上文中介绍了OpenKruise有多种核心能力也就是下面的crd,下面就分别介绍下每个crd的功能。
CloneSet
CloneSet 控制器提供了高效管理无状态应用的能力,它可以对标原生的 Deployment,但 CloneSet 提供了很多增强功能。CloneSet 是一个直接管理 Pod 的 Set 类型 workload。
扩缩容功能
CloneSet 允许用户配置 PVC 模板 volumeClaimTemplates,用来给每个 Pod 生成独享的 PVC,这是 Deployment 所不支持的。 如果用户没有指定这个模板,CloneSet 会创建不带 PVC 的 Pod。
- 每个被自动创建的 PVC 会有一个 ownerReference 指向 CloneSet,因此 CloneSet 被删除时,它创建的所有 Pod 和 PVC 都会被删除。
- 每个被 CloneSet 创建的 Pod 和 PVC,都会带一个 apps.kruise.io/cloneset-instance-id: xxx 的 label。关联的 Pod 和 PVC 会有相同的 instance-id,且它们的名字后缀都是这个 instance-id。
- 如果一个 Pod 被 CloneSet controller 缩容删除时,这个 Pod 关联的 PVC 都会被一起删掉。
- 如果一个 Pod 被外部直接调用删除或驱逐时,这个 Pod 关联的 PVC 还都存在;并且 CloneSet controller 发现数量不足重新扩容时,新扩出来的 Pod 会复用原 Pod 的 instance-id 并关联原来的 PVC。
- 当 Pod 被重建升级时,关联的 PVC 会跟随 Pod 一起被删除、新建。
- 当 Pod 被原地升级时,关联的 PVC 会持续使用。
下面是一个示例yaml:
apiVersion: apps.kruise.io/v1alpha1
kind: CloneSet
metadata:
labels:
app: sample
name: sample-data
spec:
replicas: 2
selector:
matchLabels:
app: sample
template:
metadata:
labels:
app: sample
spec:
containers:
- name: nginx
image: nginx:stable-alpine
imagePullPolicy: IfNotPresent
volumeMounts:
- name: data-vol
mountPath: /usr/share/nginx/html
volumeClaimTemplates:
- metadata:
name: data-vol
spec:
accessModes: [ "ReadWriteOnce" ]
resources:
requests:
storage: 2Gi

如果 Pod 被外部直接调用删除或驱逐时,这个 Pod 关联的 PVCs 还都存在;并且 CloneSet controller 发现数量不足重新扩容时,新扩出来的 Pod 会复用原 Pod 的 instance-id 并关联原来的 PVCs。
删除了 sample-data-6gn78 pod,可以看到pod重建后仍然使用的原来的id,关联了原来的pvc。
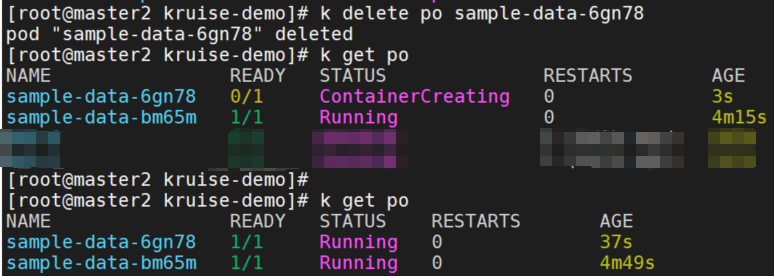
然而,如果 Pod 所在的 Node 出现异常,复用可能会导致新 Pod 启动失败,详情参考 issue 1099。为了解决这个问题,您可以设置字段 DisablePVCReuse=true。在这种情况下,与 Pod 相关的 PVCs 将被自动删除,不再被复用。
apiVersion: apps.kruise.io/v1alpha1
kind: CloneSet
spec:
...
replicas: 2
scaleStrategy:
disablePVCReuse: true当 volumeClaimTemplates 改变时,将会重建升级 Pod 和关联的 volume。默认情况下,如果 image 和 volumeClaimTemplates 同时改变,CloneSet 将会原地升级 Pod,并且不会重建 volume,导致 volumeClaimTemplates 配置不生效。
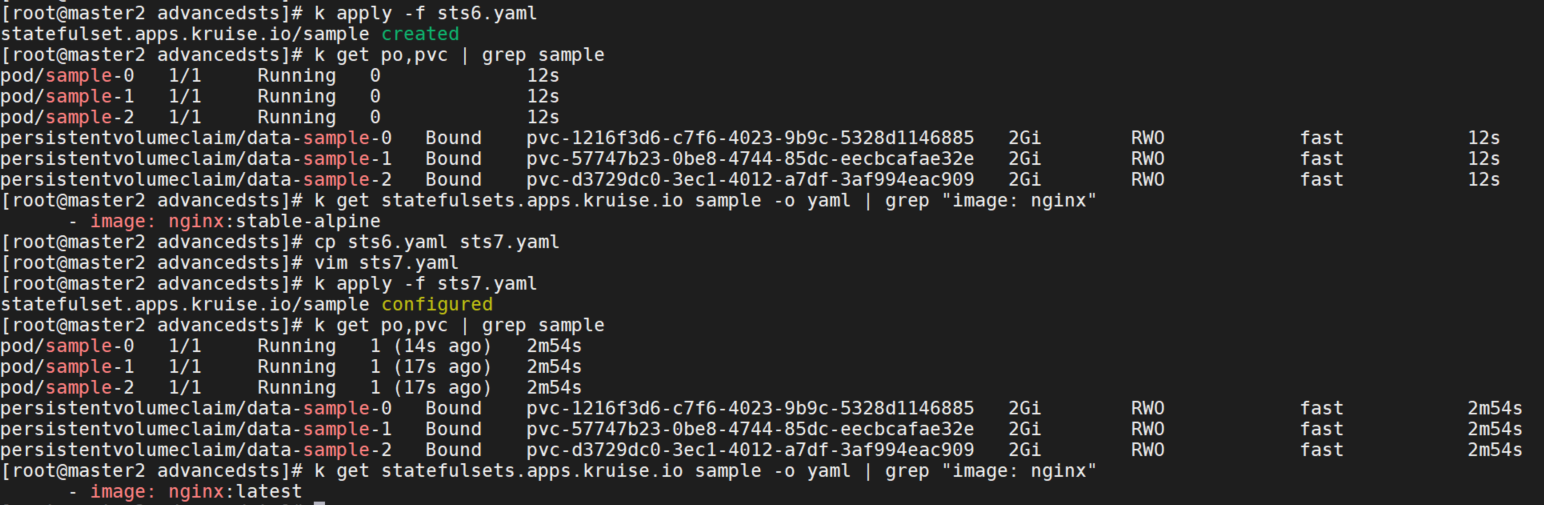
将镜像从nginx:stable-alpine修改为nginx:latest,storage修改为3G。

这里image和storage都变为了最新的,和官方文档不一致。查看当前RecreatePodWhenChangeVCTInCloneSetGate=true的默认值是false。启动命令如下,也没有启用这个feature-gate。
/manager --enable-leader-election --metrics-addr=:8080 --health-probe-addr=:8000 --logtostderr=true --leader-election-namespace=kruise-system --v=4 --feature-gates=ImagePullJobGate=true --sync-period=0
查看代码,当启用了原地升级时,会忽略VolumeClaimTemplates的哈希比较。
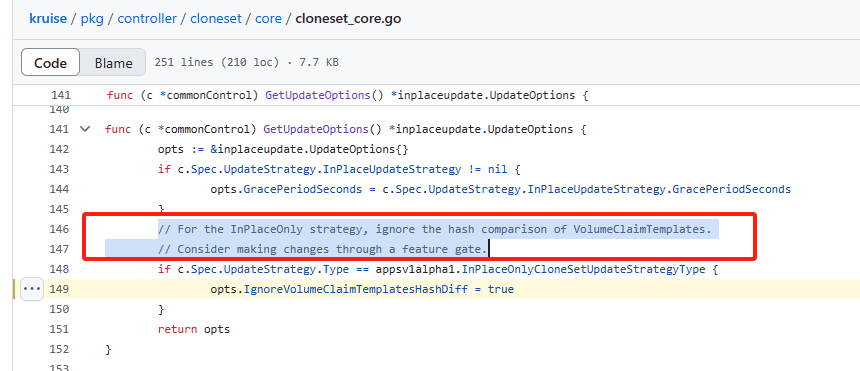
所以上面的yaml中需要添加更新类型为原地升级,才能符合文档中的情况。
volumeClaimTemplates:
- metadata:
name: data-vol
spec:
accessModes: [ "ReadWriteOnce" ]
resources:
requests:
storage: 20Gi
updateStrategy:
type: InPlaceIfPossible查看默认cloneset的类型为重建升级,并非原地升级。

