背景
前面我已经将prometheus替换为了victoria-metrics,higress-console页面上的监控在部署时可以选择安装内置的,也可以对接外部监控。
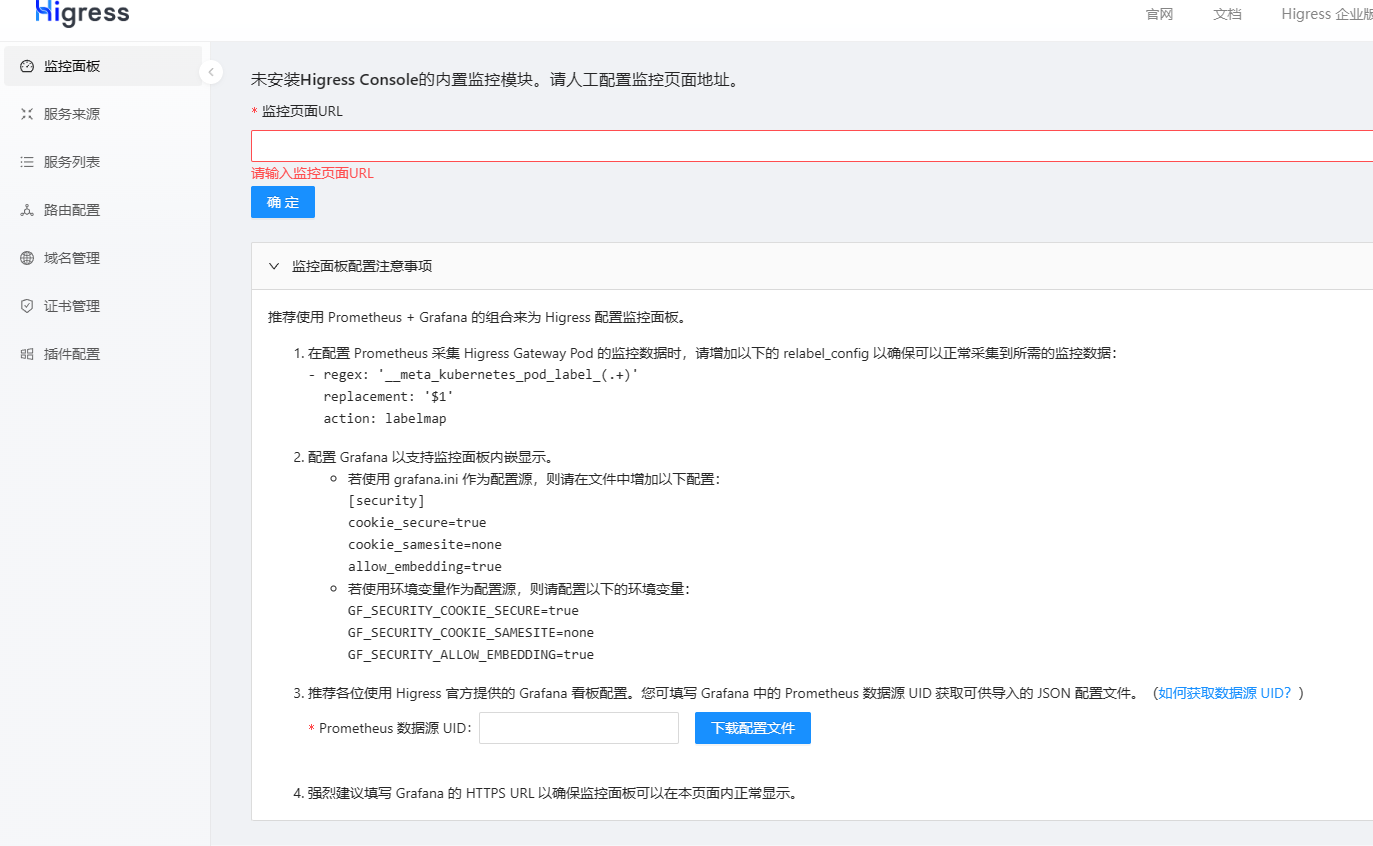
下面介绍下如何对接victoria-metrics。
步骤
配置vmagent
方法一
首先需要配置higress-gatewaypod的relabel_config。在victoria-metrics组件中,对应的是修改vmagent的配置。
查看higress-gatewaychart的values.yaml,确认监控端口和路径。
vim higress/charts/higress-core/values.yaml
podAnnotations:
prometheus.io/port: "15020"
prometheus.io/scrape: "true"
prometheus.io/path: "/stats/prometheus"
sidecar.istio.io/inject: "false"采集higress-gateway暴露的metrics,端口是15020,路径是/stats/prometheus。
修改vmagent的cmvmagent-config,添加如下job,重启pod。
k edit cm vmagent-config -n vm
- job_name: higress-gateway
honor_timestamps: true
scrape_interval: 15s
scrape_timeout: 10s
metrics_path: /metrics
scheme: http
follow_redirects: true
relabel_configs:
- source_labels: [__meta_kubernetes_namespace]
separator: ;
regex: higress-system
replacement: $1
action: keep
- source_labels: [__meta_kubernetes_pod_label_app]
separator: ;
regex: higress-gateway
replacement: $1
action: keep
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_scrape]
separator: ;
regex: "true"
replacement: $1
action: keep
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_path]
separator: ;
regex: (.+)
