故障现象
harvester已成功部署,并创建了多个虚拟机,但是虚拟机没有外网,无法下载镜像。遂想用squid来配置代理。查看高级设置,有http_proxy这个配置项,就在http-proxy和https-proxy中配置了http://172.16.255.180:3128, 而没有配置no-proxy。
1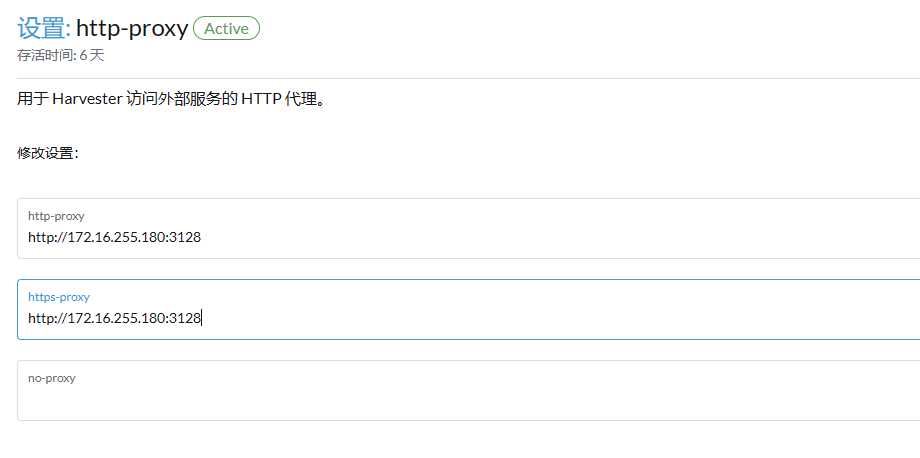
过一会就发现harvester页面无法打开,登录集群查看,集群已经崩溃,kubectl无法执行了。
环境
squid地址:http://172.16.255.180:3128
master1:harvester03 172.16.254.203
master2:harvester04 172.16.254.204
master3:harvester05 172.16.254.205