重新创建sample,可以看到这次pod原地升级了,但是pvc大小没有改变。

官方文档我提交了个更改:https://github.com/openkruise/openkruise.io/compare/master…wgh9626:openkruise.io:patch-1?diff=unified&w=
升级kruise,设置feature-gateRecreatePodWhenChangeVCTInCloneSetGate=true。
helm upgrade kruise --set featureGates="RecreatePodWhenChangeVCTInCloneSetGate=true" .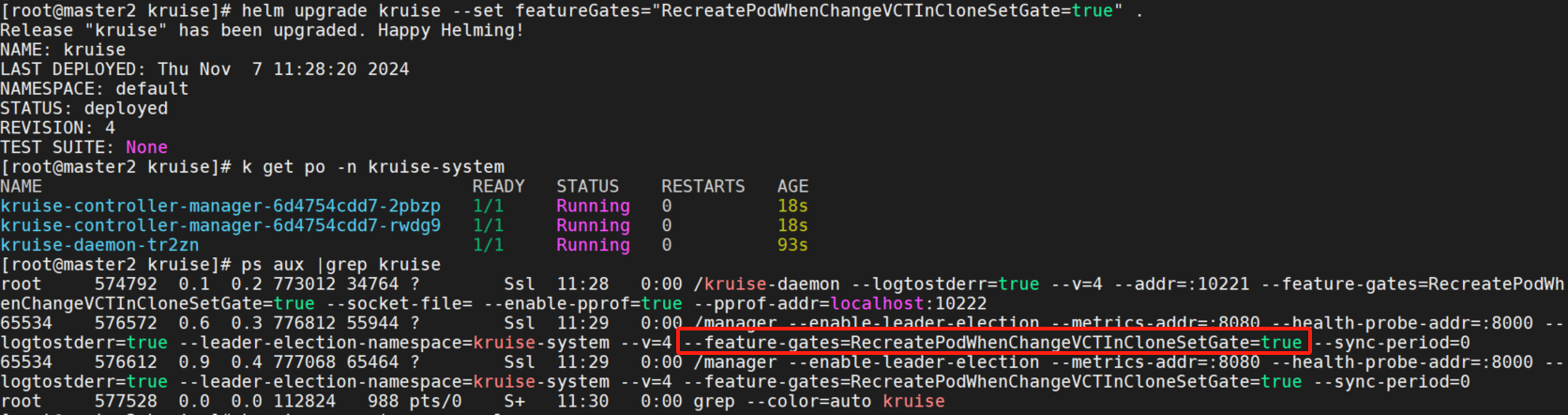
再次使用上面原地升级的yaml测试,可以发现pod和pvc都重建了。

如果只修改volumeClaimTemplates字段,不会触发 Pod 升级,需要同步着修改 Labels、Annotations、Image、Env 等字段才可以。

指定Pod缩容
当一个 CloneSet 被缩容时,有时候用户需要指定一些 Pod 来删除。这对于 StatefulSet 或者 Deployment 来说是无法实现的,因为 StatefulSet 要根据序号来删除 Pod,而 Deployment/ReplicaSet 目前只能根据控制器里定义的排序来删除。
CloneSet 允许用户在缩小 replicas 数量的同时,指定想要删除的 Pod 名字。
# k get po | grep sample
sample-data-krfmn 1/1 Running 0 7d4h
sample-data-p8lh7 1/1 Running 0 7d4h
# vim sample.yaml
# 添加podsToDelete
replicas: 1
scaleStrategy:
podsToDelete:
- sample-data-p8lh7当控制器收到上面这个 CloneSet 更新之后,会确保 replicas 数量为 1。如果 podsToDelete 列表里写了一些 Pod 名字,控制器会优先删除这些 Pod。 对于已经被删除的 Pod,控制器会自动从 podsToDelete 列表中清理掉。可以看到删除了sample-data-p8lh7pod。
# k get po | grep sample
sample-data-krfmn 1/1 Running 0 7d4h如果你只把 Pod 名字加到 podsToDelete,但没有修改 replicas 数量,那么控制器会先把指定的 Pod 删掉,然后再扩一个新的 Pod。 另一种直接删除 Pod 的方式是在要删除的 Pod 上打 apps.kruise.io/specified-delete: true 标签。
# k get po | grep sample
sample-data-ctvd2 1/1 Running 0 9s
sample-data-p8lh7 1/1 Running 0 7d4h
# vim sample.yaml
# 添加podsToDelete
replicas: 2
scaleStrategy:
podsToDelete:
- sample-data-ctvd2
# k apply -f sample.yaml
# k get po | grep sample
sample-data-72rs7 1/1 Running 0 21s
sample-data-krfmn 1/1 Running 0 7d4h可以看到优先删除的是sample-data-72rs7pod。
相比于手动直接删除 Pod,使用 podsToDelete 或 apps.kruise.io/specified-delete: true 方式会有 CloneSet 的 maxUnavailable/maxSurge 来保护删除, 并且会触发 PreparingDelete 生命周期 hook。
缩容顺序
- 未调度 < 已调度
- PodPending < PodUnknown < PodRunning
- Not ready < ready
- 较小 pod-deletion cost < 较大 pod-deletion cost
- 较大打散权重 < 较小
- 处于 Ready 时间较短 < 较长
- 容器重启次数较多 < 较少
- 创建时间较短 < 较长
Pod deletion cost
controller.kubernetes.io/pod-deletion-cost 是从 Kubernetes 1.21 版本后加入的 annotation,Deployment/ReplicaSet 在缩容时会参考这个 cost 数值来排序。 CloneSet 从 Kruise v0.9.0 版本后也同样支持了这个功能。
用户可以把这个 annotation 配置到 pod 上,值的范围在 [-2147483647, 2147483647]。 它表示这个 pod 相较于同个 CloneSet 下其他 pod 的 "删除代价",代价越小的 pod 删除优先级相对越高。 没有设置这个 annotation 的 pod 默认 deletion cost 是 0。
Deletion by Spread Constraints
目前,CloneSet 支持 按同节点打散 和 按 pod topolocy spread constraints 打散。
如果在 CloneSet template 中存在 Pod Topology Spread Constraints 规则定义,则 controller 在这个 CloneSet 缩容的时候会根据 spread constraints 规则来所打散并选择要删除的 pod。 否则,controller 默认情况下是按同节点打散来选择要缩容的 pod。
短 hash
默认情况下,CloneSet 在 Pod label 中设置的 controller-revision-hash 值为 ControllerRevision 的完整名字,它是通过 CloneSet 名字和 ControllerRevision hash 值拼接而成。 通常 hash 值长度为 8~10 个字符,而 Kubernetes 中的 label 值不能超过 63 个字符。 因此 CloneSet 的名字一般是不能超过 52 个字符的。
所以引入了CloneSetShortHash,如果它被打开,CloneSet 会将 controller-revision-hash 的值只设置为 hash 值,比如 cdd68fb87,因此 CloneSet 名字则不会有任何限制了。
下面 pod-template-hash 标签,它永远是短 hash 的形式。

