背景
prometheus在大规模场景下的部署和后期维护麻烦且复杂,而且有些功能无法实现。由于prometheus只能存储15天的数据,超出时间的数据就无法查询了。
Thanos (灭霸)可以帮我们解决这些问题,它完全兼容 Prometheus API,提供了一些的高级特性:全局视图,长期存储,高可用。
即可以统一查询聚合分布式部署的 Prometheus 数据,同时也支持数据长期存储到各种对象存储(无限存储能力)以及降低采样率来加速大时间范围的数据查询。
架构
官方文档:https://github.com/thanos-io/thanos
https://thanos.io/tip/thanos/getting-started.md/
现在thanos有2种架构,分别是Sidecar 和 Receiver。
sidecar架构
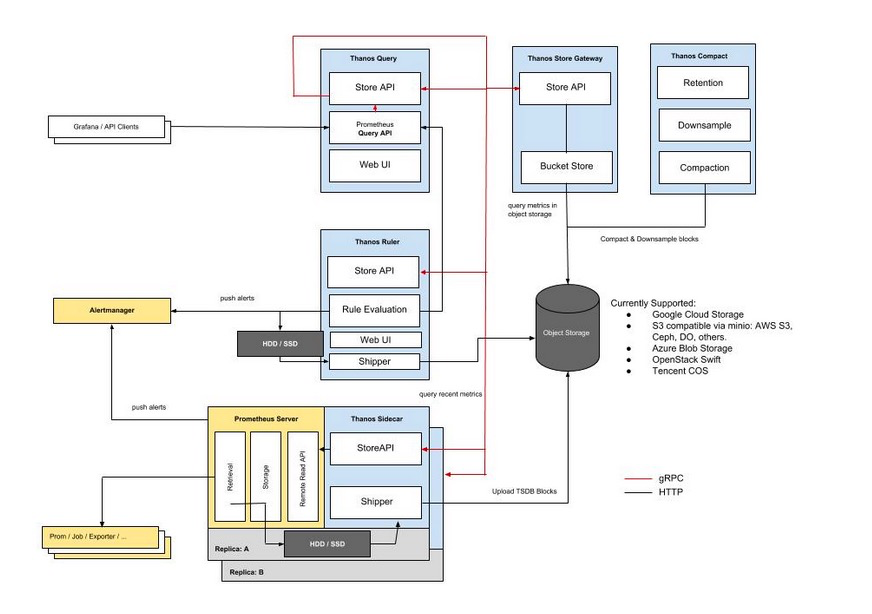
下面分别介绍一下各个组件的作用:
Thanos Query
总结:实现了 Prometheus API,将来自下游组件提供的数据进行聚合最终返回给查询数据的 client(如 Grafana),类似数据库中间件。
在大规模场景下,监控数据的查询肯定不能直接查 Prometheus 了,因为会存在许多个 Prometheus 实例,每个 Prometheus 实例只能感知它自己所采集的数据。
可以比较容易联想到数据库中间件,每个数据库都只存了一部分数据,中间件能感知到所有数据库,数据查询都经过数据库中间件来查,这个中间件收到查询请求再去查下游各个数据库中的数据,最后将这些数据聚合汇总返回给查询的客户端,这样就实现了将分布式存储的数据集中查询。
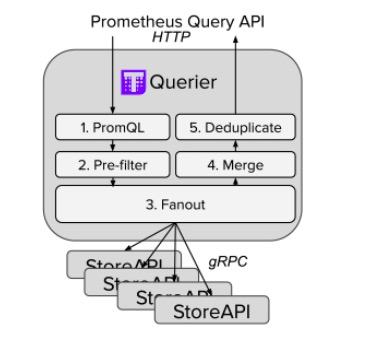
Thanos 也是使用了类似的设计思想,Thanos Query 就是这个 “中间价” 的关键入口。它实现了 Prometheus 的 HTTP API,能够 “看懂” PromQL。这样,查询 Prometheus 监控数据的 client 就不直接查询 Prometheus 本身了,而是去查询 Thanos Query,Thanos Query 再去下游多个存储了数据的地方查数据,最后将这些数据聚合去重后返回给 client,也就实现了分布式 Prometheus 的数据查询。
那么 Thanos Query 又如何去查下游分散的数据呢?Thanos 为此抽象了一套叫 Store API 的内部 gRPC 接口,其它一些组件通过这个接口来暴露数据给 Thanos Query,它自身也就可以做到完全无状态部署,实现高可用与动态扩展。
Thanos Sidecar
总结:连接 Prometheus,将其数据提供给 Thanos Query 查询,并且将其上传到对象存储,以供长期存储。
