背景
上篇文章中使用rook部署的ceph集群是默认没有安装监控的,所以这里安装prometheus,并通过修改cluster.yaml文件来开启ceph集群的监控。
安装prometheus
使用之前创建的sc:rook-ceph-block.
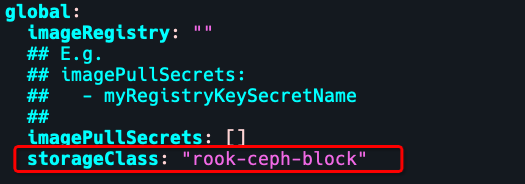
k create ns monitor
helm pull bitnami/kube-prometheus
tar xvf kube-prometheus-8.1.3.tgz
cd kube-prometheus
vim values.yaml
helm install prometheus . -n monitor
k get po,pvc -n monitor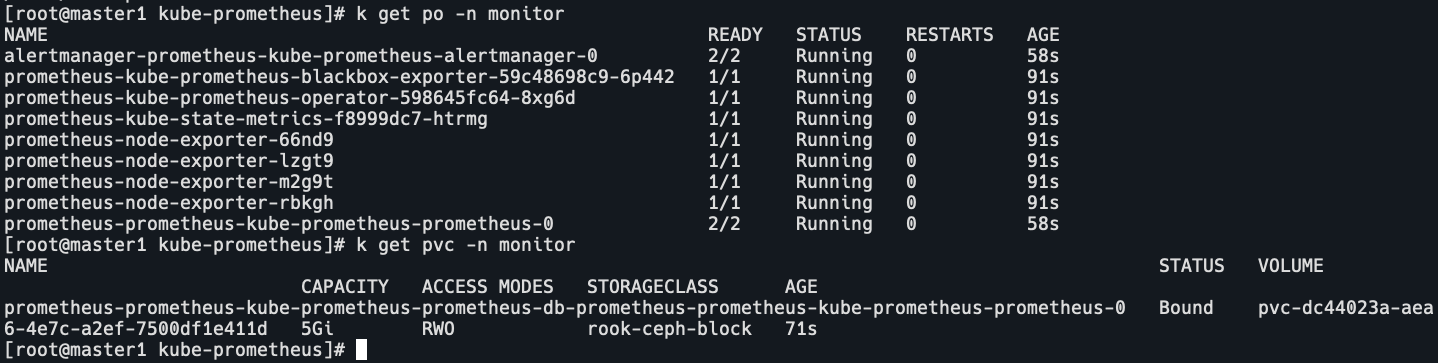
prometheus已部署完成,并且使用了ceph的rbd方式存储。
安装grafana+loki(也可以不安装loki)
helm pull grafana/loki-stack
tar xvf loki-stack-2.8.1.tgz
cd loki-stack
vim values.yaml
helm install loki . -n monitor
k get po -n monitor
修改prometheus和grafana的svc为NodePort
有域名的话就创建ingress,我这里没有。

添加安全组规则,访问URL。
开启ceph集群的监控
修改ceph集群的cluster.yaml文件,将monitor的enable改为true。

