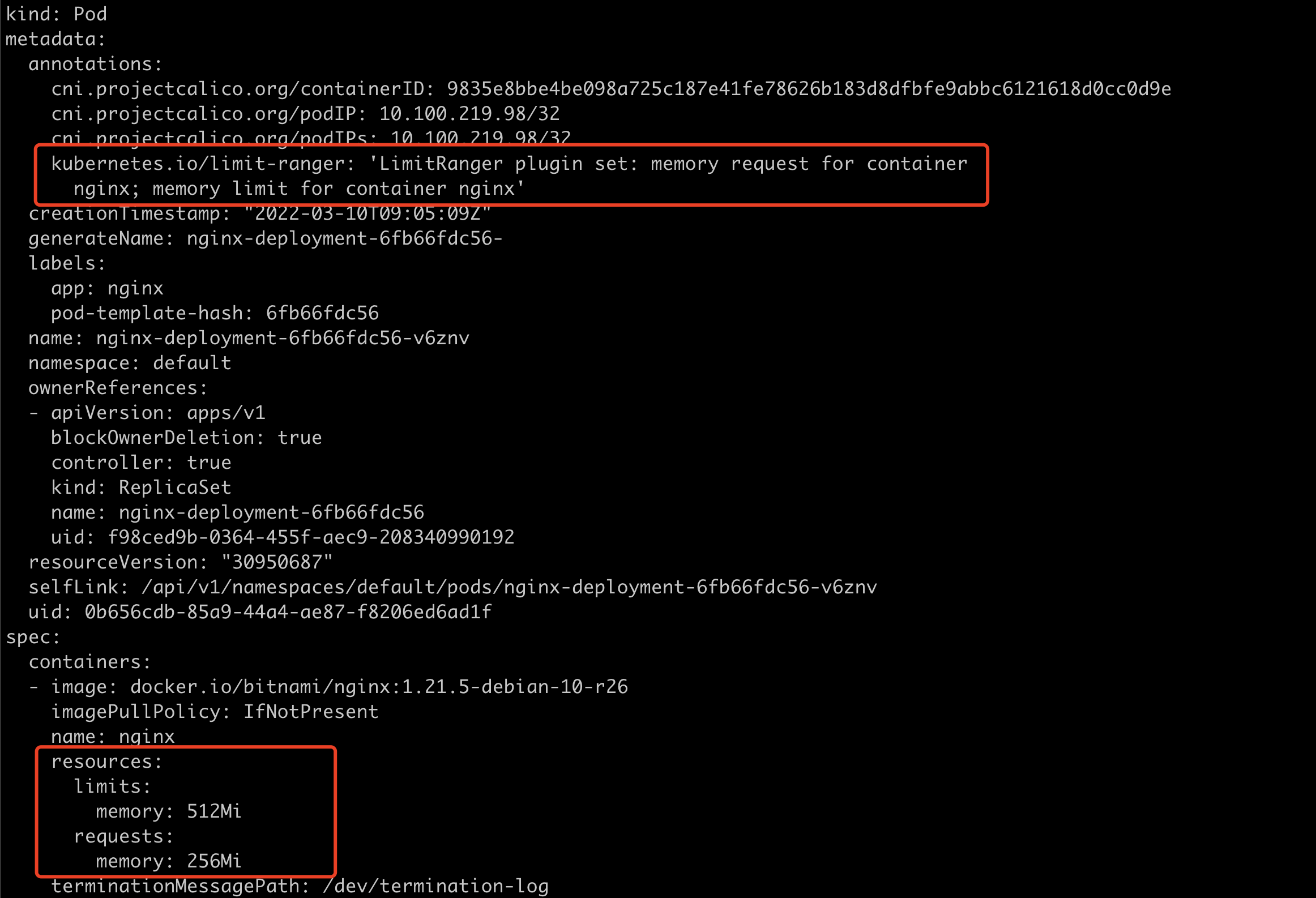
启动init container
cat init-container.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
initContainers:
- name: init-myservice
image: busybox:1.28
command: ['sh', '-c', 'echo The app is running! && sleep 10']
containers:
- name: nginx
image: nginx
k apply -f init-container.yaml
k get po -o yaml查看init container和主容器都被添加了resources。
把pod调度到指定node上
可以通过 nodeSelector、 nodeAffinity、podAffinity 以及 Taints 和 tolerations 等来将Pod 调度到需要的 Node 上。也可以通过设置 nodeName 参数,将 Pod 调度到指定 Node 节点上。
nodeSelector
把节点分类,让某些pod只允许调度到某个分类上。
实践
部署一个带nodeSelector的pod
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
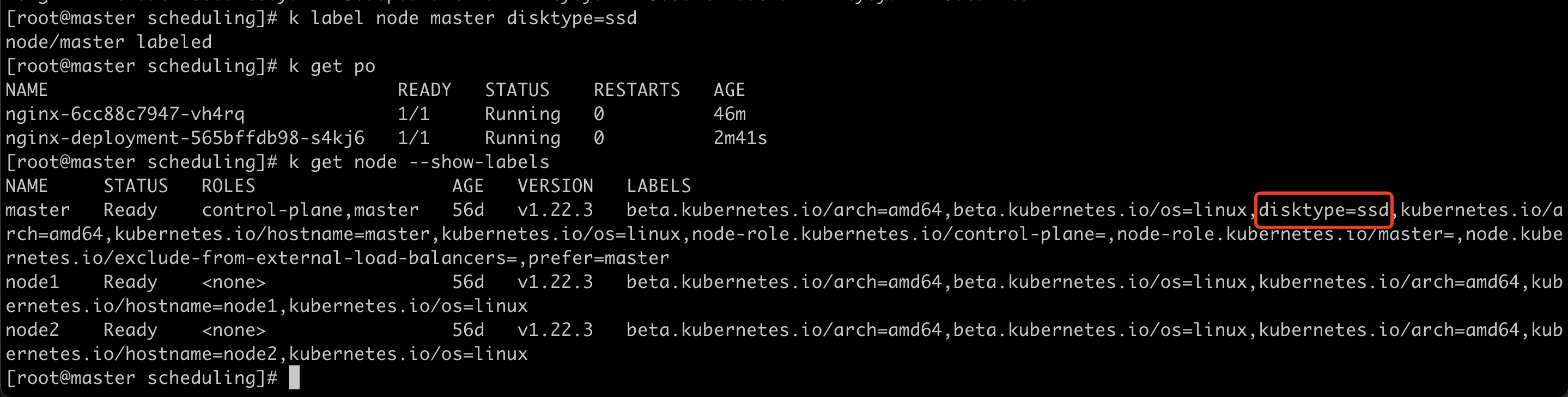
nodeSelector:
disktype: ssd查看pod处于pending状态

