监控系统
为什么监控,监控什么内容?
- 当集群规模很大时,分别去看各个服务是否正常已经不可能了,所以需要一套监控系统来检测服务的健康情况。
- 对自己系统的运行状态了如指掌,有问题及时发现,而不是用户先发现我们系统不能使用。
- 我们也需要知道我们的服务运行情况。例如,slowsql 处于什么水平,平均响应时间超过 200ms 的占比有百分之多少?
我们为什么需要监控我们的服务?
- 需要监控工具来提醒我服务出现了故障,比如通过监控服务的负载来决定扩容或缩容。如果机器普遍负载不高,则可以考虑是否缩减一下机器规模,如果数据库连接经常维持在一个高位水平,则可以考虑一下是否可以进行拆库处理,优化一下架构。
- 监控还可以帮助进行内部统制,尤其是对安全比较敏感的行业,比如证券银行等。比如服务器受到攻击时,我们需要分析事件,找到根本原因,识别类似攻击,发现没有发现的被攻击的系统,甚至完成取证等工作。
监控的目的
- 减少宕机时间
- 扩展和性能管理
- 资源规划
- 识别异常事件
- 故障排除、分析
在k8s集群中的监控系统
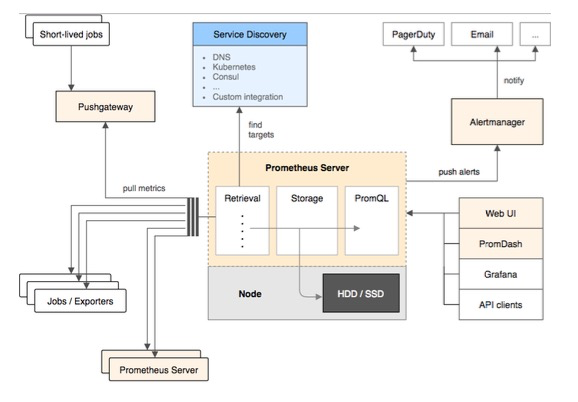
这张图其实就是prometheus的架构。
-
prometheus server:包括Retrieval,Storage,PromQL。
- Retrieval:prometheus采用pull模式来扫描集群中哪些服务暴露了prometheus的指标,然后会按照既定的频率去拉取这些指标。Retrieval会轮询所有目标节点,把节点上的日志取出来。
为什么用的pull而不是push?- 因为这样pod只需要收集指标就可以了,提供一个URL来访问这些指标。这样pod是不需要知道监控系统的存在,系统耦合度降低。
- storage:prometheus有自己的tsdb,存储监控数据到硬盘。
- PromQL:prometheus的查询语言。下文会介绍。
- Retrieval:prometheus采用pull模式来扫描集群中哪些服务暴露了prometheus的指标,然后会按照既定的频率去拉取这些指标。Retrieval会轮询所有目标节点,把节点上的日志取出来。
-
WebUI:prometheus的前端页面,可以通过PQL来查询。
-
Grafana:以图表的形式展示监控数据。
-
Alertmanager:定义一些规则来说明应用是否正常,不正常发送告警,可以和多个平台去集成。需要防止过度设计,比如可以自动恢复的服务就不需要告警。
-
pushgateway:有些pod不是一直运行,比如job,就可以推送这些指标到pushgateway。这样prometheus拉取指标到时候就直接去push gateway拉取。
节点上的监控指标
容器化的一个好处是监控变得标准化了。容器技术底层是cgroup和namespace。cgroup是做资源管控的,namespace是做隔离的。这样只需要扫描节点上cgroup文件夹的文件即可知道资源的使用情况。
每个节点的 kubelet(集成了 cAdvisor)会收集当前节点 host 上所有信息,包括 cpu、内存、磁盘等。Prometheus 会 pull 这些信息,给每个节点打上标签来区分不同的节点。

可以通过http://nodeip:9100/metrics来查看

如何汇报监控指标
pod中需要指定
annotations:prometheus.io/scrape: "true"还需要声明上报指标的端口和地址即pod的ip。
上篇文章中部署的loki,就自带了prometheus的指标。
k get po loki-0 -n loki -o yaml
metadata:
annotations:
prometheus.io/port: http-metrics
prometheus.io/scrape: "true"
spec:
ports:
- containerPort: 3100
name: http-metrics
protocol: TCP在target中查看loki endpoint。

k8s的control panel,包括各种controller都原生的暴露 prometheus格式的metrics。这也是为什么prometheus是集群监控的标准。

prometheu指标类型
-
Counter(计数器器)
- Counter 类型代表一种样本数据单调递增的指标,即只增不减,除非监控系统发生了重置。
- 比如统计error出现的次数。
-
Gauge(仪表盘)
- Guage 类型代表一种样本数据可以任意变化的指标,即可增可减。
- 监控各种数值比如CPU,内存,硬盘等。
-
Histogram(直方图)
- Histogram 在一段时间范围内对数据进行采样(通常是请求持续时间或响应大小等),并将其计入可配置的存储桶(bucket)中,后续可通过指定区间筛选样本,也可以统计样本总数,最后一般将数据展示为直方图。
- 样本的值分布在 bucket 中的数量,命名为
_bucketlle= "<上边界>"。 - 所有样本值的大小总和,命名为