流式扩容
CloneSet 扩容时可以指定 ScaleStrategy.MaxUnavailable 来限制扩容的步长,以达到服务应用影响最小化的目的。 它可以设置为一个绝对值或者百分比,如果不填,则 Kruise 会设置为默认值为 nil,即表示不设限制。该字段可以配合 Spec.MinReadySeconds 字段使用:
apiVersion: apps.kruise.io/v1alpha1
kind: CloneSet
spec:
# ...
minReadySeconds: 60
scaleStrategy:
maxUnavailable: 1在扩容时,只有当上一个扩容出的 Pod 已经 Ready 超过一分钟后,CloneSet 才会执行创建下一个 Pod 的操作。
升级功能
升级类型
- ReCreate: 控制器会删除旧 Pod 和它的 PVC,然后用新版本重新创建出来。默认。
- InPlaceIfPossible: 控制器会优先尝试原地升级 Pod,如果不行再采用重建升级。当前, 仅支持容器镜像等字段的原地升级。
- InPlaceOnly: 控制器只允许采用原地升级。因此,用户只能修改容器镜像等字段,如果尝试修改其他字段会被 Kruise 拒绝。
Partition 分批灰度
Partition 的语义是 保留旧版本 Pod 的数量或百分比,默认为 0。这里的 partition 不表示任何 order 序号。
如果在发布过程中设置了 partition:
- 如果是数字,控制器会将 (replicas – partition) 数量的 Pod 更新到最新版本。
- 如果是百分比,控制器会将 (replicas * (100% – partition)) 数量的 Pod 更新到最新版本。
# 更新镜像并设置 partition
updateStrategy:
type: InPlaceIfPossible
partition: 1
查看status,updateRevision 已经更新为 sample-data-59478cbd7 新的值。
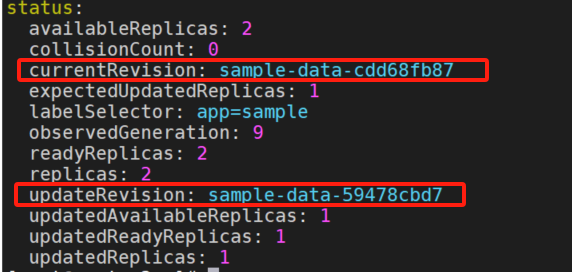
通过 partition 回滚
默认情况下,partition 只控制 Pod 更新到 status.updateRevision 新版本。上面设置了partition: 1,如果把 partition 修改为2改回去,CloneSet 不会做任何事情。
但是如果你启用了 CloneSetPartitionRollback 这个 feature-gate,上面这个场景下 CloneSet 会把 2 个 status.updateRevision 版本的 Pod 重新回滚为 status.currentRevision 版本。
升级顺序
当控制器选择 Pod 做升级时,默认是有一套根据 Pod phase/conditions 的排序逻辑: unscheduled < scheduled, pending < unknown < running, not-ready < ready。 在此之外,CloneSet 也提供了增强的 priority(优先级) 和 scatter(打散) 策略来允许用户自定义发布顺序。但是无论是哪个都要求对特定一些 Pod 打标。
updateStrategy:
priorityStrategy:
weightPriority:
- weight: 50
matchSelector:
matchLabels:
test-key: foo
- weight: 30
matchSelector:
matchLabels:
test-key: bar
updateStrategy:
priorityStrategy:
orderPriority:
- orderedKey: some-label-key
updateStrategy:
scatterStrategy:
- key: foo
value: bar发布暂停
用户可以通过设置 paused 为 true 暂停发布,不过控制器还是会做 replicas 数量管理:
apiVersion: apps.kruise.io/v1alpha1
kind: CloneSet
spec:
# ...
updateStrategy:
paused: true原地升级自动预热
如果启用了 PreDownloadImageForInPlaceUpdate feature-gate, CloneSet 控制器会自动在所有旧版本 pod 所在 node 节点上预热你正在灰度发布的新版本镜像。 这对于应用发布加速很有帮助。
helm upgrade kruise --set featureGates="RecreatePodWhenChangeVCTInCloneSetGate=true\,PreDownloadImageForInPlaceUpdate=true" .
默认情况下 CloneSet 每个新镜像预热时的并发度都是 1,也就是一个个节点拉镜像。如果需要调整,你可以通过 apps.kruise.io/image-predownload-parallelism annotation 来设置并发度。
另外从 Kruise v1.1.0 开始,你可以使用 apps.kruise.io/image-predownload-min-updated-ready-pods 来控制在少量新版本 Pod 已经升级成功之后再执行镜像预热。它的值可能是绝对值数字或是百分比。
apiVersion: apps.kruise.io/v1alpha1
kind: CloneSet
metadata:
annotations:
apps.kruise.io/image-predownload-parallelism: "10"
apps.kruise.io/image-predownload-min-updated-ready-pods: "3"为了避免大部分不必要的镜像拉取,目前只针对 replicas > 3 的 CloneSet 做自动预热。
生命周期钩子
每个 CloneSet 管理的 Pod 会有明确所处的状态,在 Pod label 中的 lifecycle.apps.kruise.io/state 标记:
- Normal:正常状态
- PreparingUpdate:准备原地升级
- Updating:原地升级中
- Updated:原地升级完成
- PreparingDelete:准备删除
生命周期钩子是通过在上述状态流转中卡点,来实现原地升级前后、删除前的自定义操作(比如开关流量、告警等)。
type LifecycleStateType string
// Lifecycle contains the hooks for Pod lifecycle.
type Lifecycle struct
// PreDelete is the hook before Pod to be deleted.
PreDelete *LifecycleHook `json:"preDelete,omitempty"`
// InPlaceUpdate is the hook before Pod to update and after Pod has been updated.
InPlaceUpdate *LifecycleHook `json:"inPlaceUpdate,omitempty"`
// PreNormal is the hook after Pod to be created and ready to be Normal.
PreNormal *LifecycleHook `json:"preNormal,omitempty"`
}
type LifecycleHook struct {
LabelsHandler map[string]string `json:"labelsHandler,omitempty"`
FinalizersHandler []string `json:"finalizersHandler,omitempty"`
/********************** FEATURE STATE: 1.2.0 ************************/
// MarkPodNotReady = true means:
//- Pod will be set to 'NotReady' at preparingDelete/preparingUpdate state.
// - Pod will be restored to 'Ready' at Updated state if it was set to 'NotReady' at preparingUpdate state.
// Currently, MarkPodNotReady only takes effect on InPlaceUpdate & PreDelete hook.
// Default to false.
MarkPodNotReady bool `json:"markPodNotReady,omitempty"`
/*********************************************************************/
}Lifecycle 示例如下:
apiVersion: apps.kruise.io/v1alpha1
kind: CloneSet
spec:
lifecycle:
preNormal:
finalizersHandler:
- example.io/unready-blocker
preDelete:
finalizersHandler:
- example.io/unready-blocker
inPlaceUpdate:
finalizersHandler:
- example.io/unready-blocker
# 或者也可以通过 label 定义
# lifecycle:
# inPlaceUpdate:
# labelsHandler:
# example.io/block-unready: "true"
# ...
用户 controller 的逻辑如下:- 对于刚创建出来的 Pod,其会处于
PreparingNormal状态,当检查该 Pod 满足Available的标准后,将example.io/unready-blocker添加到 Pod 上, Pod 会转入 Normal 的可用状态。 - 对于
PreparingDelete和PreparingUpdate状态的 Pod,切走流量,并去除example.io/unready-blockerfinalizer - 对于 Updated 状态的 Pod,接入流量,并打上
example.io/unready-blockerfinalizer
升级/删除 Pod 前将其置为 NotReady
lifecycle:
preDelete:
markPodNotReady: true
finalizersHandler:
- example.io/unready-blocker
inPlaceUpdate:
markPodNotReady: true
finalizersHandler:
- example.io/unready-blocker- 如果设置
preDelete.markPodNotReady=true:- Kruise 将会在 Pod 进入
PreparingDelete状态时,将KruisePodReady这个 Pod Condition 设置为 False, Pod 将变为 NotReady。
- Kruise 将会在 Pod 进入
- 如果设置
inPlaceUpdate.markPodNotReady=true:- Kruise 将会在 Pod 进入
PreparingUpdate状态时,将KruisePodReady这个 Pod Condition 设置为 False, Pod 将变为 NotReady。 - Kruise 将会尝试将
KruisePodReady这个 Pod Condition 设置回 True。
用户可以利用这一特性,在容器真正被停止之前将 Pod 上的流量先行排除,防止流量损失。
- Kruise 将会在 Pod 进入
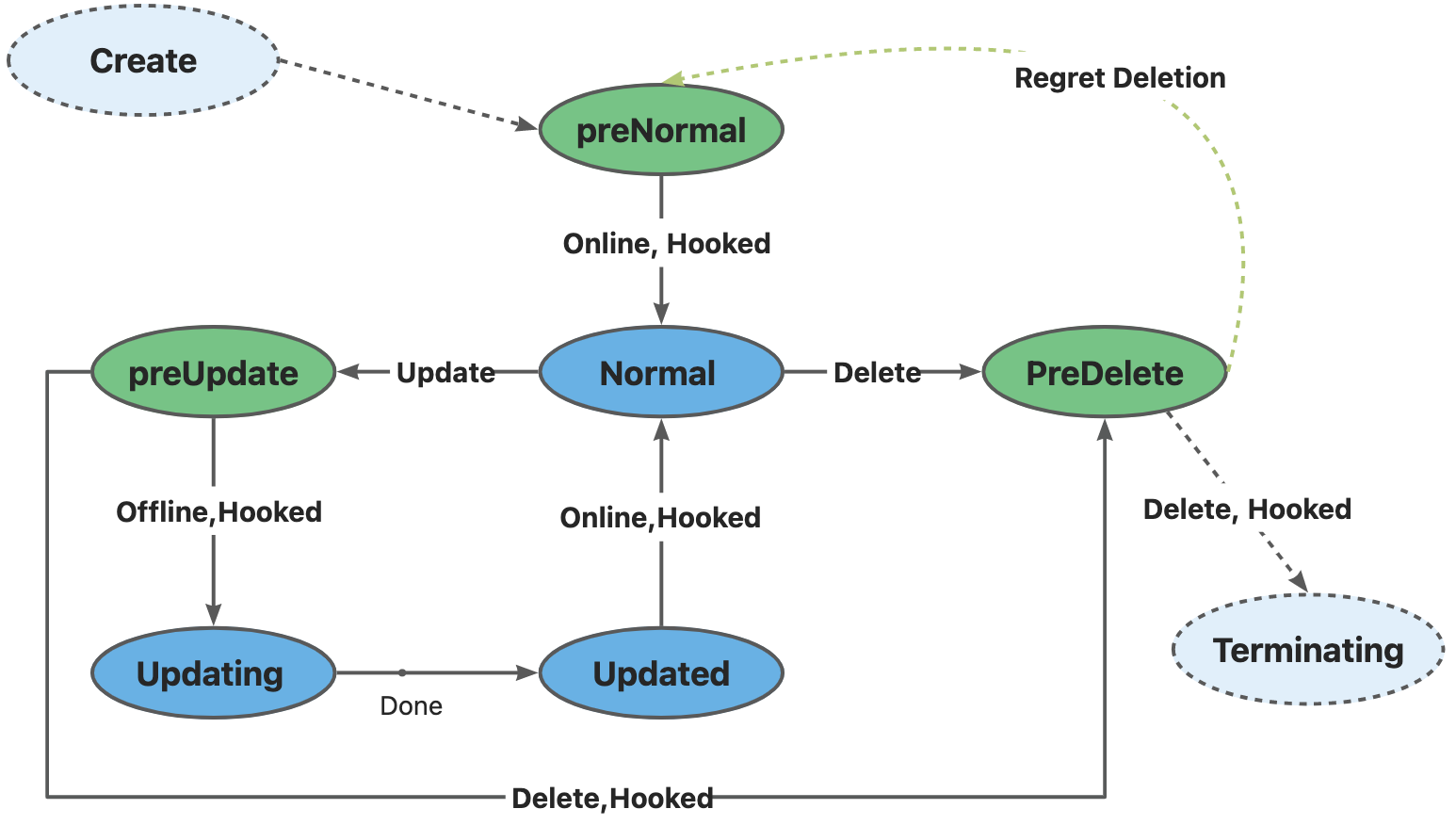
- 当 CloneSet 创建一个 Pod(包括正常扩容和重建升级)时:
- 如果 Pod 满足了 PreNormal hook 的定义,才会被认为是 Available,并且才会进入 Normal 状态;
- 这对于一些 Pod 创建时的后置检查很有用,比如你可以检查Pod是否已经挂载到SLB后端,从而避免滚动升级时,旧实例销毁后,新实例挂载失败导致的流量损失;
- 当 CloneSet 删除一个 Pod(包括正常缩容和重建升级)时:
- 如果没有定义 lifecycle hook 或者 Pod 不符合
preDelete条件,则直接删除 - 否则,先只将 Pod 状态改为
PreparingDelete。等用户 controller 完成任务去掉 label/finalizer、Pod 不符合preDelete条件后,kruise 才执行 Pod 删除 - 注意:
PreparingDelete状态的 Pod 处于删除阶段,不会被升级
- 如果没有定义 lifecycle hook 或者 Pod 不符合
- 当 CloneSet 原地升级一个 Pod 时:
- 升级之前,如果定义了 lifecycle hook 且 Pod 符合
inPlaceUpdate条件,则将 Pod 状态改为PreparingUpdate - 等用户 controller 完成任务去掉 label/finalizer、Pod 不符合
inPlaceUpdate条件后,kruise 将 Pod 状态改为 Updating 并开始升级 - 升级完成后,如果定义了 lifecycle hook 且 Pod 不符合
inPlaceUpdate条件,将 Pod 状态改为 Updated - 等用户 controller 完成任务加上 label/finalizer、Pod 符合
inPlaceUpdate条件后,kruise 将 Pod 状态改为 Normal 并判断为升级成功
- 升级之前,如果定义了 lifecycle hook 且 Pod 符合
Advanced StatefulSet
这个控制器基于原生 StatefulSet 上增强了发布能力,比如 maxUnavailable 并行发布、原地升级等。注意 Advanced StatefulSet 是一个 CRD,kind 名字也是 StatefulSet,但是 apiVersion 是 apps.kruise.io/v1beta1。因此,用户从原生 StatefulSet 迁移到 Advanced StatefulSet,只需要把 apiVersion 修改后提交即可。
- apiVersion: apps/v1
+ apiVersion: apps.kruise.io/v1beta1
kind: StatefulSet
metadata:
name: sample
spec:
#...Pod 标识
序号索引
对于具有 N 个副本的 StatefulSet,该 StatefulSet 中的每个 Pod 将被分配一个整数序号,该序号在此 StatefulSet 中是唯一的。 默认情况下,这些 Pod 将被赋予从 0 到 N-1 的序号。StatefulSet 控制器也会添加一个包含此索引的 Pod 标签:apps.kubernetes.io/pod-index