k apply -f cluster.yaml进入ceph-tools容器,查看mgr的module:
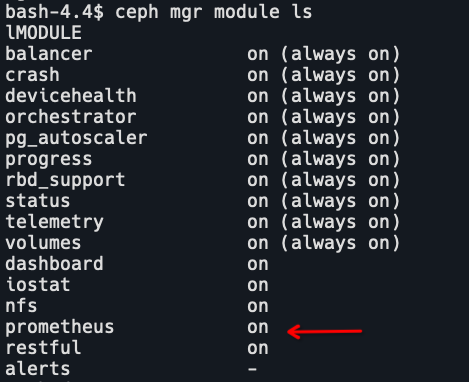
验证mgr的metrics
kubectl get svc -n rook-ceph
curl http://10.233.53.9:9283/metrics
创建servicemonitor,修改yaml中的ceph_daemon_id为svc的label。
cd deploy/examples/monitoring
k get svc -n rook-ceph -o wide
vim service-monitor.yaml
k apply -f service-monitor.yaml
k get servicemonitor -n rook-ceph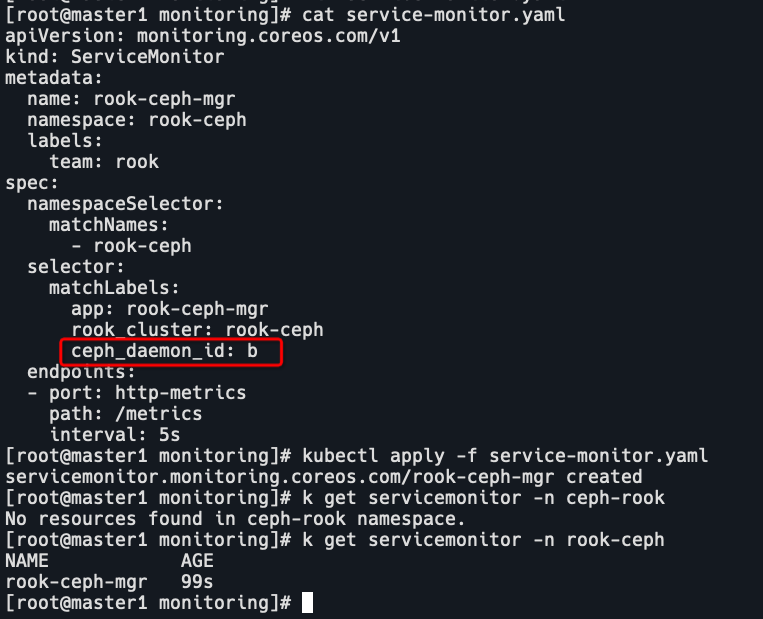
查看target
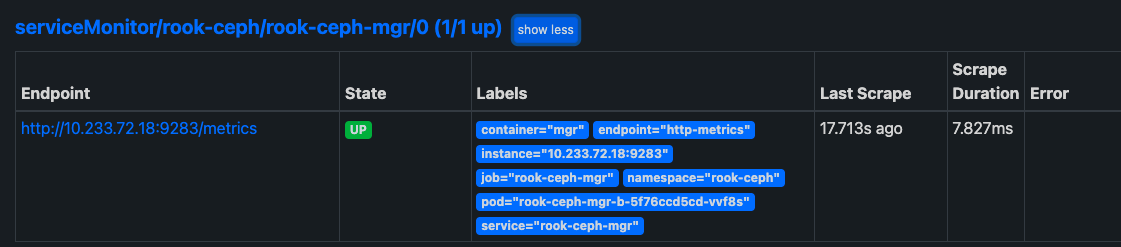
导入模版
5336,9340,5342,2842
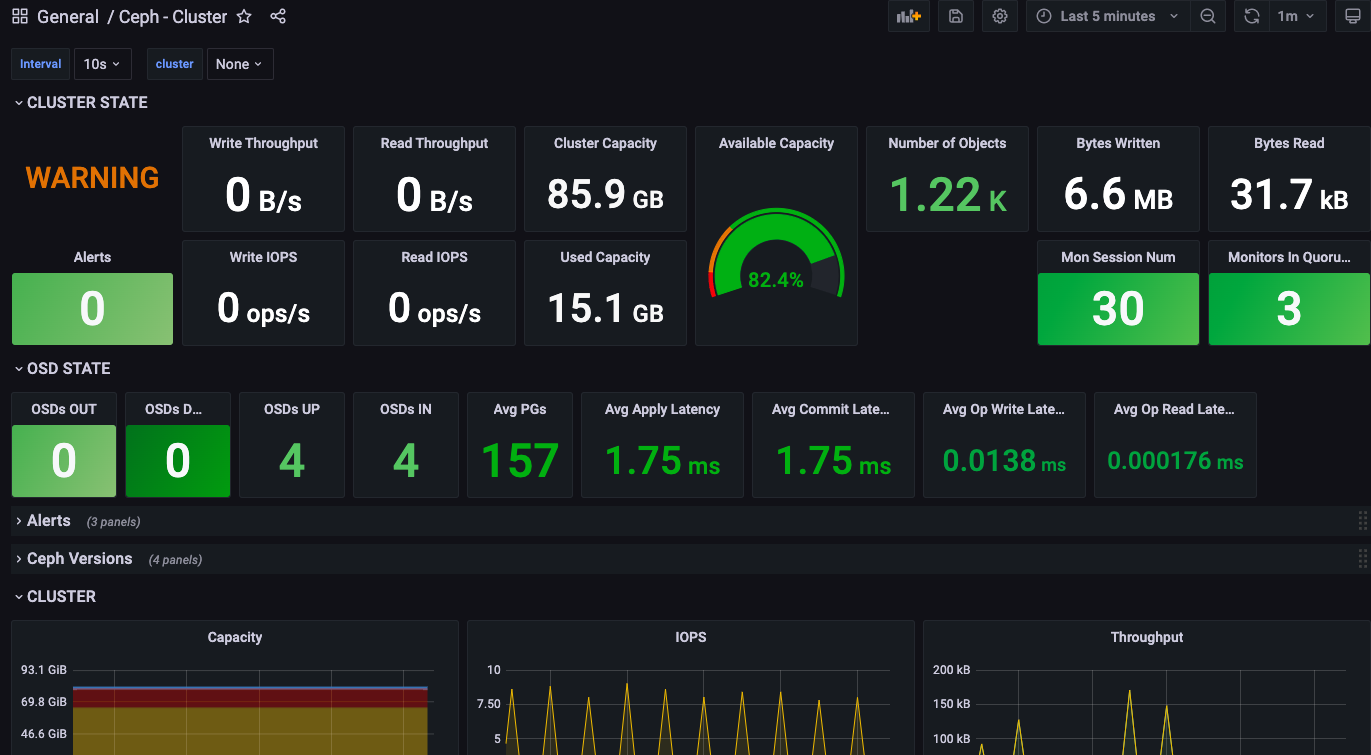
warning状态处理
进入ceph-tools容器,查看健康检查情况
ceph health
查看最新的crash信息
ceph crash ls-new
ceph crash info xxx
报错是arch没有设置backend,查看orch status
ceph orch status
我这里是用的rook部署,所以需要开启rook模块,并设置rook为backend。