_sum样本总数,命名为 _count。值和cbasename>_bucketlle="+Inf"}相同。 - 一般用在统计相关和性能分析,比如统计访问http服务的耗时情况。
-
Summary(摘要)
- 与 Histogram 类型类似,用于表示一段时间内的数据采样结果(通常是请求持续时间或响应大小等),但它直接存储了分位数(通过客户端计算,然后展示出来),而不是通过区间来计算。
- 它们都包含了 cbasename>_sum 和
_count指标。 - Histogram 需要通过
bucket 来计算分位数,而 Summary 则直接存储了分位数的值。 - 用户统计区间,比如百分之90的访问耗时是0.1秒。
Prometheu Query Language
以这个为例
histogram_quantile(0.95, sum(rate(httpserver_execution_latency_seconds_ bucket(5ml)) by (le))- Histogram 是直方图
- httpserver_execution_latency_seconds_bucke 是直方图指标,是将httpserver 处理请求的时间放入不同的bucket内,意思是落在不同时长区间的响应次数。
- by (le),是将采集的数据按桶的上边界分组。
1.rate(httpserver_execution_latency_seconds_bucketl5m]),计算的是五分钟内的变化率。 - Sum(),是将所有指标的变化率总计。
- 0.95,是取 95 分位。
综上:上述表达式计算的是 httpserver 处理请求时,95% 的请求在五分钟内,落在不同响应时间区间的变化情况。
grafana dashboard
官网地址:https://grafana.com/grafana/dashboards/
复制id或者下载对应的json文件
这里列举几个id:7429,315,6417,9729
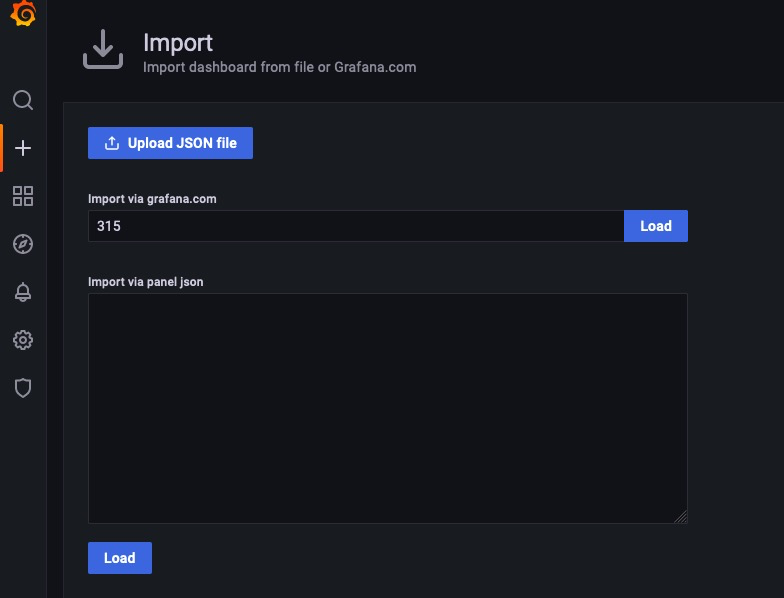
grafana中导入
查看图表

开启告警
- 查看prometheus的配置文件
k exec -it loki-prometheus-server-757c887449-jqpt4 -n loki -- sh cat /etc/config/prometheus.yml
rule配置:
- 查看目录文件
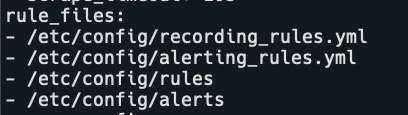
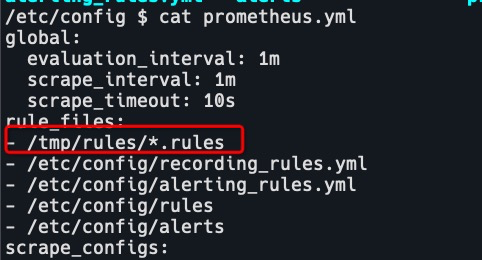
- 配置文件的目录也是通过configmap挂载的,所以需要修改configmap。创建rules目录,修改prometheus配置文件。
rule_files: - /tmp/rules/*.rules - 进入容器创建目录,拷贝rule规则。参考链接:https://awesome-prometheus-alerts.grep.to/rules
k exec -it loki-prometheus-server-5f48565875-66st8 -n loki -- sh mkdir /tmp/rules exit vim k8s.rules k cp k8s.rules loki-prometheus-server-5f48565875-66st8:/tmp/rules/k8s.rules -n loki - prometheus是有prometheus-alertmanager-configmap-reload pod的,这个容器的作用就是读取configmap,热加载prometheus的配置文件。大约1分钟后,进入容器查看prometheus的配置文件已经更新。
查看prometheus-alertmanager-configmap-reload pod日志
- 修改alertmanager配置,alertmanager配置文件的目录也是通过configmap挂载的,所以也需要修改configmap。
# pod的yaml volumeMounts: - mountPath: /etc/config name: config-volume volumes: - configMap: defaultMode: 420 name: loki-prometheus-alertmanager name: config-volume不能进容器修改文件,也不能kubectl cp到目录,即使修改了目录权限,以root用户登录容器也不行。