起始序号
Pod 起始序号默认都是从 0 开始的,此外,你也可以通过设置 .spec.ordinals.start 字段来设置 Pod 起始序号。使用该能力,你需要开启 FeatureGate StatefulSetStartOrdinal=true。
这里开启所有的featureGates方便测试。
helm upgrade kruise --set featureGates="AllAlpha=true" .但是kruise-controller-manager会报错起不来。查看日志manager在webhook认证时报错外部证书不匹配。

需要关闭featureGates=EnableExternalCerts=false,使用内部自签名证书不使用外部ca认证。
helm upgrade kruise --set featureGates="EnableExternalCerts=false\,AllAlpha=true" .
spec.ordinals.start:如果 .spec.ordinals.start 字段被设置,则 Pod 将被分配从 .spec.ordinals.start 到 .spec.ordinals.start + .spec.replicas – 1 的序号。 比如:replicas=5、ordinals.start=3,Pod 序号 = [3, 7]。
apiVersion: apps.kruise.io/v1beta1
kind: StatefulSet
metadata:
name: sample
spec:
replicas: 5
ordinals:
start: 3
用途
- 跨namespace迁移
假如有5个sts pod在shared空间下运行,现在需要迁移两个pod到app-team空间。
name: my-app
namespace: shared
replicas: 5
-----------------------------------------------
[ nginx-0, nginx-1, nginx-2, nginx-3, nginx-4 ]为了迁移两个pod,可将共享命名空间中的 my-app StatefulSet 缩减为 replicas: 3, ordinals.start: 0,app-team命名空间中的 StatefulSet 可调整为为 replicas: 2, ordinals.start: 3 ,如下:
name: my-app name: my-app
namespace: shared namespace: app-team
replicas: 3 replicas: 2
ordinals.start: 0 ordinals.start: 3
------------------------------ ---------------------
[ nginx-0, nginx-1, nginx-2 ] [ nginx-3, nginx-4 ]- 跨集群迁移:由于容量限制、基础设施限制或为了更好地隔离应用程序,采用多集群的方式可能需要在集群间移动工作负载。
- 从1开始编号而不是0。
扩缩容功能
PVC保留
需要启用 StatefulSetAutoDeletePVC feature-gate, 你可以使用 .spec.persistentVolumeClaimRetentionPolicy 字段来控制在StatefulSet生命周期中是否以及何时删除它所创建的PVC。