查看报错原因是节点亲和性不满足

添加node label,再次查看pod状态
nodeAffinity
nodeAffinity 目前支持两种:
硬亲和:requiredDuringSchedulinglgnoredDuringExecution 和
软亲和:preferredDuringSchedulinglgnoredDuringExecution,分别代表必须满足条件和优选条件。
硬亲和在 predicate 过程中,软亲和是在 priority 过程中。
lgnoredDuringExecution 是给动态调度器用的,就是De scheduler。pod正在运行,由于pod来来去去,node资源需要再平衡,这时需要动态调度。
实践
部署2个强亲和性带disktype的pod
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
replicas: 2
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: disktype
operator: In
values:
- ssd
containers:
- name: nginx
image: nginx添加node1 disktype的label

查看pod状态,可以看到都调度到了master上
因为我这里master的配置比较好,剩余资源更多,就都调度到了master上。如果配置相同的话由于 SelectorSpreadPriority 应该是一个master一个node1。

podAffinity
podAffinity 基于 Pod 的标签来选择 Node,仅调度到满足条件 Pod 所在的 Node 上,支持podAffinity 和 podAntiAffinity。
实践
nginx pod,label是anti-nginx,pod亲和是pod上有a=b的label才会调度,pod反亲和是pod上有anti-nginx的label就不会调度。
cat pod-anti-affinity.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-anti
spec:
replicas: 2
selector:
matchLabels:
app: anti-nginx
template:
metadata:
labels:
app: anti-nginx
spec:
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: a
operator: In
values:
- b
topologyKey: kubernetes.io/hostname
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- anti-nginx
topologyKey: kubernetes.io/hostname
containers:
- name: with-pod-affinity
image: nginx部署pod-anti-affinity.yaml,查看pod状态是pending。