target_label: __metrics_path__
replacement: $1
action: replace
- source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port]
separator: ;
regex: ([^:]+)(?::\d+)?;(\d+)
target_label: __address__
replacement: $1:$2
action: replace
- separator: ;
regex: __meta_kubernetes_pod_label_(.+)
replacement: $1
action: labelmap
- source_labels: [__meta_kubernetes_namespace]
separator: ;
regex: (.*)
target_label: kubernetes_namespace
replacement: $1
action: replace
- source_labels: [__meta_kubernetes_pod_name]
separator: ;
regex: (.*)
target_label: kubernetes_pod_name
replacement: $1
action: replace
kubernetes_sd_configs:
- role: pod
kubeconfig_file: ""
follow_redirects: true
k delete po -n vm vmagent-647dc7dd79-q6stx访问vmagent页面。查看target,确认higress-gateway为up状态。

点击Debug relabeling下面的target,可以查看relabel_config是如何工作的。

方法二
我的higress版本是2.0.0,在2.0.1版本中更新了higress-gateway监控相关。
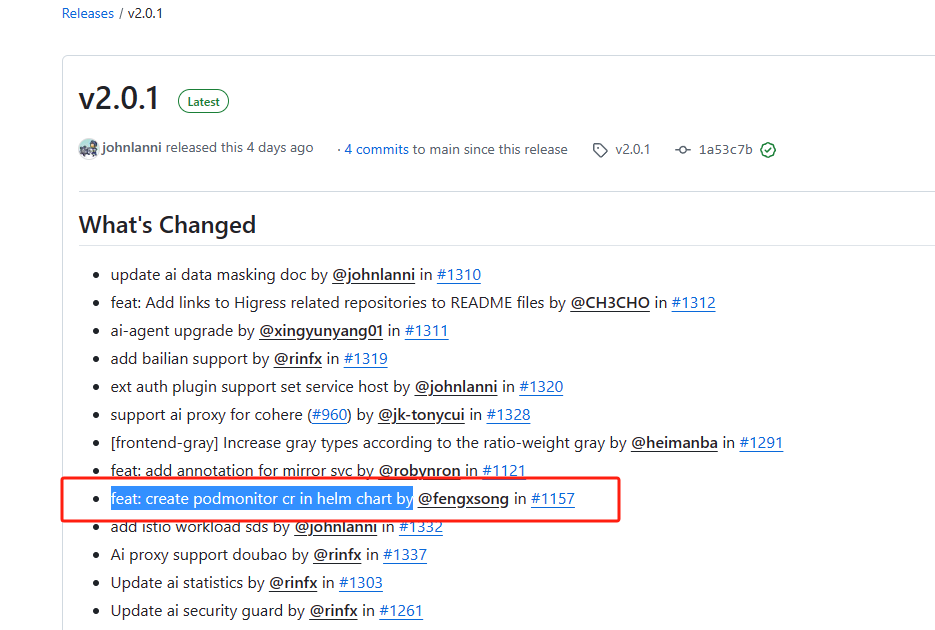
查看values.yaml
https://github.com/alibaba/higress/blob/main/helm/core/values.yaml
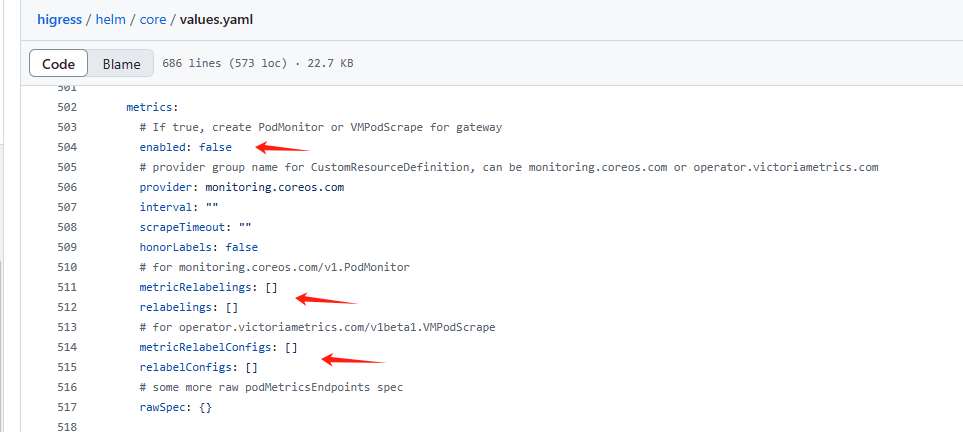
在这里配置PodMonitor或者VMPodScrape更方便,就不用去修改配置了。
配置grafana
我这里grafana是rancher上部署的,grafana.ini是以cm形式挂载到容器中的。
volumeMounts:
- mountPath: /etc/grafana/grafana.ini
name: config
subPath: grafana.ini