删除pod,可以看到pvc并没有被删除。

需要添加spec.persistentVolumeClaimRetentionPolicy字段。
persistentVolumeClaimRetentionPolicy:
whenDeleted: Delete
whenScaled: Delete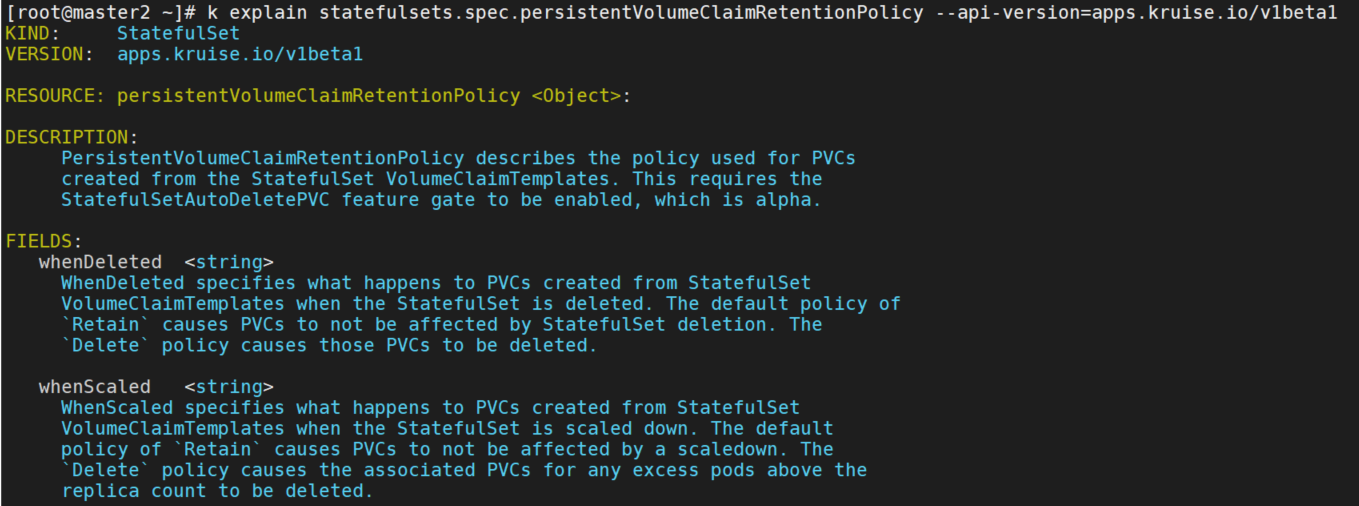
可以看到pod和pvc一起都被删除了。

流式扩容
为了避免在一个新 Advanced StatefulSet 创建后有大量失败的 pod 被创建出来,从 Kruise v0.10.0 版本开始引入了在 scale strategy 中的 maxUnavailable 策略。当这个字段被设置之后,Advanced StatefulSet 会保证创建 pod 之后不可用 pod 数量不超过这个限制值。
apiVersion: apps.kruise.io/v1beta1
kind: StatefulSet
spec:
# ...
replicas: 100
scaleStrategy:
maxUnavailable: 10% # percentage or absolute number上面这个 StatefulSet 一开始只会一次性创建 10 个 pod。在此之后,每当一个 pod 变为 running、ready 状态后,才会再创建一个新 pod 出来。
注意,这个功能只允许在 podManagementPolicy 是 Parallel 的 StatefulSet 中使用。

默认是OrderedReady即按照顺序并等待pod ready后再逐个创建或删除。Parallel即为并行,不再等待pod是否为ready状态,只按照期望数量创建,删除时全部删除。
序号保留(跳过)
通过在 reserveOrdinals 字段中写入需要保留的序号,Advanced StatefulSet 会自动跳过创建这些序号的 Pod。如果 Pod 已经存在,则会被删除。 注意,spec.replicas 是期望运行的 Pod 数量,spec.reserveOrdinals 是要跳过的序号。
apiVersion: apps.kruise.io/v1beta1
kind: StatefulSet
metadata:
name: sample
spec:
replicas: 3
reserveOrdinals:
- 1可以看到只有sample-0,2,3。

- 如果要把 sample-2 做迁移并保留序号,则把 2 追加到
reserveOrdinals列表中。控制器会把 sample-2 删除并创建 sample-4(此时运行中 Pod 为 [0,3,4])。

- 如果只想删除 sample-2,则把 2 追加到
reserveOrdinals列表并同时把 replicas 减一修改为 2。控制器会把 sample-2 删除(此时运行中 Pod 为 [0,3])。