harvester版本:1.20-rc2
故障原因
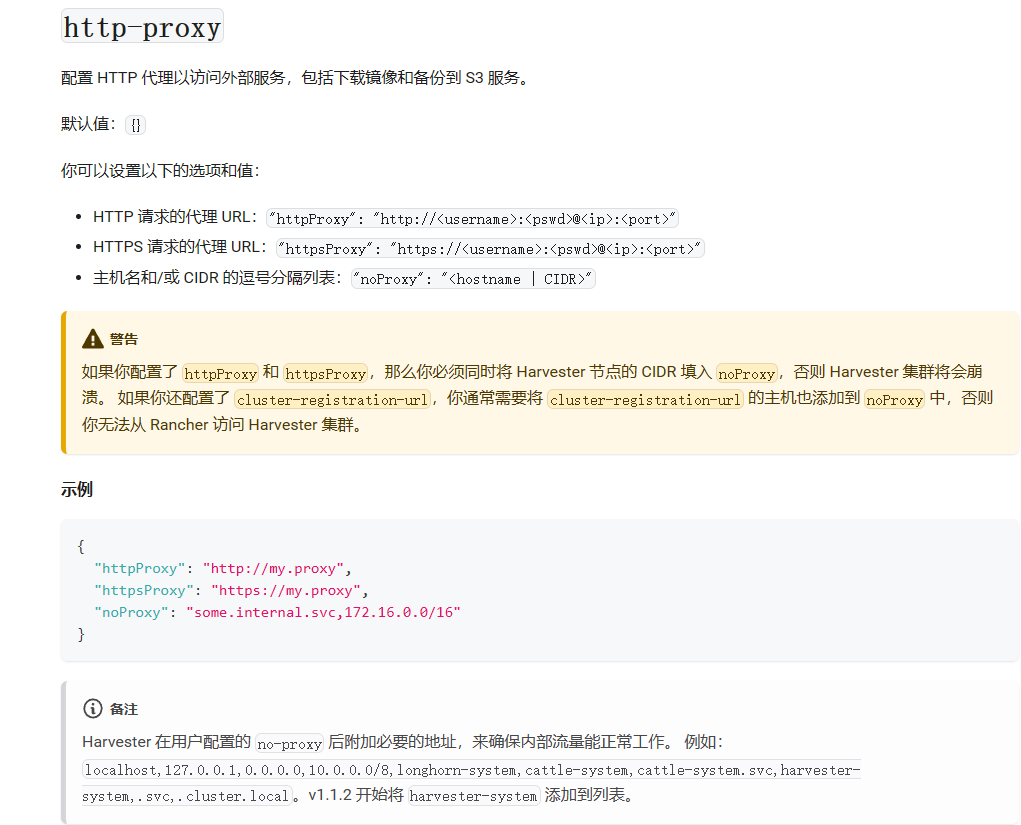
我没有看官方文档中关于http-proxy配置的说明:https://docs.harvesterhci.io/zh/dev/advanced/settings/#http-proxy
文档中说明了必须同时将Harvester节点的CIDR填入noProxy,否则Harvester集群将会崩溃。
解决
查看容器状态
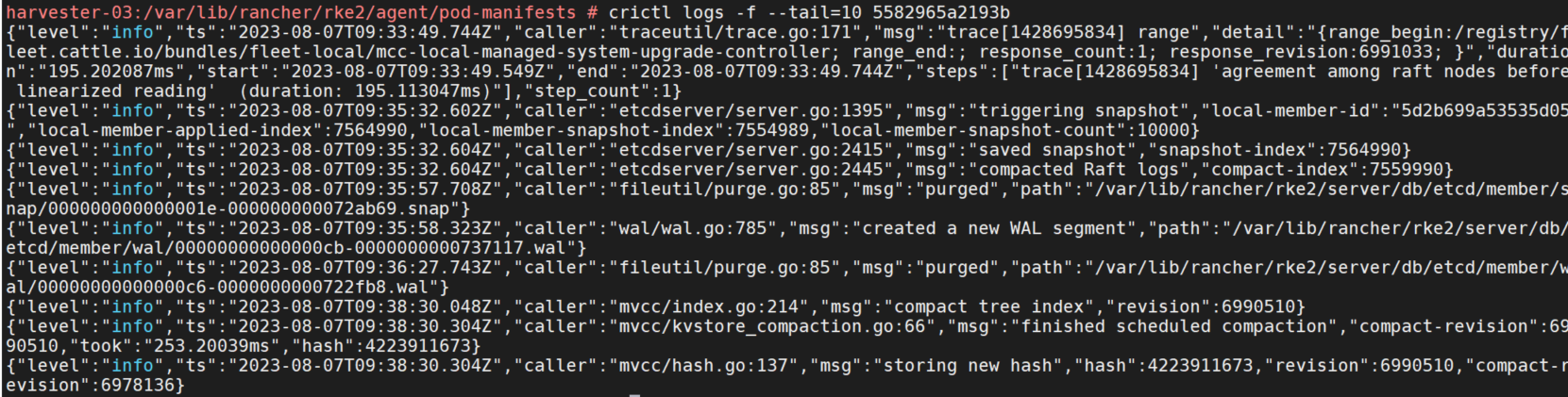
首先查看容器状态,发现容器都已经变为了Exited状态,只有etcd和kube-scheduler还在启动着,查看etcd日志,
crictl logs -f --tail=10 xxx发现etcd日志报错dns无法解析。