volumes:
- configMap:
defaultMode: 420
name: rancher-monitoring-grafana
name: config直接修改cm。
k edit cm -n cattle-monitoring-system rancher-monitoring-grafana
data:
grafana.ini: [analytics]\ncheck_for_updates = true\n[auth]\ndisable_login_form
= false\n[auth.anonymous]\nenabled = true\norg_role = Viewer\n[auth.basic]\nenabled
= false\n[dashboards]\ndefault_home_dashboard_path = /tmp/dashboards/rancher-default-home.json\n[grafana_net]\nurl
= https://grafana.net\n[log]\nmode = console\n[paths]\ndata = /var/lib/grafana/\nlogs
= /var/log/grafana\nplugins = /var/lib/grafana/plugins\nprovisioning = /etc/grafana/provisioning\n[security]\nallow_embedding
= true\ncookie_secure = true\ncookie_samesite = none\n[server]\ndomain = \n[users]\nauto_assign_org_role
= Viewer\n重启grafana。
k delete po -n cattle-monitoring-system rancher-monitoring-grafana-787946fc48-6klwf确认配置生效。
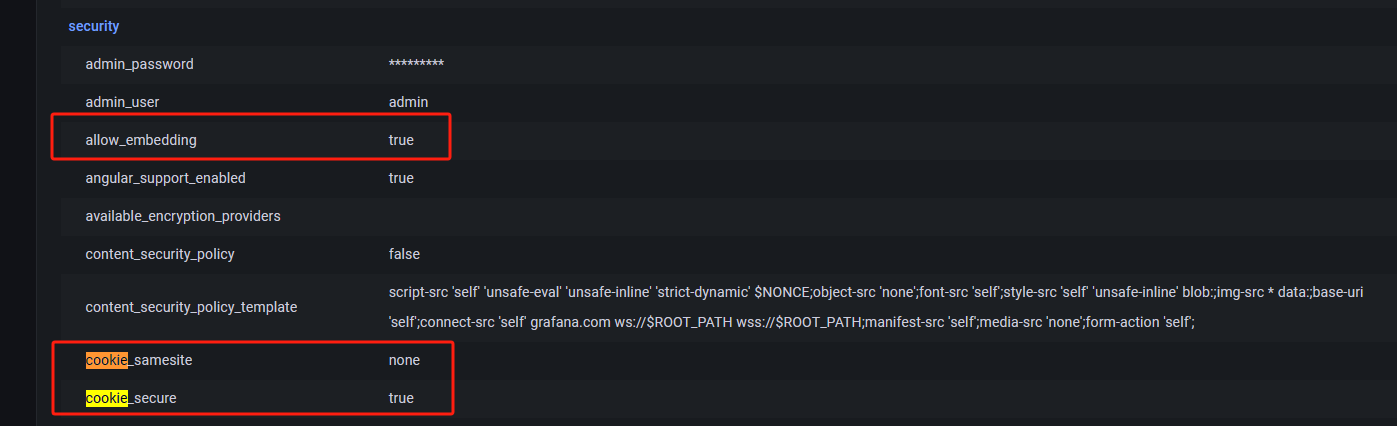
查看监控
导入模板
创建数据源。

导入模版:https://github.com/higress-group/higress-console/blob/c22a01810b362e7349bb2a8157e9f993783219a8/backend/console/src/main/resources/dashboard/main.json, 批量修改datasource为如下:
"type": "prometheus",
"uid": "victoria-metrics"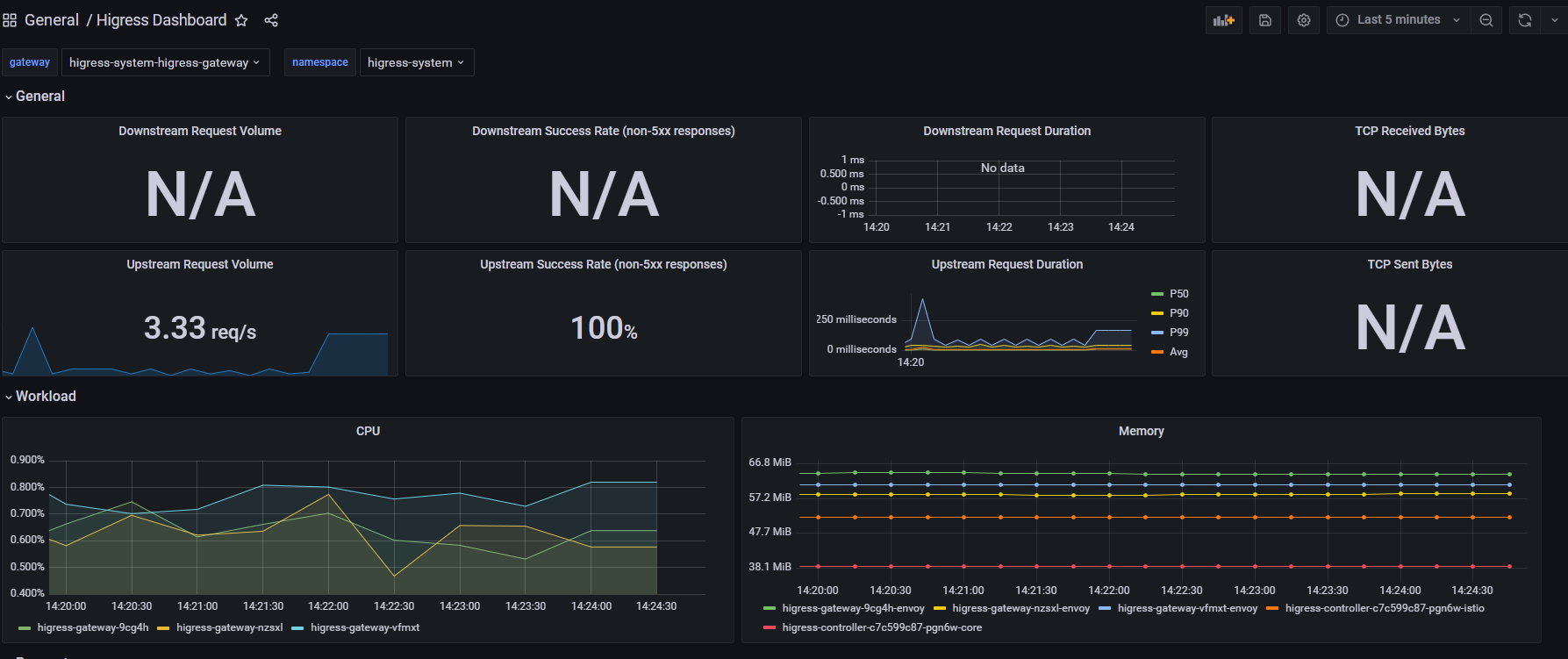
donwstream没数据是没有下行流量。