那么这些分散的数据可能来自哪些地方呢?首先,Prometheus 会将采集的数据存到本机磁盘上,如果我们直接用这些分散在各个磁盘上的数据,可以给每个 Prometheus 附带部署一个 Sidecar,这个 Sidecar 实现 Thanos Store API,当 Thanos Query 对其发起查询时,Sidecar 就读取跟它绑定部署的 Prometheus 实例上的监控数据返回给 Thanos Query。
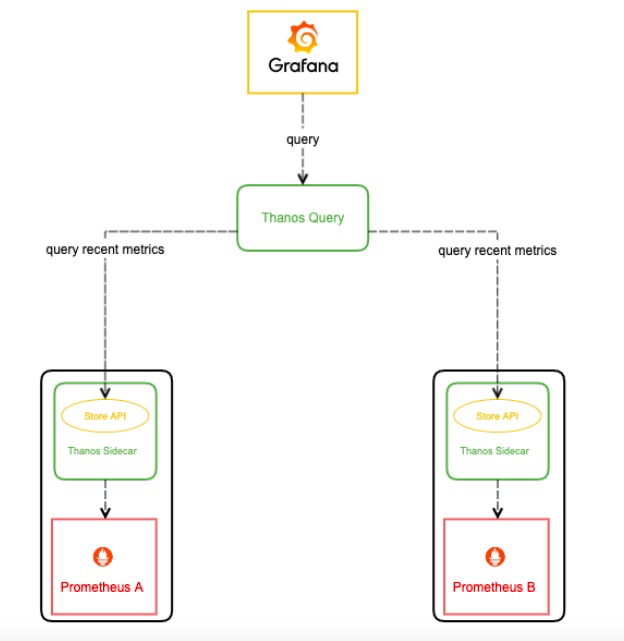
由于 Thanos Query 可以对数据进行聚合与去重,所以可以很轻松实现高可用:相同的 Prometheus 部署多个副本(都附带 Sidecar),然后 Thanos Query 去所有 Sidecar 查数据,即便有一个 Prometheus 实例挂掉过一段时间,数据聚合与去重后仍然能得到完整数据。
而且这种方式还可以很好的解决上文中大规模场景下的Prometheus高可用的缺陷,即使一个Prometheus 实例挂了一段时间然后又恢复了,它的数据也不影响整体的数据。
由于磁盘空间有限,所以 Prometheus 存储监控数据的能力也是有限的,通常会给 Prometheus 设置一个数据过期时间(默认15天)或者最大数据量大小,不断清理旧数据以保证磁盘不被撑爆。因此,我们无法看到时间比较久远的监控数据。
对于需要长期存储的数据,并且使用频率不那么高,最理想的方式是存进对象存储,各大云厂商都有OSS服务,特点是不限制容量,价格非常便宜。(阿里云OSS超出资源包的请求次数每10万次1分钱)
Thanos Sidecar 支持将数据上传到各种对象存储以供长期保存(Prometheus TSDB 数据格式)。

Thanos Store Gateway
总结:将对象存储的数据暴露给 Thanos Query 去查询。
那么这些被上传到了OSS里的监控数据该如何查询呢?理论上 Thanos Query 也可以直接去对象存储查,但会让 Thanos Query 的逻辑变的很重。
Thanos 抽象出了 Store API,只要实现了该接口的组件都可以作为 Thanos Query 查询的数据源,Thanos Store Gateway 这个组件也实现了 Store API,向 Thanos Query 暴露OSS的数据。Thanos Store Gateway 内部还做了一些加速数据获取的优化逻辑,一是缓存了 TSDB 索引,二是优化了OSS的请求(用尽可能少的请求量拿到所有需要的数据)。
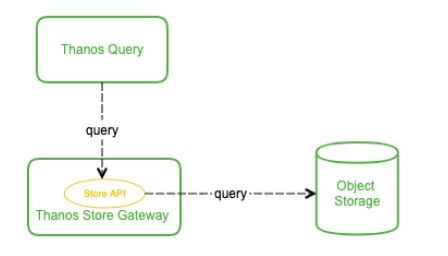
这样就实现了监控数据的长期储存,由于OSS容量无限,所以理论上我们可以存任意时长的数据,监控历史数据也就变得可追溯查询,便于问题排查与统计分析。
Thanos Ruler
总结:对监控数据进行评估和告警,还可以计算出新的监控数据,将这些新数据提供给 Thanos Query 查询并且/或者上传到对象存储,以供长期存储。
Prometheus 不仅仅只支持将采集的数据进行存储和查询的功能,还可以配置一些 rules:
- 根据配置不断计算出新指标数据并存储,后续查询时直接使用计算好的新指标,这样可以减轻查询时的计算压力,加快查询速度。
-
不断计算和评估是否达到告警阀值,当达到阀值时就通知 AlertManager 来触发告警。
Prometheus 进行分布式部署,每个 Prometheus 实例本地并没有完整数据,有些有关联的数据可能存在多个 Prometheus 实例中,单机 Prometheus 看不到数据的全局视图。
Thanos Ruler 应运而生,它通过查询 Thanos Query 获取全局数据,然后根据 rules 配置计算新指标并存储,同时也通过 Store API 将数据暴露给 Thanos Query,同样还可以将数据上传到OSS以供长期保存(这里上传到OSS中的数据一样也是通过 Thanos Store Gateway 暴露给 Thanos Query)。


看起来 Thanos Query 跟 Thanos Ruler 之间会相互查询,不过这个不冲突,Thanos Ruler 为 Thanos Query 提供计算出的新指标数据,而 Thanos Query 为 Thanos Ruler 提供计算新指标所需要的全局原始指标数据。
Thanos Compact
总结:将对象存储中的数据进行压缩和降低采样率,加速大时间区间监控数据查询的速度。
数据存储到OSS中,可以实现查询时间久远的数据。但是当时间范围很大时,查询的数据量也会很大,这会导致查询速度非常慢。通常在查看较大时间范围的监控数据时,我们并不需要那么详细的数据,只需要看到大致就行。
Thanos Compact 这个组件应运而生,它读取OSS的数据,对其进行压缩以及降采样再上传到OSS,这样在查询大时间范围数据时就可以只读取压缩和降采样后的数据,极大地减少了查询的数据量,从而加速查询。
注意
Compact 并不会减少对象存储的使用空间,而是会增加,增加更长采样间隔的监控数据,这样当查询大时间范围的数据时,就自动拉取更长时间间隔采样的数据以减少查询数据的总量,从而加快查询速度(大时间范围的数据不需要那么精细),当放大查看时(选择其中一小段时间),又自动选择拉取更短采样间隔的数据,从而也能显示出小时间范围的监控细节。
Receiver架构
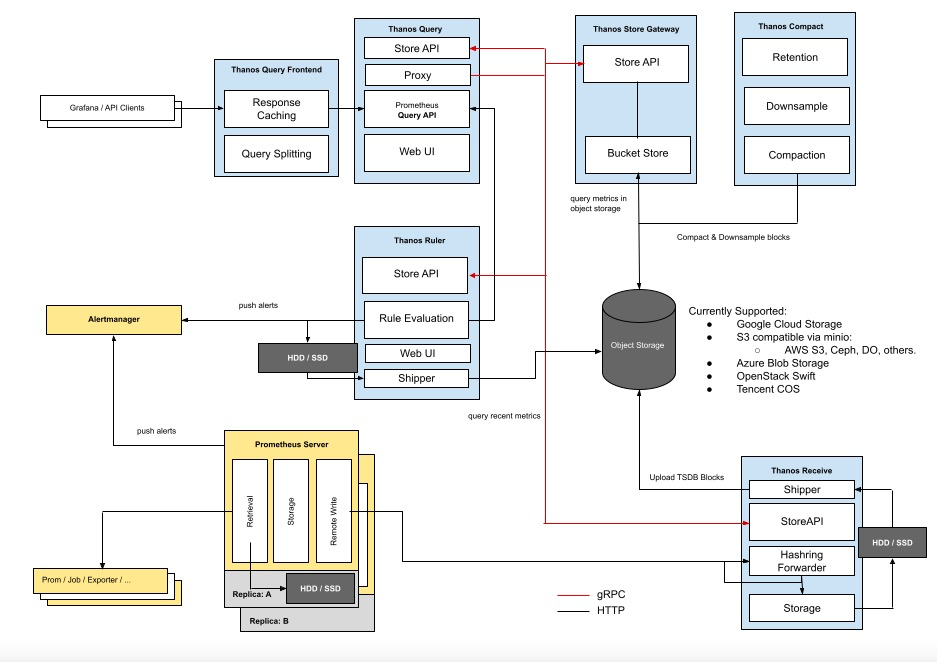
为什么需要 Receiver?它跟 Sidecar 有什么区别?
它们都可以将数据上传到OSS以供长期保存,区别在于最新数据的存储。
由于数据上传不可能实时,Sidecar 模式将最新的监控数据存到 Prometheus 本地,Query 通过调所有 Sidecar 的 Store API 来获取最新数据,这就成一个问题:如果 Sidecar 数量非常多或者 Sidecar 跟 Query 离的比较远,每次查询 Query 都调所有 Sidecar 会消耗很多资源,并且速度很慢,而我们查看监控大多数情况都是看的最新数据。
Thanos Receiver 就是为了解决这个问题,它适配了 Prometheus 的 remote write API,也就是所有 Prometheus 实例可以实时将数据 push 到 Thanos Receiver,最新数据也得以集中起来,然后 Thanos Query 也不用去所有 Sidecar 查最新数据了,直接查 Thanos Receiver 即可。另外,Thanos Receiver 也将数据上传到OSS以供长期保存,当然,OSS中的数据同样由 Thanos Store Gateway 暴露给 Thanos Query。

如果规模很大,Receiver 压力会不会很大,成为性能瓶颈?
Receiver 实现了一致性哈希(Hashing fowarder),支持集群部署,所以即使规模很大也不会成为性能瓶颈。
Sidecar 还是 Receiver
-
如果 Query 跟 Sidecar 离的比较远,比如 Sidecar 分布在多个数据中心,Query 向所有 Sidecar 查数据,速度会很慢,这种情况可以考虑用 Receiver,将数据集中吐到 Receiver,然后 Receiver 与 Query 部署在一起,Query 直接向 Receiver 查最新数据,提升查询性能。
-
如果你的使用场景只允许 Prometheus 将数据 push 到远程,可以考虑使用 Receiver。比如 IoT 设备没有持久化存储,只能将数据 push 到远程。
-
其他的场景应该都尽量使用 Sidecar 方案。
是否需要rule
Ruler 是一个可选组件,原则上推荐尽量使用 Prometheus 自带的 rule 功能(生成新指标+告警),这个功能需要一些 Prometheus 最新数据,直接使用 Prometheus 本机 rule 功能和数据,性能开销相比 Thanos Ruler 这种分布式方案小得多,并且几乎不会出错,Thanos Ruler 由于是分布式,所以更容易出错一些。
对于 alert 类型的 rule,就需要用 Thanos Ruler 来做了,因为有关联的数据分散在多个 Prometheus 上,用单机数据去做 alert 计算是不准确的,就可能会造成误告警或不告警。