#修改cm中global字段的配置 global: resolve_timeout: 5m #处理超时时间,默认为5min smtp_smarthost: 'smtp.qq.com:465' # 邮箱smtp服务器代理 smtp_from: 'aaa@qq.com' # 发送邮箱名称 smtp_auth_username: 'xxx@qq.com' # 邮箱名称 smtp_auth_password: 'qwertyuio' # 邮箱密码或授权码 smtp_require_tls: false # 定义模板信息 templates: - '/alertmanager/template/alertmanager-email.tmpl' route: # 路由组 group_by: ['alertname', 'app'] group_wait: 30s group_interval: 40s repeat_interval: 1m receiver: email-receiver # 发送给那个组 receivers: # 收件人组 - name: 'email-receiver' email_configs: - to: 'xxx@qq.com' # 收件人地址 html: '{{ template "email.to.html" . }}' # HTML模板文件正文 send_resolved: true inhibit_rules: - source_match: severity: 'critical' target_match_re: severity: '.*' equal: ['instance'] - alertmanager是有prometheus-alertmanager-configmap-reload容器的,作用和prometheus的pod一样,等待更新完成。
-
拷贝模版文件到容器
crictl ps | grep alert nerdctl -n k8s.io exec -it -u root 1f46997746b96 sh mkdir /alertmanager/template k cp alertmanager-email.tmpl loki/loki-prometheus-alertmanager-86c8f5c8d6-mdjgq:/alertmanager/template/模版文件如下:
cat alertmanager-email.tmpl {{ define "email.to.html" }} {{- if gt (len .Alerts.Firing) 0 -}} {{- range $index, $alert := .Alerts -}} ========= <span style=color:red;font-size:36px;font-weight:bold;> 监控告警 </span>=========<br> <span style=font-size:20px;font-weight:bold;> 告警程序:</span> Alertmanage <br> <span style=font-size:20px;font-weight:bold;> 告警类型:</span> {{ $alert.Labels.alertname }} <br> <span style=font-size:20px;font-weight:bold;> 告警级别:</span> {{ $alert.Labels.severity }} 级 <br> <span style=font-size:20px;font-weight:bold;> 告警状态:</span> {{ .Status }} <br> <span style=font-size:20px;font-weight:bold;> 故障主机:</span> {{ $alert.Labels.instance }} {{ $alert.Labels.device }} <br> <span style=font-size:20px;font-weight:bold;> 告警主题:</span> {{ .Annotations.summary }} <br> <span style=font-size:20px;font-weight:bold;> 告警详情:</span> {{ $alert.Annotations.message }}{{ $alert.Annotations.description}} <br> <span style=font-size:20px;font-weight:bold;> 主机标签:</span> {{ range .Labels.SortedPairs }} <br> [{{ .Name }}: {{ .Value | html }} ]{{ end }}<br> <span style=font-size:20px;font-weight:bold;> 故障时间:</span> {{ ($alert.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}<br> ========= = end = =========<br> <br> <br> <br> <br> <div> <div style=margin:40px> <p style=font-size:20px>wghdr</p> <p style=color:red;font-size:14px> (这是一封自动发送的邮件,请勿回复。) </p> </div> <div align=right style="margin:40px;border-top:solid 1px gray" id=bottomTime> <p style=margin-right:20px> WghDr Ops </p> <label style=margin-right:20px> {{ ($alert.StartsAt.Add 28800e9).Format "2006-01-02 " }}<br> </label> </div> </div> {{- end }} {{- end }} {{- if gt (len .Alerts.Resolved) 0 -}} {{- range $index, $alert := .Alerts -}} ========= <span style=color:#00FF00;font-size:24px;font-weight:bold;> 告警恢复 </span>=========<br> <span style=font-size:20px;font-weight:bold;> 告警程序:</span> Alertmanage <br> <span style=font-size:20px;font-weight:bold;> 告警主题:</span> {{ $alert.Annotations.summary }}<br> <span style=font-size:20px;font-weight:bold;> 告警主机:</span> {{ .Labels.instance }} <br> <span style=font-size:20px;font-weight:bold;> 告警类型:</span> {{ .Labels.alertname }}<br> <span style=font-size:20px;font-weight:bold;> 告警级别:</span> {{ $alert.Labels.severity }} 级 <br> <span style=font-size:20px;font-weight:bold;> 告警状态:</span> {{ .Status }}<br> <span style=font-size:20px;font-weight:bold;> 告警详情:</span> {{ $alert.Annotations.message }}{{ $alert.Annotations.description}}<br> <span style=font-size:20px;font-weight:bold;> 故障时间:</span> {{ ($alert.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}<br> <span style=font-size:20px;font-weight:bold;> 恢复时间:</span> {{ ($alert.EndsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}<br> {{- end }} ========= = end = ========= <br> <br> <br> <br> <div> <div style=margin:40px> <p style=font-size:20px>wghdr</p> <p style=color:red;font-size:14px> (这是一封自动发送的邮件,请勿回复。) </p> </div> <div align=right style="margin:40px;border-top:solid 1px gray" id=bottomTime> <p style=margin-right:20px> WghDr Ops </p> <label style=margin-right:20px> {{ ($alert.StartsAt.Add 28800e9).Format "2006-01-02 " }}<br> </label> </div> </div> {{- end }} {{- end }} {{- end }}




构建生产系统的监控
- Metrics
收集数据。 - Alert
创建告警规则,如果告警规则被触发,按照不同级别来告警。 - Assertion
比如有些组件不是那么活跃,平时没什么人用,如果有问题的话不会充分暴露出来。
那么创建Assertion的pod,类似Cluster Autoscaler中的Simulator以一定时间间隔,模拟客户行为,操作k8s对象,并断言成功,如果不成功则按照不同级别告警。
注意
-
Prometheus 需要大内存和存储
- Prometheus自身有tsdb需要存储数据,如果给定的硬盘很小,Prometheus会经常发生 O0M kill。
- 在提高硬盘以后,发现内存占用也很高,kubelet就把它踢走了,踢到了别的node上,如果存储用的hostpath,那么新节点上的硬盘不久也会被撑爆了。
- 如果发生 crash 或者重启,Prometheus 需要 30 分钟以上的时间来读取数据进行初始化。
-
Prometheus 是运营生产系统过程中最重要的模块
- 如果 Prometheus down 机,则没有任何数据和告警,管理员两眼一黑,什么都不知道了。
- 解决方法:用其他集群中的prometheus互相监控。