promQL解释
查看QPS的promQL是:
label_replace(label_replace(topk(10, sum(irate(envoy_cluster_upstream_rq_total{higress="higress-gateway-higress-system", cluster_name!="xds-grpc", cluster_name!="prometheus_stats", cluster_name!="agent", cluster_name!="BlackHoleCluster", cluster_name!="sds-grpc"}[5m])) by (cluster_name)), "service", "$3", "cluster_name", "outbound_([0-9]+)_(.*)_(.*)$"), "port", "$1", "cluster_name", "outbound_([0-9]+)_(.*)_(.*)$")含义如下:
-
irate(envoy_cluster_upstream_rq_total{...}[5m]):envoy_cluster_upstream_rq_total:这个指标表示Envoy集群的上游请求总数;higress="higress-gateway-higress-system", cluster_name!="...":这个部分是一个标签过滤器,表示我们只关注higress网关中某些特定的cluster_name,并且排除了一些不感兴趣的集群;irate(...[5m]):irate 函数计算了5分钟窗口内的请求速率(即请求数量的增长率),而不是使用绝对的请求总数。它能反映实时请求的变化速率。
-
sum(irate(…)) by (cluster_name):将同一个
cluster_name的所有请求速率相加,以便看到每个集群的整体流量。 -
topk(10, …):表示只保留前10个请求速率最高的集群。
-
label_replace(topk(...), "service", "$3", "cluster_name", "outbound_([0-9]+)_(.*)_(.*)$"):label_replace是Prometheus中用于创建或替换标签值的函数,它使用正则表达式匹配某个标签的值,并将其替换为新的标签。第一个标签替换,从cluster_name标签中提取出服务名称,并将其赋值给一个新的service标签。- "service":这是新标签的名字,表示服务名称。
- "$3":表示使用正则表达式匹配后,捕获的第三个部分(通常是服务名称)。
- "cluster_name":这是要从中提取信息的标签名称,即我们要从
cluster_name中提取数据。 - "outbound([0-9]+)(.)_(.)$":这是用于匹配
cluster_name标签值的正则表达式。它分为三部分:- ([0-9]+):匹配一个数字(通常是端口号)。
- (.*):匹配服务的名称部分。
- (.*):匹配剩余的部分(通常是命名空间)。
-
label_replace(..., "port", "$1", "cluster_name", "outbound_([0-9]+)_(.*)_(.*)$"):第二个标签替换,从cluster_name标签中提取出端口号,并将其赋值给一个新的port标签。- "port":这是新标签的名字,表示端口号。
- "$1":表示使用正则表达式匹配后,捕获的第一个部分(端口号)。
- "cluster_name":依然是我们要从中提取信息的标签。
- "outbound([0-9]+)(.)_(.)$":同样的正则表达式,这次我们取的是第一个捕获组 $1,即端口号部分。
综上:这个Prometheus查询最终会返回:前10个流量最高的集群(基于5分钟内的请求速率),每个集群的服务名称会保存在service标签中,每个集群的端口号会保存在port标签中。
RT的promQL为:
label_replace(label_replace(topk(10, sum(irate(envoy_cluster_upstream_rq_time_sum{higress="$gateway", cluster_name!="xds-grpc", cluster_name!="prometheus_stats", cluster_name!="agent", cluster_name!="BlackHoleCluster", cluster_name!="sds-grpc"}[5m])) by (cluster_name) / sum(irate(envoy_cluster_upstream_rq_time_count{higress="$gateway",cluster_name!="xds-grpc", cluster_name!="prometheus_stats", cluster_name!="agent", cluster_name!="BlackHoleCluster", cluster_name!="sds-grpc"}[5m])) by (cluster_name)), "service", "$3", "cluster_name", "outbound_([0-9]+)_(.*)_(.*)$"), "port", "$1", "cluster_name", "outbound_([0-9]+)_(.*)_(.*)$")返回的是前10个流量最高的集群(基于平均请求延迟),每个集群的服务名称会保存在service标签中。每个集群的端口号会保存在port标签中。