指定 Pod 删除
相比于手动直接删除 Pod,使用 apps.kruise.io/specified-delete: true 指定 Pod 删除方式会有 Advanced StatefulSet 的 maxUnavailable 来保护删除, 并且会触发 PreparingDelete 生命周期 hook。
apiVersion: v1
kind: Pod
metadata:
labels:
apps.kruise.io/specified-delete: true当控制器收到上面这个 Pod 更新之后,会优先处理存在指定删除标签的 pod 的删除流程,并保证不突破 maxUnavailable 的限制。
升级功能
原地升级
Advanced StatefulSet 增加了 podUpdatePolicy 来允许用户指定重建升级还是原地升级。
- ReCreate: 控制器会删除旧 Pod 和它的 PVC,然后用新版本重新创建出来。
- InPlaceIfPossible: 控制器会优先尝试原地升级 Pod,如果不行再采用重建升级。
- InPlaceOnly: 控制器只允许采用原地升级。因此,用户只能修改上一条中的限制字段,如果尝试修改其他字段会被 Kruise 拒绝。
还可以使用 graceful period 选项,作为优雅原地升级的策略。用户如果配置了 gracePeriodSeconds 这个字段,控制器在原地升级的过程中会先把 Pod status 改为 not-ready,然后等一段时间(gracePeriodSeconds),最后再去修改 Pod spec 中的镜像版本。 这样,就为 endpoints-controller 这些控制器留出了充足的时间来将 Pod 从 endpoints 端点列表中去除。
如果使用 InPlaceIfPossible 或 InPlaceOnly 策略,必须要增加一个 InPlaceUpdateReady readinessGate,用来在原地升级的时候控制器将 Pod 设置为 NotReady。
apiVersion: apps.kruise.io/v1beta1
kind: StatefulSet
metadata:
name: sample
spec:
replicas: 3
serviceName: nginx-service
selector:
matchLabels:
app: sample
template:
metadata:
labels:
app: sample
spec:
containers:
- name: main
image: nginx:stable-alpine
imagePullPolicy: IfNotPresent
readinessGates:
# A new condition that ensures the pod remains at NotReady state while the in-place update is happening
- conditionType: InPlaceUpdateReady
podManagementPolicy: Parallel # allow parallel updates, works together with maxUnavailable
updateStrategy:
type: RollingUpdate
rollingUpdate:
# Do in-place update if possible, currently only image update is supported for in-place update
podUpdatePolicy: InPlaceIfPossible
# Allow parallel updates with max number of unavailable instances equals to 2
maxUnavailable: 2
volumeClaimTemplates:
- metadata:
name: data
spec:
accessModes: [ "ReadWriteOnce" ]
resources:
requests:
storage: 2Gi
persistentVolumeClaimRetentionPolicy:
whenDeleted: Delete
whenScaled: Delete原地升级成功。
原地升级自动预热
启用了 PreDownloadImageForInPlaceUpdate feature-gate, Advanced StatefulSet 控制器会自动在所有旧版本 pod 所在 node 节点上预热你正在灰度发布的新版本镜像。 这对于应用发布加速很有帮助。
默认情况下 Advanced StatefulSet 每个新镜像预热时的并发度都是 1,也就是一个个节点拉镜像。 如果需要调整,你可以通过 apps.kruise.io/image-predownload-parallelism annotation 来设置并发度。
可以使用 apps.kruise.io/image-predownload-min-updated-ready-pods 来控制在少量新版本 Pod 已经升级成功之后再执行镜像预热。它的值可能是绝对值数字或是百分比。
apiVersion: apps.kruise.io/v1beta1
kind: StatefulSet
metadata:
annotations:
apps.kruise.io/image-predownload-parallelism: "10"
apps.kruise.io/image-predownload-min-updated-ready-pods: "3"为了避免大部分不必要的镜像拉取,目前只针对 replicas > 3 的 Advanced StatefulSet 做自动预热。
升级顺序
Advanced StatefulSet 在 spec.updateStrategy.rollingUpdate 下面新增了 unorderedUpdate 结构,提供给不按 order 顺序的升级策略。 如果 unorderedUpdate 不为空,所有 Pod 的发布顺序就不一定会按照 order 顺序了。注意,unorderedUpdate 只能配合 Parallel podManagementPolicy 使用。目前,unorderedUpdate 下面只包含 priorityStrategy 一个优先级策略。策略和CloneSet一致,可以通过 weight(权重) 和 order(序号) 两种方式来指定。
发布暂停
用户可以通过设置 paused 为 true 暂停发布,不过控制器还是会做 replicas 数量管理:
apiVersion: apps.kruise.io/v1beta1
kind: StatefulSet
spec:
updateStrategy:
rollingUpdate:
paused: true生命周期钩子
与 CloneSet 能力相似。
Advanced DaemonSet
Advanced DaemonSet 基于原生 DaemonSet 上增强了发布能力,比如 灰度分批、按 Node label 选择、暂停、热升级等。kind 名字也是 DaemonSet,但是 apiVersion 是 apps.kruise.io/v1alpha1。用户从原生 DaemonSet 迁移到 Advanced DaemonSet,只需要把 apiVersion 修改后提交即可。
- apiVersion: apps/v1
+ apiVersion: apps.kruise.io/v1alpha1
kind: DaemonSet
metadata:
name: sample-ds
spec:升级方式
k explain DaemonSet.spec.updateStrategy.rollingUpdate --api-version=apps.kruise.io/v1alpha1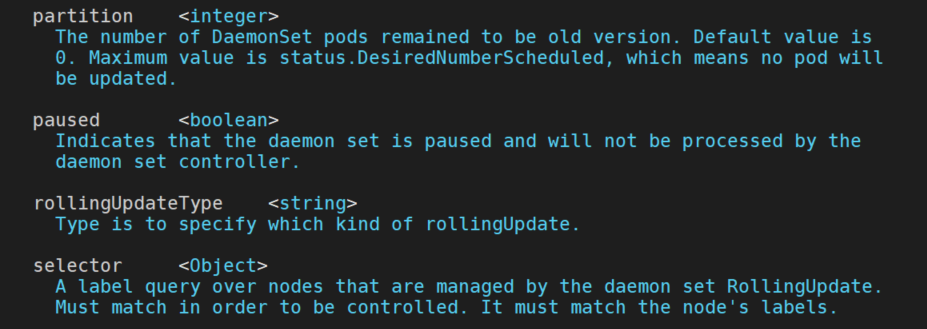
rollingUpdateType 字段标识了如何进行滚动升级:
- Standard (默认): 对于每个 node,控制器会先删除旧的 daemon Pod,再创建一个新 Pod,和原生 DaemonSet 行为一致。你可以通过 maxUnavailable 或 maxSurge 来控制重建新旧 Pod 的顺序。
- Surging: 对于每个 node,控制器会先创建一个新 Pod,等它 ready 之后再删除老 Pod。
- InPlaceIfPossible: 控制器会尽量采用原地升级的方式,如果不行则重建升级。请阅读该文档了解更多原地升级的细节。 注意,在这个类型下,只能使用 maxUnavailable 而不能用 maxSurge。
apiVersion: apps.kruise.io/v1alpha1
kind: DaemonSet
spec:
updateStrategy:
type: RollingUpdate
rollingUpdate:
rollingUpdateType: StandardSelector 标签选择升级
这个策略支持用户通过配置 node 标签的 selector,来指定灰度升级某些特定类型 node 上的 Pod。
apiVersion: apps.kruise.io/v1alpha1
kind: DaemonSet
spec:
updateStrategy:
type: RollingUpdate
rollingUpdate:
selector:
matchLabels:
nodeType: canary分批灰度升级或扩容
Partition 的语义是 保留旧版本 Pod 的数量,默认为 0。 如果在发布过程中设置了 partition,则控制器只会将 (status.DesiredNumberScheduled – partition) 数量的 Pod 更新到最新版本。
apiVersion: apps.kruise.io/v1alpha1
kind: DaemonSet
spec:
updateStrategy:
type: RollingUpdate
rollingUpdate:
partition: 10暂停升级
用户可以通过设置 paused 为 true 暂停发布,不过控制器还是会做 replicas 数量管理:
apiVersion: apps.kruise.io/v1alpha1
kind: DaemonSet
spec:
updateStrategy:
rollingUpdate:
paused: true升级镜像自动预热
启用了 PreDownloadImageForDaemonSetUpdate feature-gate, DaemonSet 控制器会自动在所有旧版本 pod 所在 node 节点上预热你正在灰度发布的新版本镜像。通过apps.kruise.io/image-predownload-parallelism: "10"来设置并发度。
生命周期钩子
与 CloneSet 提供的生命周期钩子 能力相似。目前 Advanced DaemonSet 只支持 PreDelete hook,它允许用户在 daemon Pod 被删除前执行一些自定义的逻辑。
apiVersion: apps.kruise.io/v1alpha1
kind: DaemonSet
spec:
template:
metadata:
labels:
example.io/block-deleting: "true"
lifecycle:
preDelete:
labelsHandler:
example.io/block-deleting: "true"当 DaemonSet 删除一个 Pod 时(包括缩容和重建升级):
- 如果没有定义 lifecycle hook 或者 Pod 不符合 preDelete 条件,则直接删除
- 否则,会先将 Pod 更新为 PreparingDelete 状态,并等待用户的 controller 将 Pod 中关联的 label/finalizer 去除,再执行 Pod 删除
apiVersion: v1
kind: Pod
metadata:
labels:
example.io/block-deleting: "true" # the pod is hooked by PreDelete hook label
lifecycle.apps.kruise.io/state: PreparingDelete # so we update it to `PreparingDelete` state and wait for user controller to do something and remove the labelcontroller 逻辑示例:当发现 Pod 进入 PreparingDelete 状态,检查它的节点是否存在,并执行一些处理逻辑(例如资源预留等),最后将 Pod 中的 example.io/block-deleting label 去掉。
BroadcastJob
这个控制器将 Pod 分发到集群中每个 node 上,类似于 DaemonSet, 但是 BroadcastJob 管理的 Pod 并不是长期运行的 daemon 服务,而是类似于 Job 的任务类型 Pod。
最终在每个 node 上的 Pod 都执行完成退出后,BroadcastJob 和这些 Pod 并不会占用集群资源。 这个控制器非常有利于做升级基础软件、巡检等过一段时间需要在整个集群中跑一次的工作。
此外,BroadcastJob 还可以维持每个 node 跑成功一个 Pod 任务。如果采取这种模式,当后续集群中新增 node 时 BroadcastJob 也会分发 Pod 任务上去执行。
Spec
Template
Template 描述了 Pod 模板,用于创建任务 Pod。 注意,由于是任务类型的 Pod,其中的 restart policy 只能设置为 Never 或 OnFailure,不允许设为 Always。
Parallelism
Parallelism 指定了最多能允许多少个 Pod 同时在执行任务,默认不做限制。
比如,一个集群里有 10 个 node、并设置了 Parallelism 为 3,那么 BroadcastJob 会保证同时只会有 3 个 node 上的 Pod 在执行。每当一个 Pod 执行完成,BroadcastJob 才会创建一个新 Pod 执行。
CompletionPolicy
CompletionPolicy 支持指定 BroadcastJob 控制器的 reconciling 行为,可以设置为 Always 或 Never:
- Always 策略意味着 job 最终会完成,不管是执行成功还是失败了。在 Always 策略下还可以设置以下参数:
ActiveDeadlineSeconds:指定一个超时时间,如果 BroadcastJob 开始运行超过了这个时间,所有还在跑着的 job 都会被停止、并标记为失败。TTLSecondsAfterFinished限制了 BroadcastJob 在完成之后的存活时间,默认没有限制。比如设置了TTLSecondsAfterFinished为 10s,那么当 job 结束后超过了 10s,控制器就会把 job 和下面的所有 Pod 删掉。
- Never 策略意味着 BroadcastJob 永远都不会结束(标记为 Succeeded 或 Failed),即使当前 job 下面的 Pod 都已经执行成功了。 这也意味着
ActiveDeadlineSeconds、TTLSecondsAfterFinished、FailurePolicy.RestartLimit这三个参数是不能使用的。比如说,用户希望对集群中每个 node 都下发一个配置,包括后续新增的 node 都需要做,那么就可以创建一个 Never 策略的 BroadcastJob。
FailurePolicy
Type 表示的 FailurePolicyType 类型。
- Continue"(继续)表示当发现失败的 pod 时,作业仍在运行。
- FailFast"(快速失败)表示当发现失败的 pod 时,作业将失败。
- Pause"(暂停)表示当发现失败的 pod 时,作业将被暂停。
RestartLimit(重启限制)指定标记 pod 失败前的重试次数。 目前,重试次数定义为由 Pod 内所有容器的重启次数 ContainerStatus.RestartCount之和。 如果该值超过 RestartLimit(重启限制),该任务将被标记为为失败,所有正在运行的 Pod 将被删除。如果未设置 RestartLimit 未设置,则不执行限制。
例子
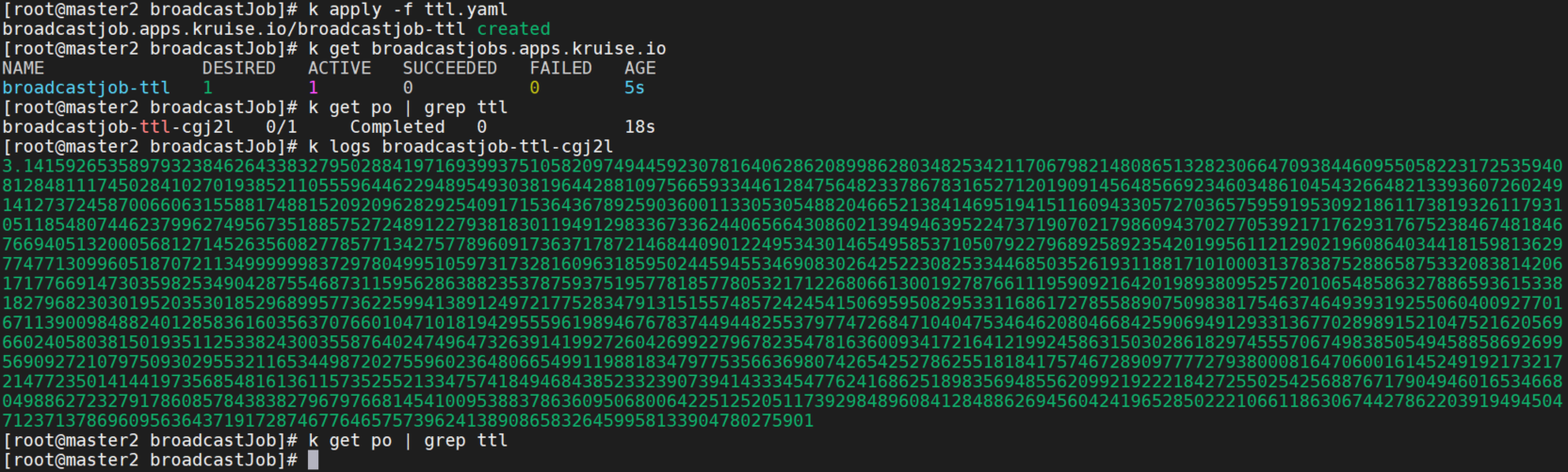
ttlSecondsAfterFinished
配置 ttlSecondsAfterFinished 为 30。 这个 job 会在执行结束后 30s 被删除。
apiVersion: apps.kruise.io/v1alpha1
kind: BroadcastJob
metadata:
name: broadcastjob-ttl
spec:
template:
spec:
containers:
- name: pi
image: perl:latest
imagePullPolicy: IfNotPresent
command: ["perl", "-Mbignum=bpi", "-wle", "print bpi(2000)"]
restartPolicy: Never
completionPolicy:
type: Always
ttlSecondsAfterFinished: 30可以看到 Desired : 期望的 Pod 数量,Active: 运行中的 Pod 数量,SUCCEEDED: 执行成功的 Pod 数量,FAILED: 执行失败的 Pod 数量。pod和broadcastjobs在30s后都被删除了。
activeDeadlineSeconds
配置 activeDeadlineSeconds 为 10。 这个 job 会在运行超过 10s 之后被标记为失败,并把下面还在运行的 Pod 删除掉。
apiVersion: apps.kruise.io/v1alpha1
kind: BroadcastJob
metadata:
name: broadcastjob-active-deadline
spec:
template:
spec:
containers:
- name: sleep
image: busybox:latest
imagePullPolicy: IfNotPresent
command: ["sleep", "50000"]
restartPolicy: Never
completionPolicy:
type: Always
activeDeadlineSeconds: 10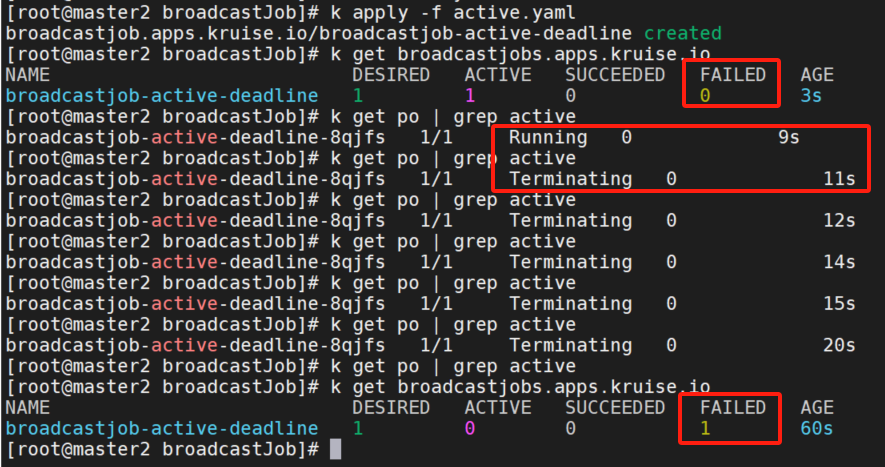
completionPolicy
配置 completionPolicy 为 Never。 这个 job 会持续运行即使当前所有 node 上的 Pod 都执行完成了。
apiVersion: apps.kruise.io/v1alpha1
kind: BroadcastJob
metadata:
name: broadcastjob-never-complete
spec:
template:
spec:
containers:
- name: sleep
image: busybox:latest
imagePullPolicy: IfNotPresent
command: ["sleep", "5"]
restartPolicy: Never
completionPolicy:
type: Never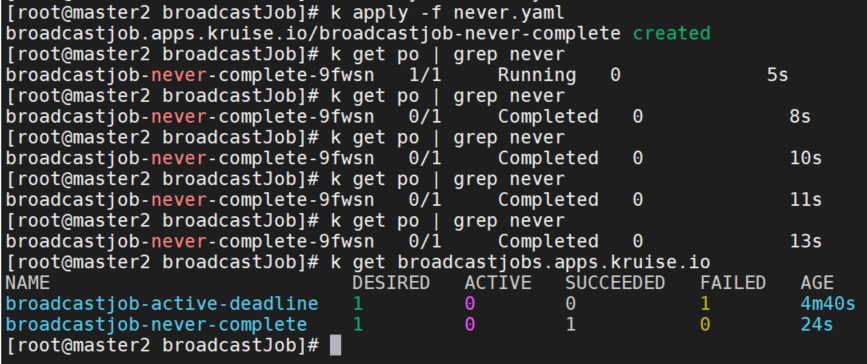
failurePolicy
创建 BroadcastJob 配置 failurePolicy 为 FailFast。 当找到失败的pod时,job将失败。
apiVersion: apps.kruise.io/v1alpha1
kind: BroadcastJob
metadata:
name: broadcastjob-restart-limit
spec:
template:
spec:
containers:
- name: sleep
image: busybox:latest
imagePullPolicy: IfNotPresent
command: ["cat", "/path/not/exist"]
restartPolicy: Never
completionPolicy:
type: Never
failurePolicy:
type: FailFast
restartLimit: 3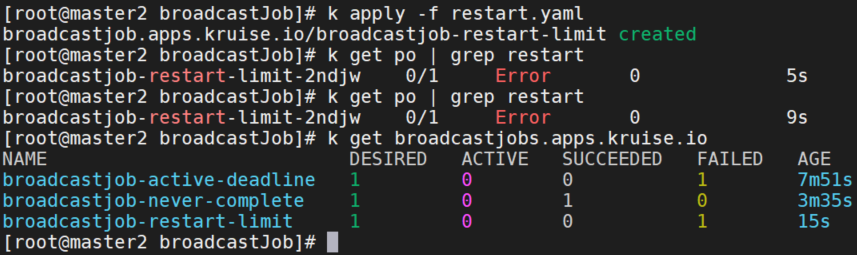
AdvancedCronJob
AdvancedCronJob 是对于原生 CronJob 的扩展版本。 后者根据用户设置的 schedule 规则,周期性创建 Job 执行任务,而 AdvancedCronJob 的 template 支持多种不同的 job 资源:
- broadcastJobTemplate:周期性创建 BroadcastJob 执行任务
- jobTemplate:与原生 CronJob 一样创建 Job 执行任务
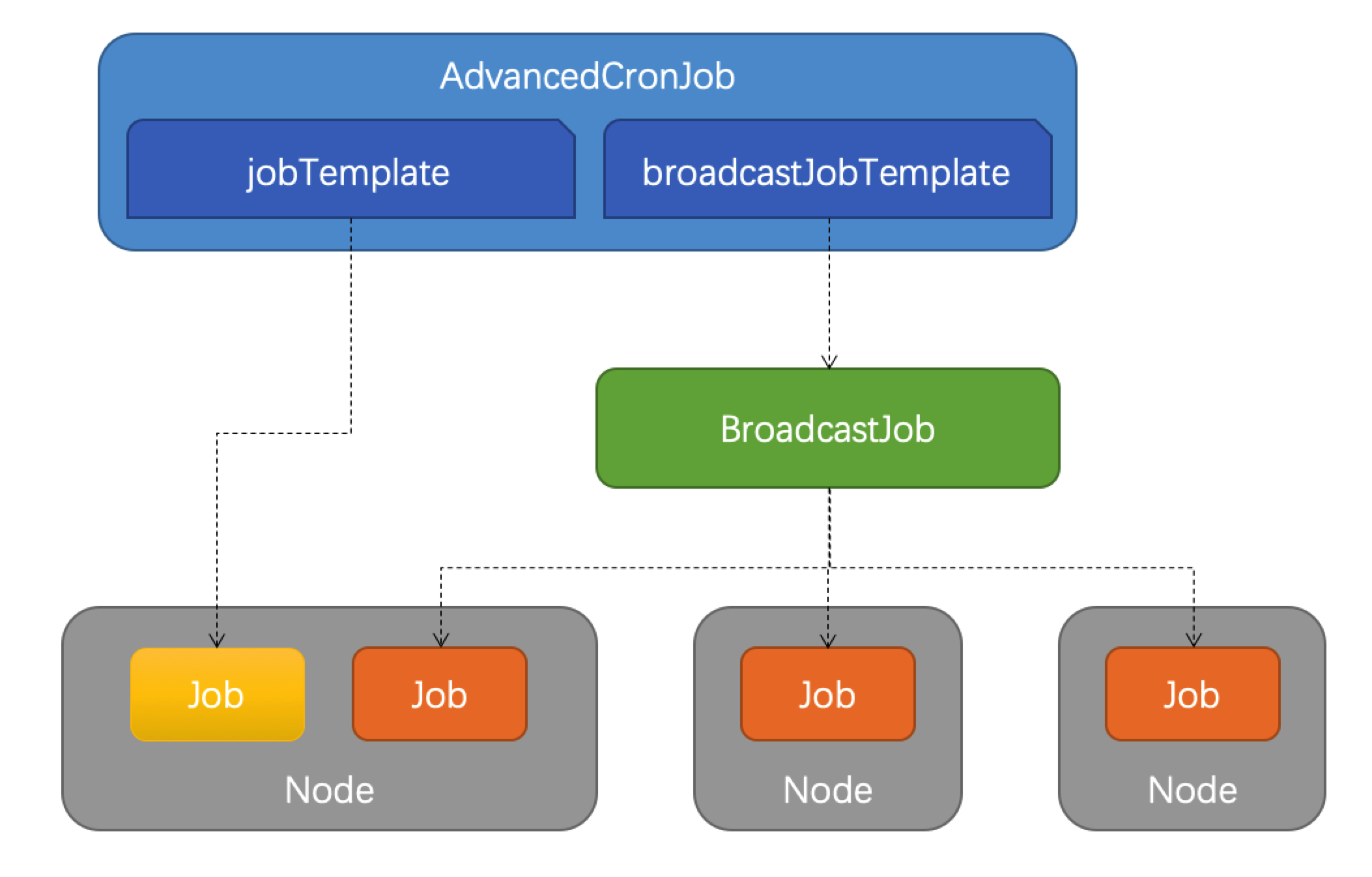
例子
下面定义了一个 AdvancedCronJob,每分钟创建一个 BroadcastJob 对象,这个 BroadcastJob 会在所有节点上运行一个 job 任务。
apiVersion: apps.kruise.io/v1alpha1
kind: AdvancedCronJob
metadata:
name: acj-test
spec:
schedule: "*/1 * * * *"
template:
broadcastJobTemplate:
spec:
template:
spec:
containers:
- name: pi
image: perl:latest
imagePullPolicy: IfNotPresent
command: ["perl", "-Mbignum=bpi", "-wle", "print bpi(2000)"]
restartPolicy: Never
completionPolicy:
type: Always
ttlSecondsAfterFinished: 30官方文档的示例直接apply会报错:Error from server: error when creating "acj.yaml": admission webhook "vadvancedcronjob.kb.io" denied the request: [spec.template.spec.containers[0].terminationMessagePolicy: Required value, spec.template.spec.dnsPolicy: Required value]

需要添加字段:
spec:
...
command: ["perl", "-Mbignum=bpi", "-wle", "print bpi(2000)"]
terminationMessagePath: /tmp/termination-log
terminationMessagePolicy: File
restartPolicy: Never
dnsPolicy: ClusterFirst- terminationMessagePath:用于设置容器终止的消息来源。即当容器退出时,Kubernetes 从容器的terminationMessagePath字段中指定的终止消息文件中检索终止消息。默认值为 /dev/termination-log。通过自定义设置terminationMessagePath,可以使得Kubernetes在容器运行成功或失败时,使用指定文件中的内容来填充容器的终止消息。终止消息内容最大为4 KB。
- terminationMessagePolicy:用于设置容器终止消息的策略。File(默认):仅从终止消息文件中检索终止消息。FallbackToLogsOnError:在容器因错误退出时,如果终止消息文件为空,则使用容器日志输出的最后一部分内容来作为终止消息。
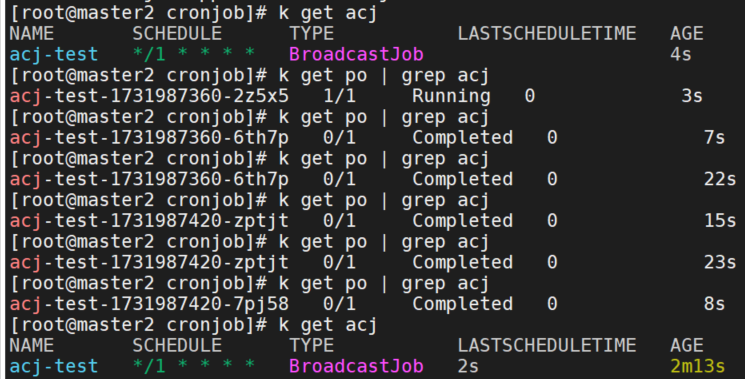
可以看到pod每一分钟运行一次。调度计划为*/1 * * * *,acj的类型为BroadcastJob,还可以看到上次调度时间LASTSCHEDULETIME。
默认情况下,所有 AdvancedCronJob schedule 调度时,都是基于 kruise-controller-manager 容器本地的时区所计算的。
不过,在 v1.3.0 版本中我们引入了 spec.timeZone 字段,你可以将它设置为任意合法时区的名字。例如,设置 spec.timeZone: "Asia/Shanghai" 则 Kruise 会根据国内的时区计算 schedule 任务触发时间。