ceph mgr module enable rook
ceph orch set backend rook
ceph orch status
清除crash告警
ceph crash prune 3
# crash prune <keep:int> Remove crashes older than <keep> days
ceph crash ls-new
ceph health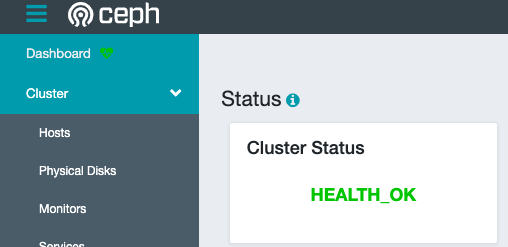
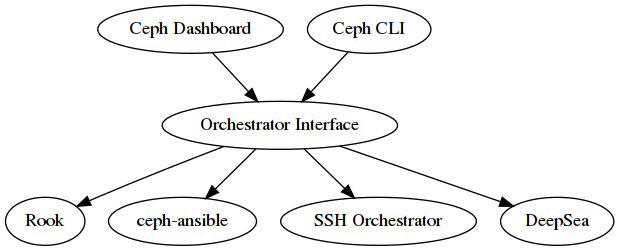
Orchestrator是什么
Orchestrator可以翻译为协调器或编排器,它提供控制外部部署工具(如ceph-ansible、DeepSea或Rook)的能力。希望在管理员、Ceph和外部部署系统之间提供一个桥梁。为了实现这一点,Orchestrator接口允许Ceph仪表板或CEPH命令行工具访问不同部署工具提供的数据,从而在Ceph Dashboard中启用基础设施管理功能。作为副作用,它将为不同的部署工具带来统一的安装体验。
启用后,Dashboard会使用Orchestrator接口管理iSCSI目标和NFS共享。
从体系结构的角度来看,Orchestrator接口是控制面板、命令行接口和Rook管理器模块之间的的核心组件。例如,如果用户调用命令行接口向集群添加新的OSD,那么Orchestrator模块将指示外部Orchestrator在指定主机上调用ceph-volume。
以下是Orchestrator的体系结构视图,显示了不同组件之间如何交互: