背景
现在上云是一个趋势,无论是私有云还是公有云。上云之给开发和运维都有带来了非常大的好处,比如自动化运维,持续开发和部署等,这是虚拟机无法给到的。
那么应用如何上云呢?上云的过程中可能会遇到哪些问题呢?
应用容器化
应用上云最基本的要求是应用要容器化。即编写一个Dockerfile,创建你的应用镜像。
当然Dockerfile也不能乱写,不然应用可能会启动失败或者有风险。那么容器化需要考虑哪些问题呢?
主要就是这4个方面:稳定性、可用性、性能、安全。

应用本身
- 启动速度:如果应用启动速度很慢的话,既不利于应用发布也不利于故障恢复。
- 如何优化:看启动需要拉取的数据是否是必须的
- 健康检查:
- 优雅启动:liveness,readness,startup probe
- 优雅终止:如何正确处理SIGTERM。用httpget还是exec
- 启动参数:容器的启动参数也不能过长,否则可能导致容器无法启动。还有比如es需要设置java内存使用量。
Dockerfile
- 用什么作为基础镜像:基础镜像越小越好。
- 需要装哪些工具:看后续是否有调试的需求,当然也可以用busybox来进行调试。
- 多少个进程:
- 主次进程需要分清楚,哪个是决定容器状态的主进程。健康检查检查哪个进程,哪个进程控制容器的退出。
- 进程炸弹:防止应用一直fork进程,导致pid用完,pod被驱逐到了新的节点上,再次重复。
- 代码和配置分离:
- 配置如何管理:
- 传入方式:
- 环境变量env
- volume mount
- 数据来源:
- secret
- configmap
- Downward API
- 传入方式:
- 配置如何管理:
- 分层的控制:镜像层不是越多越好,层多的话性能会有损耗。把相同功能的命令放到一层去。
- Entrypoint:是容器的入口,容器启动时要去启动的进程。
容器额外开销和风险
log driver
比如docker的log driver,docker logs命令查看的容器日志就是容器内的进程中的stdout和stderr这些标准日志,再通过log driver转储到本地文件中。
这里可能会遇到一个问题:如果应用启动输出了大量的debug log,很快就把标准输出的buffer占满了,log driver也是读取这个buffer来持久化。这时就需要看log driver是处于那种模式了:
- blocking mode:
- docker默认的模式,如果数据没有及时落盘,log driver会阻塞新日志写入,就无法看到最新的日志输出。
- 应用启动变慢,需要等日志转储完。
- 如果平台有应用启动超时的配置。那么应用就可能会启动失败,而在虚拟机上是正常的。
- Non blocking mode:如果buffer满了,log driver来不及转储,日志可以继续写入,在缓冲区内被覆盖的日志就直接丢弃了。
容器共用kernel
容器和虚拟机不一样,所有容器是共用kernel的,包括:
- 系统参数配置共享
- 进程数共享 – Fork bomb
- fd数共享
- 主机磁盘共享
容器化应用的资源监控
容器中看到的资源是主机资源:
- Top
- Java runtime.GetAvailableProcesses()
- cat /proc/cpuinfo
- cat /proc/meminfo
- df -k
原因
因为/proc文件系统并不知道用户通过cgroup给这个容器做了什么限制,所以它返回的还是整个宿主机的资源。
解决方案
查询 / proc/1/cgroup 是否包含 kubepods 关键字 (docker 关键字不可靠)。
11:cpu,cpuacct:/kubepods.slice/kubepods-besteffort.slice/kubepods-besteffort- pod521722c3_85a8 11e9 87fc 3cfdfe57c998.slice/9568ccOd8ae182395elce172e2cac 723c4781a999e89e0f9f10d33af079a56e9包含此关键字,则表明是运行在 Kubernetes 之上。
内存
- 配额
cat /sys/fs/cgroup/memory/ memory.limit_in_bytes
36854771712 - 用量
cat /sys/fs/cgroup/memory/memory.usagein bytes
448450560
CPU
- 配额,分配的 CPU个数= quota / period, quota = -1 / 代表 besteffort
- cat /sys/fs/cgroup/cpu/cpu.cfs_quota_us
-1 - cat /sys/fs/cgroup/cpu/cpu.cfs_period_us
100000
- cat /sys/fs/cgroup/cpu/cpu.cfs_quota_us
- 用量
- cat /sys/fs/cgroup/cpuacct/cpuacct.usage_percpu(按CPU区分)
140669504971 148500278385 149957919463 152786448674 - cat /sys/fs/cgroup/cpuacct/cpuacct.usage
12081100465458
- cat /sys/fs/cgroup/cpuacct/cpuacct.usage_percpu(按CPU区分)
其他方案
-
Lxcfs
不挂载主机的/proc目录,通过lxcfs来实现隔离。lxcfs在宿主机上维护进程组的信息。然后容器启动时把lxcfs维护的进程组信息所在目录挂载到容器的/proc目录,在容器中获取/proc信息时,实际上获取的是宿主机上该容器的进程信息。 -
Kata
VM 中跑 container。 -
Virtlet
直接启动VM。
对应用造成的影响
- Java
- Concurrent GC Thread:正常是看cpuinfo文件,影响应用的GC性能。
- Heap Size:默认是操作系统内存的百分比
- 线程数不可控。
- Node.js
多线程模式启动的 Thread 数量过多,导致 OOM Kill。
应用上云
pod spec
pod spec也就是pod的template中的spec,需要注意的点是:
- 初始化需求 (init container)
- 需要几个主 container
- 权限?
- Privilege
- SecurityContext(PSP)
- 共享哪些 Namespace(PID, IPC, NET, UTS, MNT)
- 配置管理
- 优雅终止
- 健康检查
- Liveness Probe
- Readiness Probe
- DNS 策略以及对 resolv.conf 的影响
- imagePullPolicy Image 拉取策略
健康检查注意:Probe误用可能会导致pid被用完。
比如一个pod的readnessprobe中定义了一个shell脚本,脚本是curl endpoint,看返回码是否正常。
但是这个脚本是跑在envoy的pod中,envoy只是一个反向代理软件,没有任何维护子进程的能力。kubelet中的probe manager发起健康检查,创建了一个新进程,然后这个进程的父进程就是容器的entrypoint,也就是envoy进程。这就导致一直在创建新的子进程,旧的子进程变成僵尸进程,而且没有被父进程回收,可能会导致pid被用完。
如何防止pid泄漏
- 单进程容器
- 多进程容器
- 容器的初始化进程必须负责清理 fork 出来的所有子进程
- 开源方案
- Tini https: //qithub.com/krallin/tini
- 采用 Tini 作为容器的初始化进程(PID=1),容器中僵尸进程的父进程会被置为1
- ENTRYPOINT ["/tini”, "–" ],CMD ["/your/program", "-and", "-its",“arguments"]
- 如果不采用特殊初始化进程
- 建议采用 HTTP get 作为 Probe
- 为 exec Probe 设置合理的超时时间
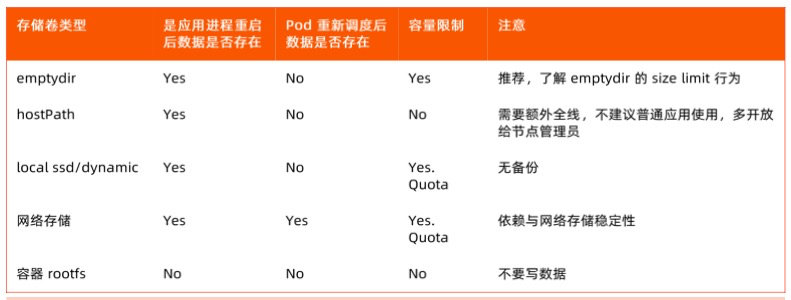
pod数据管理
每个应用实例需要多少磁盘,磁盘的IO要求,本地还是网络。
local-ssd:独占的本地磁盘,独占IO,固定大小,读写性能高。
Local-dynamic:基于 LVM,动态分配空间,效率低。
高可用部署
- 需要多少实例?
- 如何控制故障域,部署在几个可用区,region,AZ,集群?
- 如何进行精细的流量控制?看集群的算力
- 如何做按地域的顺序更新?
- 如何回滚?
- 更新策略
- MaxSurge
- MaxUnavailable(需要考虑 ResourceQuota 的限制)
- 深入理解 PodTemplateHash 导致的应用的易变性
如何应对基础架构带来的影响

pdb的介绍在这里。
服务发布
需要把服务发布至集群内部或者外部,服务的不同类型:
- ClusterlP ( Headless)
- NodePort
- LoadBalancer
- ExternalIP
证书管理和七层负载均衡的需求
需要 gRPC 负载均衡如何做?
DNS需求
与上下游服务的关系
无状态应用管理
- Replicaset 副本集
- 用什么 Pod 模版创建多少个实例。
- replicas: 3
- Deployment 部署过程
- 版本管理
annotations: deployment.kubernetes.io/revision: "1" spec: revisionHistoryLimit: 10 - 滚动升级策略
strategy: rollingUpdate: maxSurge: 25% maxUnavailable: 1 type: RollingUpdate
- 版本管理
有状态应用管理
statefulset相比deployment,多了:
serviceName: xxxx
volumeClaimTemplates:
- apiVersion: v1
kind: PersistentVolumeClaim
metadata:
creationTimestamp: null
labels:
app.kubernetes.io/instance: www
name: data
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 8Gi
storageClassName: nfs-client
volumeMode: Filesystem有状态应用现在大多都是通过Operator来管理。