原因是node上的pod都没有a=b的label,不满足pod亲和性。

给pod添加a=b的label,查看pod状态,一个running,一个pending。

原因是第一条亲和性满足了,第二条没有满足。因为running的pod已经带了anti-nginx的label,就不能调度到这个node上。

taints 和 tolerations
taints 和 tolerations 用于保证 Pod 不被调度到不合适的 Node 上,其中 taint 应用于 Node 上, 而 toleration 则应用于 Pod上。
目前支持的 taint 类型:
- NoSchedule:新的 Pod 不调度到该 Node 上,不影响正在运行的 Pod;
- PreferNoSchedule: Soft 版的NoSchedule,尽量不调度到该 Node 上;
- NoExecute: 新的 Pod 不调度到该 Node上,并且删除已在运行的 Pod。Pod 可以增加一个时间(tolerationSeconds),则会在该时间之后才删除 Pod。默认是600s。
k8s本身也在用taint,当一个node不响应时,NodeLifecycleController就会把这个node打上Unhealthy的taint,类型是NoSchedule。
实践
给节点添加taint
k taint node master for-special-user=cadmin:NoSchedule查看taint
k describe node master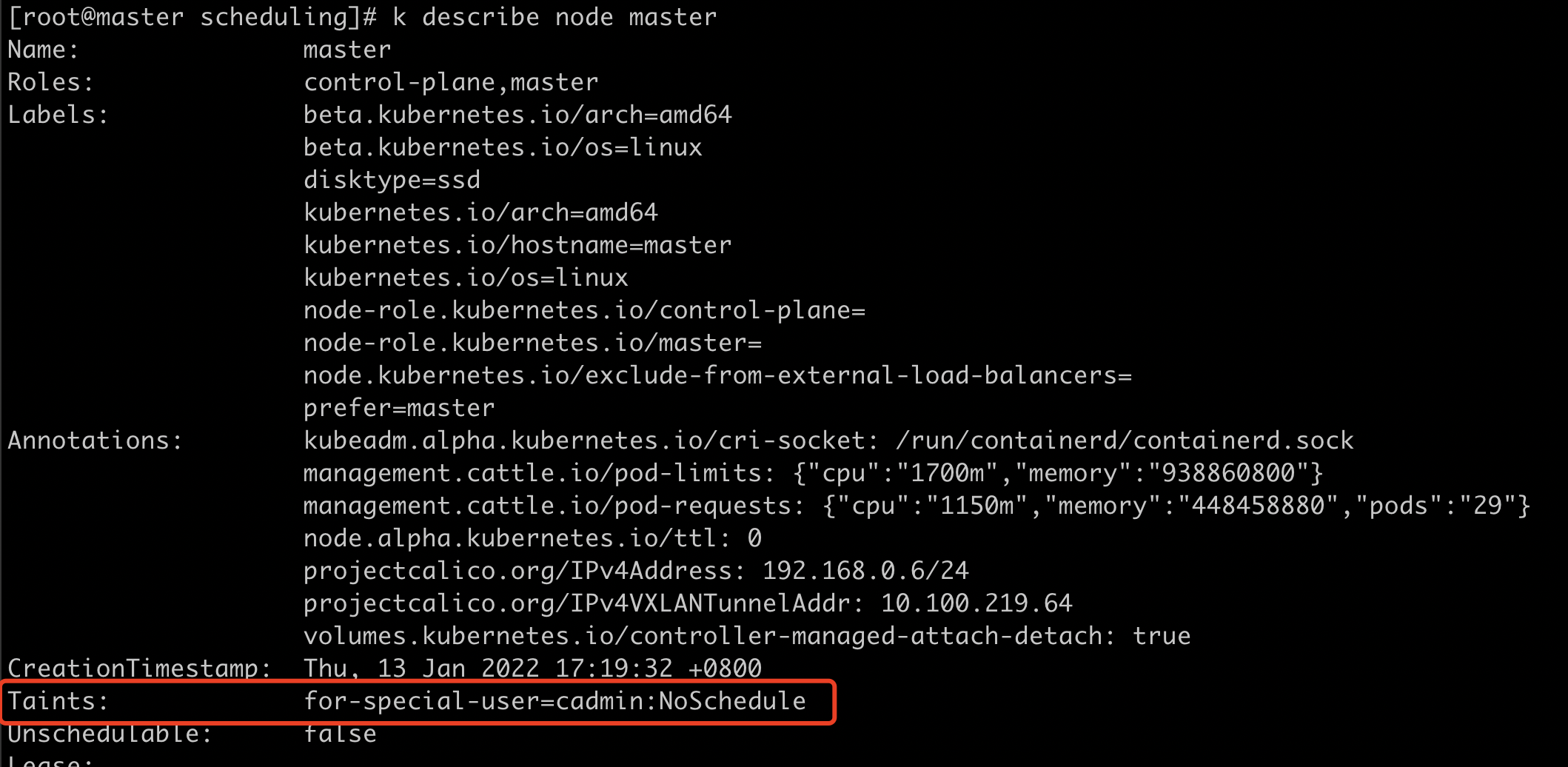
部署nginx-with-taint.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
tolerations:
- key: "for-special-user"
operator: "Equal"
value: "cadmin"
effect: "NoSchedule"查看pod状态为running,且调度到了master上

部署没有tolerations的nginx pod,查看pod调度到了node1上

删除master的taint
k taint node master for-special-user-优先级调度
集群中的业务肯定有重要程度区分,在集群资源紧张时,就可能发生资源争抢。优先级调度就可以让让高优先级的业务优先调度。
从v1.8 开始,kube-scheduler 支持定义 Pod 的优先级,从而保证高优先级的 Pod 优先调度。开启方法为:
- apiserver 配置 –feature-gates=PodPriority=true 和–runtime-
config=scheduling.k8s.io/vlalphal=true - kube-scheduler 配置 –feature-gates=PodPriority=true
PriorityClass
在指定 Pod 的优先级之前需要先定义一个 PriorityClass (非 namespace 资源)。
value越大优先级越高。如果globalDefault为true,那么这个集群中所有没有打PriorityClass的pod都是这个优先级。
而且PriorityClass还会抢占,当优先级高的pod处于pending状态时,k8s会去看有没有比这个优先级更低的pod,如果有,会把这个pod资源抢过来,并把这个pod驱逐。
cat PriorityClass.yaml
apiversion: v1
kind: PriorityClass
metadata:
name: high-priority
value: 1000000
globalDefault: false
description: "This is a priority class test.”为pod设置PriorityClass
cat priority.yaml
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
env: test
spec:
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
priorityClassName: high-priority多调度器
如果默认的调度器不满足要求,比如需要批处理调度。那么可以部署自定义的调度器。并且,在整个集群中还可以同时运行多个调度器实例,通过 pod.Spec.schedulerName 来选择使用哪一个调度器(默认使用内置的基于event的调度器)。比如腾讯的TKE,华为的Volcano等。
多租户集群实现
k8s集群一般是共享集群,用户无需关心节点细节。但是有些用户加入集群时自带了计算资源并且要求隔离,这应该怎么实现呢?
- 将要隔离的计算节点打上 Taints;
- 在用户创建创建 Pod 时,定义 tolerations 来指定要调度到 node taints。
但是这个方案是有漏洞的:
- 其他用户如果可以 get nodes 或者 pods,可以看到 taints 信息,也可以用相同的 tolerations 占用资源。
怎么解决?
- 不让用户 get node detail
- 不让用户 get 别人的 pod detail
- 企业内部,也可以通过审计查看统计数据看谁占用了哪些 Node;
可能遇到的问题
- 用户会忘记打 tolerations,导致 Pod 无法调度,pod处于pending状态;
- 其他用户会 get node detail,查到 taints,偷用资源。对于违规用户,批评教育为主。
- 集群中有一个node上的runtime有问题,应用起不来,但是节点状态是正常的。这时新建pod调度到这个node上,起不来。由于scheduler没有熔断机制,用户删除pod后又调度到这个node上还起不来,用户就会认为整个集群不可用了。
- 应用炸弹:用户新建了一个pod,但是这个pod里面一直fock子进程,可能pid/打开文件句柄/连接数过多。
由于容器是共享主机内核的,它就是一个运行在namespace中的进程,如果不加以限制,很可能把node上的资源耗尽,导致node状态变为not ready,然后node上的pod就会被驱逐掉。
然后pod被调度到一个好的node上,又把这个好的node弄坏。
总结
- filter预处理:遍历pod所有的init container和主container,计算pod的总资源需求。
- filter阶段:遍历所有节点,过滤掉所有不符合需求的节点。
- 处理扩展 predicate plugin
- score:处理弱亲和性
- 为节点打分
- 处理扩展 priority plugin
- 选择节点
- 假定选中pod
- 绑定pod