修改http-proxy
尝试在机器中寻找http-proxy的配置文件。但是没有找到具体在哪个配置文件中配置的。
容器的配置文件目录cd /run/k3s/containerd/io.containerd.runtime.v2.task/k8s.io
config.json:

rancher-system-agent.env

pod的配置文件目录:/var/lib/rancher/rke2/agent/pod-manifests,尝试修改配置文件,并没有生效,改了又自动还原回去了。

containerd的配置文件中也没有配置http-proxy。
rke2-sa.env

修改过后重启etcd也没用。kubelet的配置文件中也没有看到http-proxy配置,遂放弃寻找http-proxy配置文件。
crictl stop $etcd-containerid修改dns
既然报错dns无法解析,那就修改dns。
harvester主机上配置了nameserver是172.16.255.251,在172.16.255.251上无法解析harvester-03,harvester-04,harvester-05。
在172.16.255.251上配置harvester主机的dns解析,重启etcd容器,未生效,仍然报错无法解析。
登录代理机器,配置harvester主机的dns解析。修改squid代理配置,将deny全部删除,重启squid服务。重启etcd容器仍然报错无法解析。

后来在harvester每台主机上都添加hosts:
172.16.255.180 harvester-04
172.16.255.180 harvester-05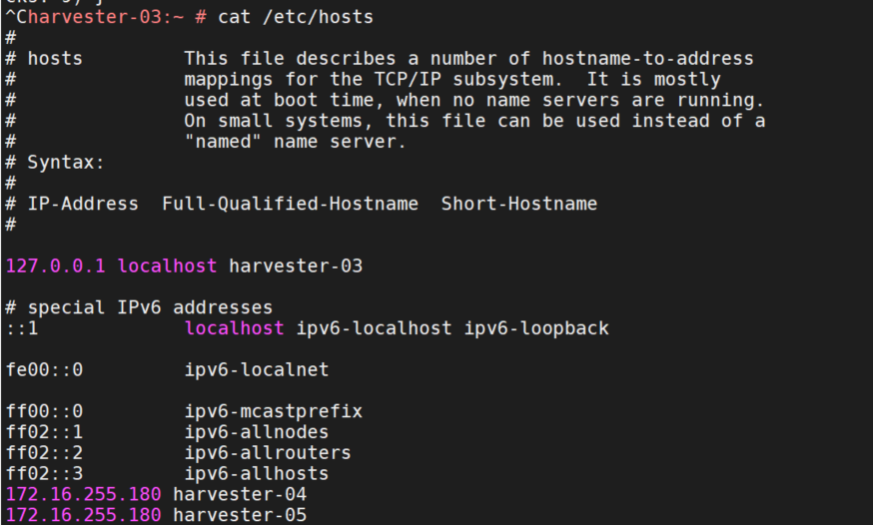
172.16.255.251上也配置上:172.16.255.180 harvester-03-05的解析。重启etcd容器,发现可以正常建立起邻居了。其他容器也自动恢复了。
还原http-proxy
kubectl get setting http-proxy -o yaml
kubectl edit setting http-proxy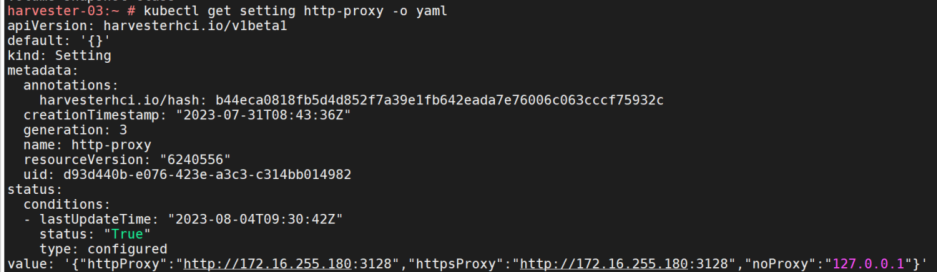
改成这样:value: '{}'

注意改成下面这样是不生效的:
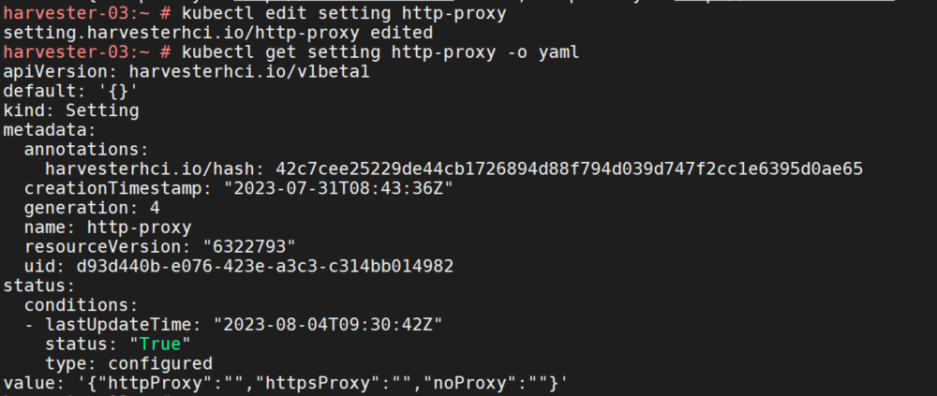
改成value: ''也是不行的,会报错不符合json格式。

setting和网页上http-proxy的配置都为空了,但是静态pod中还是会有180的代理配置,需要重启rancher-system-agent。
cat /etc/systemd/system/rancher-system-agent.service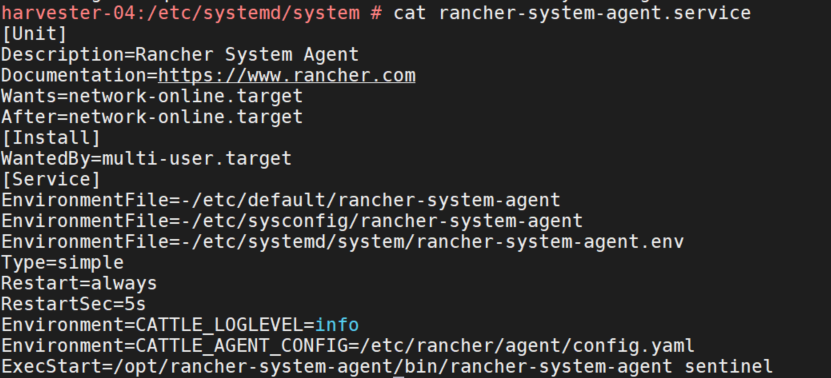
rancher-system-agent使用的环境变量是rancher-system-agent.env,而rancher-system-agent.env中配置了http-proxy,所以删除代理重启agent即可。
cat /etc/systemd/system/rancher-system-agent.env
# 清空文件
echo > /etc/systemd/system/rancher-system-agent.env
systemctl restart rancher-system-agent
cd /var/lib/rancher/rke2/agent/pod-manifests
grep -r 3128

静态pod配置文件中已没有了代理相关配置。
在其他机器中做同样的操作,重启agent。etcd日志恢复正常,集群完全恢复。